




一、模型介绍
llama 3.1 是 Meta 公司推出的一款功能强大的大型语言模型。具有以下特性:
- 强大的处理能力 :在处理复杂语言任务上表现出色,无论是一般知识问答、多语种翻译、逻辑推理,还是数学运算、代码生成等专业领域任务,都有优秀的表现。例如,它可以准确地进行复杂的数学计算,为用户提供准确的数学问题解答;在代码生成方面,能够根据用户的需求生成高质量的代码。
- 长文本处理能力提升 :所有三个版本的模型都将上下文长度提升到了 128k,这意味着它可以更好地处理长格式文本,对于需要理解长篇文章、书籍等内容并进行分析和回答的任务,具有更强的应对能力,能够从长篇文本中获取更多信息,以做出更明智的决策,并生成更加准确和详细的回应3。
- 语言支持广泛 :支持多种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语等,在多语种自然语言处理方面表现突出,能够无缝转换不同语种,为跨语言交流提供了便利。
二、模型构建
1.环境构建
- 创建虚拟环境
conda create -n llama python=3.12
conda activate llama
- 进入文件
cd llama3.1
- 下载依赖
pip install -r requirements.txt

requirements.txt文件
#requirements.txt文件
fastapi==0.111.1
uvicorn==0.30.3
modelscope==1.16.1
transformers==4.42.4
accelerate==0.32.1
torch==2.3.0
2.下载模型
- 运行以下代码
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/sj-tmp/', revision='master')

- 使用以下代码,设置UI页面
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## LLAMA3.1")
"llm"
# 创建一个标题和一个副标题
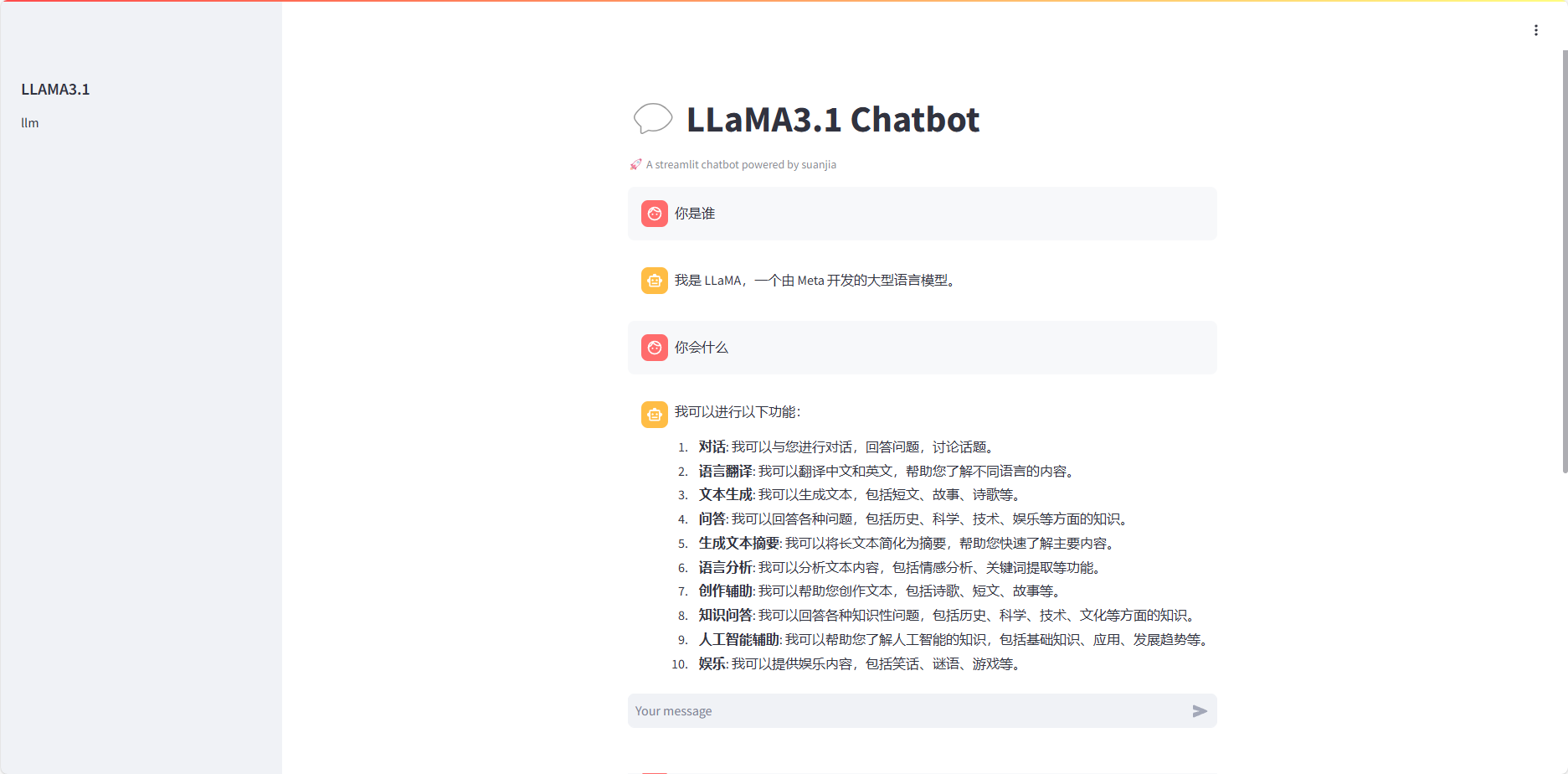
st.title("💬 LLaMA3.1 Chatbot")
st.caption("🚀 A streamlit chatbot powered by suanjia")
# 定义模型路径
mode_name_or_path = '/root/sj-tmp/LLM-Research/Meta-Llama-3___1-8B-Instruct/'
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
# 加载LLaMA3的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 将对话输入模型,获得返回
input_ids = tokenizer.apply_chat_template(st.session_state["messages"],tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 将模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
print(st.session_state)
- 启动页面
streamlit run demo.py --server.address 0.0.0.0 --server.port 8080



















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









