



一、面板数据特性与模型选择的核心意义
面板数据(Panel Data)作为同时包含时间维度与截面维度的三维数据结构,其最大优势在于能够控制不可观测的个体异质性,从而有效缓解遗漏变量偏误。在经济管理、社会科学、公共卫生等研究领域,面板数据已成为洞察变量间因果关系的重要载体。
当我们面对面板数据时,首先需要解决的就是模型设定问题:究竟应该选择混合回归模型、固定效应模型还是随机效应模型? 这个选择绝非随意,而是基于数据特征、研究设计和理论假设的综合判断。错误的选择可能导致估计结果严重偏误,甚至得出完全相反的结论。
面板数据的双重维度赋予了研究更多的信息量:
- 时间维度:追踪同一主体随时间的变化规律
- 截面维度:比较不同主体在同一时点的差异特征
而三种核心模型正是基于对这种双重维度信息的不同利用方式而发展起来的。
二、三大模型的本质区别与理论内核
2.1 混合回归模型(POOL):假设的简化之美
混合回归是最为基础的面板数据分析方法,其核心思想是完全忽略面板数据的个体效应与时间效应,将所有数据混合在一起进行普通最小二乘估计。
模型设定:
Yit=α+βXit+εit
混合回归隐含着一个强假设:所有个体拥有相同的截距项,即个体间不存在系统性差异。这一假设在现实研究中往往难以成立,特别是在个体异质性较为明显的情况下。
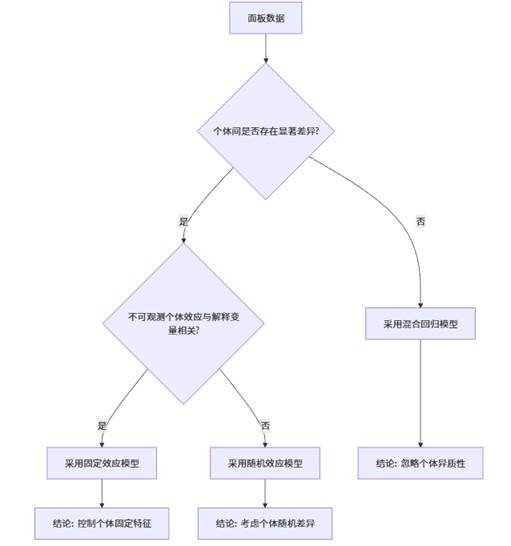
三种模型选择的基本逻辑路径。混合回归适用于最为理想的情况,固定效应与随机效应的选择则取决于不可观测个体效应与解释变量的相关性假设。
2.2 固定效应模型(FE):控制个体内在特质的利器
固定效应模型通过允许每个个体拥有独特的截距项,从而有效控制不随时间变化的个体特征。
模型设定:
Yit=αi+βXit+εit
固定效应模型的核心优势在于其能够缓解由于遗漏变量导致的偏误问题,特别是当这些遗漏变量与模型中的解释变量相关时。通过组内离差变换(within transformation),固定效应模型有效地消除了个体特异性的影响。
应用场景:
- 研究企业绩效影响因素时,控制企业固有的管理风格、企业文化等
- 分析地区经济发展时,控制地理位置、资源禀赋等固定特征
- 探讨个人收入决定因素时,控制先天能力、家庭背景等不变特质
2.3 随机效应模型(RE):效率与一致性的平衡艺术
随机效应模型将个体效应视为随机变量,而非固定参数,其基本假设是个体效应与模型中的解释变量不相关。
模型设定:
Yit=α+βXit+ui+εit
随机效应模型通过广义最小二乘法进行估计,其效率优势在于能够同时利用组内变异与组间变异,当个体效应与解释变量确实无关时,随机效应估计量比固定效应估计量更为有效。
三、模型选择的统计检验框架
理论思考需要统计检验的支撑,面板模型选择遵循着严谨的检验流程。
3.1 F检验:混合回归vs固定效应
F检验主要用于判断固定效应是否必要,即检验所有个体的截距项是否相等。
原假设:所有个体拥有相同的截距项(混合回归更合适)
备择假设:个体截距项存在显著差异(固定效应更合适)
在SPSSAU分析中,此项检验通常输出在固定效应模型结果下方,当p值小于0.05时,拒绝原假设,选择固定效应模型优于混合回归。
3.2 LM检验:混合回归vs随机效应
拉格朗日乘数检验用于判断随机效应是否必要,检验个体随机效应的方差是否为零。
原假设:随机效应的方差为零(混合回归更合适)
备择假设:随机效应的方差显著不为零(随机效应更合适)
SPSSAU平台提供Breusch-Pagan LM检验结果,当p值小于显著性水平时,表明随机效应模型优于混合回归。
3.3 Hausman检验:固定效应vs随机效应
Hausman检验是面板模型选择中最为关键的检验,其核心在于判断个体效应与解释变量是否相关。
原假设:个体效应与解释变量不相关(随机效应更合适)
备择假设:个体效应与解释变量相关(固定效应更合适)
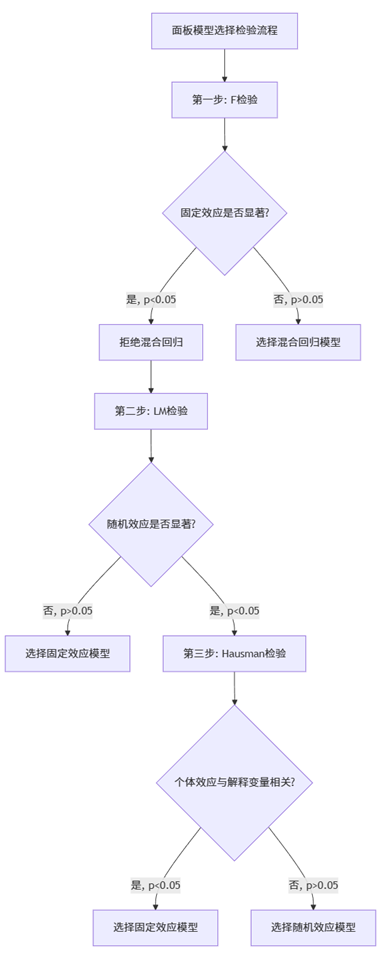
Hausman检验的统计原理基于比较固定效应与随机效应估计量的一致性。当原假设成立时,两种估计量都是一致的,但随机效应更有效;当备择假设成立时,只有固定效应估计量保持一致。
四、SPSSAU平台上的实操演示
现代统计分析平台如SPSSAU极大地简化了面板模型选择的复杂性,使研究者能够专注于结果解读与理论分析。
4.1 数据准备与模型设定
在SPSSAU中进行分析时,首先需要正确设置面板数据结构:
- 确保数据包含个体标识变量与时间标识变量
- 将因变量与自变量分别选入对应框内
- 系统自动识别面板数据结构
SPSSAU界面设计直观,即使对面板数据不太熟悉的研究者也能快速上手。平台提供了清晰的操作指引和实时帮助信息,降低了技术门槛。操作示例图如下:
4.2 模型检验结果深度解析

(1)F检验结果:F(8,86)=54.748, p=0.000
这一结果表明,固定效应模型显著优于混合模型。检验统计量远大于临界值,p值远小于0.05,强烈拒绝"所有个体截距相同"的原假设。这意味着各省份之间存在显著的个体异质性,忽略这些不可观测的个体特征将导致估计偏误。
(2)BP检验结果:χ²(1)=155.600, p=0.000
Breusch-Pagan检验同样显示强烈显著性,表明随机效应模型优于混合模型。个体随机效应的方差显著不为零,进一步证实了个体异质性的存在。
(3)Hausman检验结果:χ²(3)=-71.995, p=1.000
Hausman检验出现负值在理论上可能源于方差协方差矩阵非正定,但SPSSAU对此进行了稳健处理。p值为1.000表明接受原假设,即个体效应与解释变量不相关,随机效应模型是一致的、有效的估计量。
3.3 三类模型估计结果对比分析
下表详细展示三种模型的估计结果:
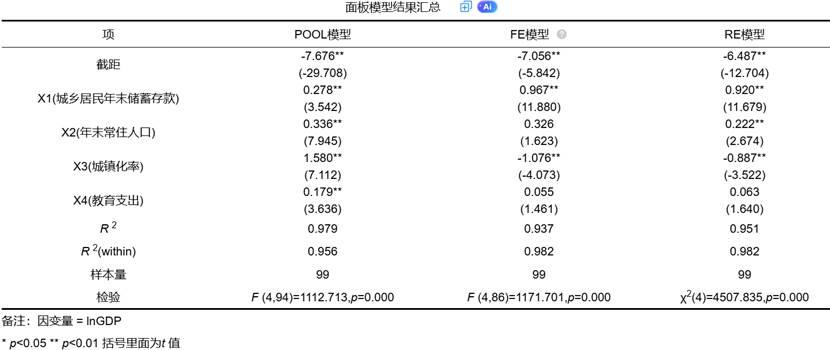
模型间差异的经济学解释:
储蓄存款(X1)的影响:在混合模型中,储蓄的系数为0.278,而在FE和RE模型中分别上升至0.967和0.920。这表明混合模型严重低估了储蓄对经济增长的贡献,原因在于其忽略了个体效应与储蓄变量的相关性。
城镇化率(X3)的符号逆转:这是一个极其重要的发现。混合模型中城镇化系数为正1.580,而考虑个体效应后转为负值。这可能的解释是:城镇化水平较高的省份可能同时具有其他未观测的有利特征,混合模型错误地将这些特征的效果归因于城镇化。当控制个体固定效应后,城镇化的真实效应显现为负,可能与城镇化过程中的拥挤成本、环境压力等有关。
人口与教育支出的显著性变化:在固定效应模型中,人口和教育支出变得不显著,说明这些变量的影响可能主要通过跨省份的差异体现,而非省份内部的时间序列变化。
4.4 最终模型选择与经济解释
基于检验结果,选择随机效应模型作为最终模型具有理论和实证双重依据:
统计依据:Hausman检验支持RE模型的一致性,且RE模型的拟合优度(R²=0.951)介于POOL和FE之间,组内R²(0.982)与FE模型相同,表明模型拟合良好。
经济学依据:省级行政区可以视为从中国总体中随机抽样的个体,其不可观测的特征(如地理条件、文化传统等)与解释变量的相关性较弱,满足随机效应模型的基本假设。
RE模型的经济解释:
- 储蓄存款每增加1%,GDP增长约0.92%,表明资本积累仍是经济增长的重要动力
- 人口规模效应显著但相对较小(0.222),反映人口红利逐渐减弱
- 城镇化率的负效应(-0.887)值得政策关注,提示需要注重城镇化质量而非单纯追求城镇化率
- 教育支出不显著可能源于教育投入的长期性和外部性,短期内直接经济回报不明显
五、面板模型选择的进阶问题与处理策略
5.1 非平衡面板数据的处理
实际研究中经常遇到非平衡面板数据,即不同个体的时间观测期不同。SPSSAU能够自动识别非平衡数据结构并采用适当的方法进行处理,确保估计的有效性。
5.2 异方差和序列相关的稳健推断
面板数据中常常存在异方差和序列相关问题。SPSSAU提供稳健标准误选项,即使在违背经典假设的情况下也能获得有效的统计推断。
5.3 动态面板模型与内生性问题
当解释变量包含被解释变量的滞后项或存在内生性问题时,需要采用动态面板模型(如GMM估计)。SPSSAU支持多种GMM估计方法,有效处理内生性偏误。

















 2914
2914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









