




昨天小编已经为大家分享了DeepSeek-VL2的部署教程。今天将为大家带来DeepSeek-R1蒸馏模型——DeepSeek-R1-Distill-Qwen-7B。
可能有小伙伴不是很清楚,什么是蒸馏模型?
机器学习(ML)中的模型蒸馏是一种将知识从大型复杂模型转移到小型简单模型的技术。目标是创建一个较小的模型,保留较大模型的大部分性能,同时在计算资源、内存使用和推理速度方面更高效、部署更容易。这对于在资源受限的环境中部署模型特别有用。
DeepSeek-R1-Distill-Qwen-7B的性能如何呢?
如果说DeepSeek-R1的推理能力跟OpenAI-o1正式版差不多,那么经过蒸馏,能在本地运行的小模型DeepSeek-R1-Distill-Qwen-7B,其推理能力就跟OpenAI-O1-mini 近似。
今天咱们就来看看如何在自己的电脑上部署DeepSeek-VL2模型,极速体验最新对话技术!小编为大家提供了本地部署教程,快跟着试一试吧!
部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息1 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.4.105 |
| Python | 3.12 |
| NVIDIA Corporation | RTX 4090 |
1. 更新基础软件包
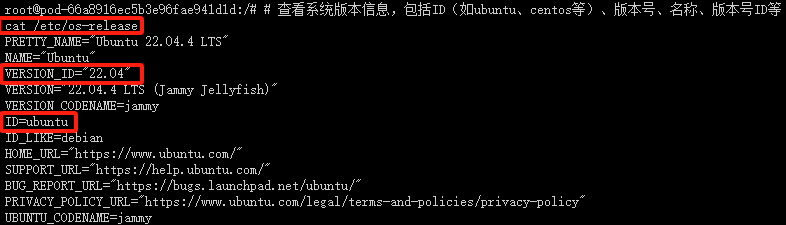
查看系统版本信息
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置 apt 国内源
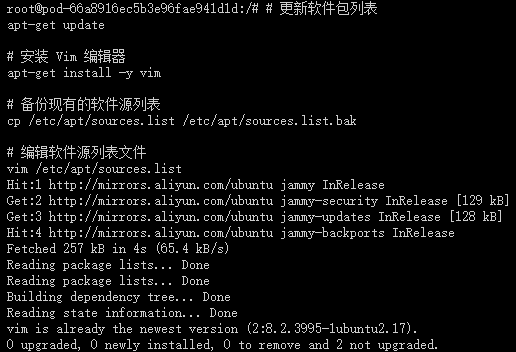
# 更新软件包列表
apt-get update
这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
# 安装 Vim 编辑器
apt-get install -y vim
这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为“是”,这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak
这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
# 编辑软件源列表文件
vim /etc/apt/sources.list
这个命令使用 Vim 编辑器打开 sources.list 文件,以便您可以编辑它。这个文件包含了 APT(Advanced Package Tool)用于安装和更新软件包的软件源列表。通过编辑这个文件,您可以添加新的软件源、更改现有软件源的优先级或禁用某些软件源。
在 Vim 中,您可以使用方向键来移动光标,i 键进入插入模式(可以开始编辑文本),Esc 键退出插入模式,:wq 命令保存更改并退出 Vim,或 :q! 命令不保存更改并退出 Vim。
编辑 sources.list 文件时,请确保您了解自己在做什么,特别是如果您正在添加新的软件源。错误的源可能会导致软件包安装失败或系统安全问题。如果您不确定,最好先搜索并找到可靠的源信息,或者咨询有经验的 Linux 用户。
使用 Vim 编辑器打开 sources.list 文件,复制以下代码替换 sources.list</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









