




代码点这里
1.自编码器(Autoencoder)
自编码器的介绍可以点击这里。
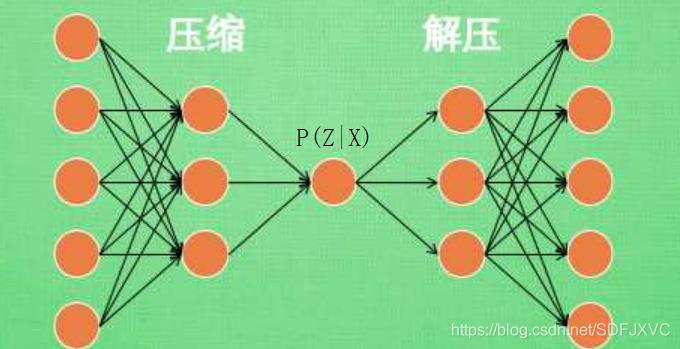
自编码器包含两部分:编码器与解码器。
编码器相当于把数据压缩,解码器相当于将数据解压。
编码就是数据降维,解码就是升维,之前的神经网络与卷积网络都叙述过,不再赘诉。
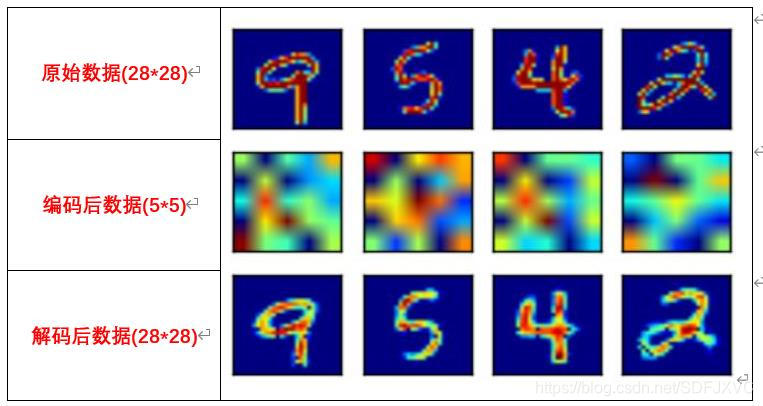
2.去噪自编码(Denoising AE)
去噪自编码与自编码器类似,都是编码与解码的过程。
只是去噪自编码中原始数据是具有噪声的,通过去噪自编码器后,可以将数据中的噪声去除。
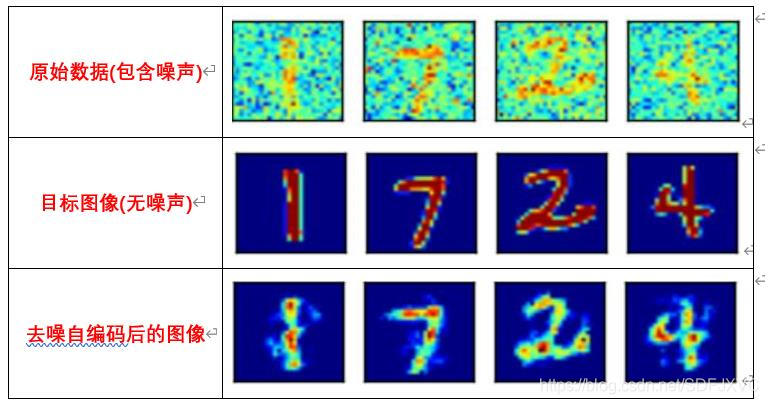
3.变分自编码器(VAE)
3.1VAE是什么
自编码是将图片编码再解码还原,而VAE的作用是求出编码后的P(Z|X)的分布,这样我们就可以用P(Z|X)来生成我们想要的数据。
简单来说,之前自编码是:
(
X
1
,
X
2
,
X
3
,
.
.
.
.
X
n
)
→
(
Z
1
,
Z
2
,
Z
3
,
.
.
.
Z
n
)
(X_1,X_2,X_3,....X_n)\to(Z_1,Z_2,Z_3,...Z_n)
(X1,X2,X3,....Xn)→(Z1,Z2,Z3,...Zn)
而VAE则是:
(
X
1
,
X
2
,
X
3
,
.
.
.
.
X
n
)
→
P
(
Z
∣
X
)
(X_1,X_2,X_3,....X_n)\to P(Z|X)
(X1,X2,X3,....Xn)→P(Z∣X)
这样我们就不需要每次存储
(
Z
1
,
Z
2
,
Z
3
,
.
.
.
Z
n
)
(Z_1,Z_2,Z_3,...Z_n)
(Z1,Z2,Z3,...Zn)了,只需要知道他们的分布就可以了!
举个栗子:
(1)
(
X
1
,
X
2
,
X
3
,
.
.
.
.
X
n
)
→
(
1
,
2
,
3
,
.
.
.
n
)
(X_1,X_2,X_3,....X_n)\to(1,2,3,...n)
(X1,X2,X3,....Xn)→(1,2,3,...n)
(2)
(
X
1
,
X
2
,
X
3
,
.
.
.
.
X
n
)
→
(
P
(
Z
∣
X
)
=
i
)
,
0
<
i
≤
n
(X_1,X_2,X_3,....X_n)\to(P(Z|X) = i),0< i\leq n
(X1,X2,X3,....Xn)→(P(Z∣X)=i),0<i≤n
明显(2)比(1)的方式要好!
3.2相关公式:
(1)朴素贝叶斯:
P
(
A
∩
B
)
=
P
(
B
∣
A
)
∗
P
(
A
)
=
P
(
A
∣
B
)
∗
P
(
B
)
P(A\cap B) = P(B|A)*P(A)=P(A|B)*P(B)
P(A∩B)=P(B∣A)∗P(A)=P(A∣B)∗P(B)
(2)KL散度 :
K
L
(
P
∣
∣
Q
)
=
∑
P
(
x
)
∗
l
o
g
P
(
x
)
Q
(
x
)
KL(P||Q)=\sum P(x)*log\frac{P(x)}{Q(x)}
KL(P∣∣Q)=∑P(x)∗logQ(x)P(x)
(3)正态分布:
N
(
μ
,
σ
2
)
=
1
2
π
σ
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
N(\mu,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2})
N(μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
(4)
K
L
(
N
(
μ
,
σ
2
)
∣
∣
N
(
0
,
1
)
)
:
KL\Big(N(\mu,\sigma^2)||N(0,1)\Big):
KL(N(μ,σ2)∣∣N(0,1)):

推导过程摘自变分自编码器(一):原来是这么一回事
3.3推导过程
(1) P ( Z ∣ X ) = P ( X ∣ Z ) ∗ P ( Z ) P ( X ) P(Z|X)=\frac{P(X|Z)*P(Z)}{P(X)} P(Z∣X)=P(X)P(X∣Z)∗P(Z)
(2) 假设存在一个 Q = Q ( Z ∣ X ) Q=Q(Z|X) Q=Q(Z∣X)与 P = P ( Z ∣ X ) P=P(Z|X) P=P(Z∣X)近似,则他们的KL散度是:
K
L
(
Q
∣
∣
P
)
=
∑
Q
∗
l
o
g
Q
P
=
∑
Q
∗
l
o
g
Q
∗
P
(
X
)
P
(
X
∣
Z
)
∗
P
(
Z
)
=
∑
Q
∗
l
o
g
Q
P
(
X
∣
Z
)
+
∫
(
Q
∗
l
o
g
P
(
X
)
−
Q
∗
l
o
g
P
(
Z
)
)
d
z
=
K
L
(
Q
∣
∣
P
(
Z
)
)
−
∫
Q
∗
l
o
g
P
(
X
∣
Z
)
d
z
+
l
o
g
P
(
X
)
\begin{aligned} KL\big(Q||P\big) &=\sum Q*log\frac{Q}{P}\\ & =\sum Q*log\frac{Q*P(X)}{P(X|Z)*P(Z)}\\ &= \sum Q*log\frac{Q}{P(X|Z)}+\int (Q*logP(X)-Q*logP(Z))dz\\ &=KL(Q||P(Z)) - \int Q*logP(X|Z)dz+logP(X)\\ \end{aligned}
KL(Q∣∣P)=∑Q∗logPQ=∑Q∗logP(X∣Z)∗P(Z)Q∗P(X)=∑Q∗logP(X∣Z)Q+∫(Q∗logP(X)−Q∗logP(Z))dz=KL(Q∣∣P(Z))−∫Q∗logP(X∣Z)dz+logP(X)
其中
∫
Q
∗
l
o
g
P
(
X
)
d
z
=
l
o
g
P
(
X
)
\int Q*logP(X)dz =logP(X)
∫Q∗logP(X)dz=logP(X),是个常数。
要
使
Q
与
P
近
似
→
K
L
(
Q
∣
∣
P
)
要
尽
量
小
要使Q与P近似\to KL(Q||P)要尽量小
要使Q与P近似→KL(Q∣∣P)要尽量小
→
K
L
(
Q
∣
∣
P
(
Z
)
)
−
∫
Q
∗
l
o
g
P
(
X
∣
Z
)
d
z
尽
量
小
。
\to KL(Q||P(Z))-\int Q*logP(X|Z)dz尽量小。
→KL(Q∣∣P(Z))−∫Q∗logP(X∣Z)dz尽量小。
(3)假设:
①
Q
(
Z
∣
X
)
=
N
(
μ
,
σ
2
)
①Q(Z|X) =N(\mu,\sigma^2)
①Q(Z∣X)=N(μ,σ2)
②
P
(
Z
)
②P(Z)
②P(Z)是一个单位多元正态分布
N
(
0
,
I
)
N(0,I)
N(0,I)。
关于多元正态分布点击多元高斯分布。
结合上面相关公式(4),得出以下结果:
K
L
(
N
(
μ
,
σ
2
)
∣
∣
P
(
Z
)
)
=
1
2
∗
∑
i
(
−
l
o
g
σ
i
2
−
1
+
μ
2
+
σ
i
2
)
KL\big(N(\mu,\sigma^2)||P(Z)\big) = \frac{1}{2}*\sum_i(-log\sigma_i^2-1+\mu^2+\sigma_i^2)
KL(N(μ,σ2)∣∣P(Z))=21∗i∑(−logσi2−1+μ2+σi2)
#KL散度
#logvar是方差的对数
KLD = 0.5*tf.reduce_sum(tf.pow(mu, 2) + tf.exp(logvar) - 1 - logvar,1)
(4)重参数化技巧(Reparameterization Trick)
从上面的过程,我们知道了要训练
K
L
(
Q
∣
∣
P
)
KL\big(Q||P\big)
KL(Q∣∣P),就需要计算
Q
(
Z
∣
X
)
=
N
(
μ
,
σ
2
)
Q(Z|X) =N(\mu,\sigma^2)
Q(Z∣X)=N(μ,σ2),见下图:
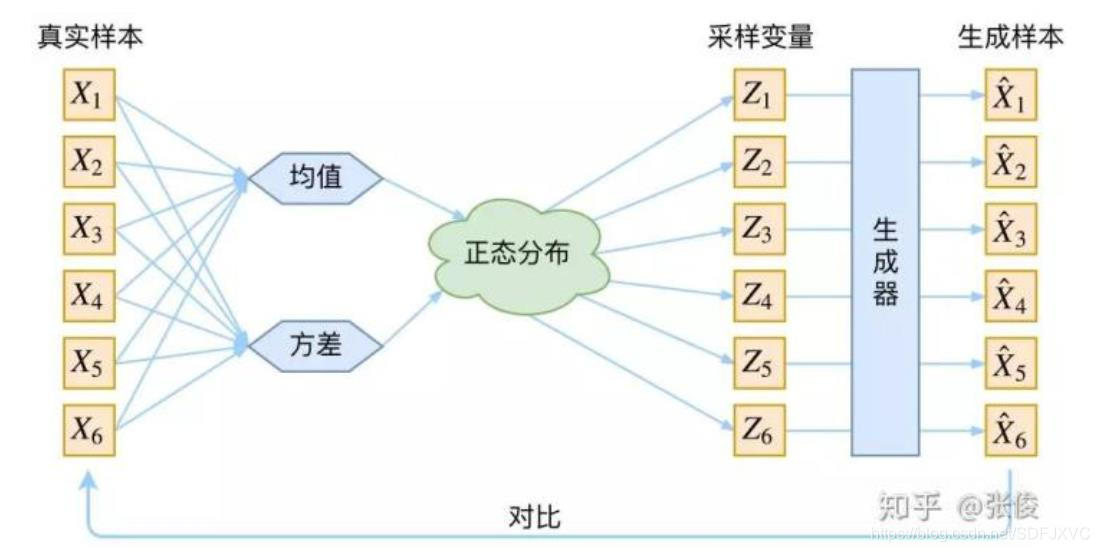
图片转载自变分自编码器VAE:原来是这么一回事。
但是
μ
与
σ
\mu与\sigma
μ与σ是无法进行梯度计算的,所以我们就用到重参数化技巧:
如果非标准正态分布
X
∼
N
(
μ
,
σ
2
)
X\sim N(μ,σ^2)
X∼N(μ,σ2),那么关于
X
X
X的一个一次函数
Y
=
(
X
−
μ
)
/
σ
Y = (X-μ)/σ
Y=(X−μ)/σ,就一定是服从标准正态分布
N
(
0
,
1
)
。
N(0,1)。
N(0,1)。证明详见:普通正态分布如何转换到标准正态分布。
所以我们可以将
P
(
Z
∣
X
)
∼
N
(
μ
,
σ
2
)
P(Z|X)\sim N(\mu,\sigma^2)
P(Z∣X)∼N(μ,σ2)写成
P
(
Z
∣
X
)
∼
μ
+
N
(
0
,
1
)
∗
σ
P(Z|X)\sim \mu+N(0,1)*\sigma
P(Z∣X)∼μ+N(0,1)∗σ
def sample_z(mu,log_var):
#标准正态分布
eps = tf.random_normal(shape=tf.shape(mu))
#返回Z的分布,log_var是方差的对数
return mu + tf.exp(log_var / 2) * eps
(5)解码
通过将图片编码后得到了 P ( Z ∣ X ) ∼ μ + N ( 0 , 1 ) ∗ σ P(Z|X)\sim \mu+N(0,1)*\sigma P(Z∣X)∼μ+N(0,1)∗σ,这样我们就可以通过解码得到 P ( X ∣ Z ) P(X|Z) P(X∣Z),即将图像进行了还原,所以需要重构损失,计算还原后的图像与原图像的损失:
#重构损失,比较还原的图像与原图像的损失
BCE = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=X),1)
4.条件变分自编码器(CVAE)
CVAE只是在VAE的基础上将图像的标签添加到网络中,结构如图:
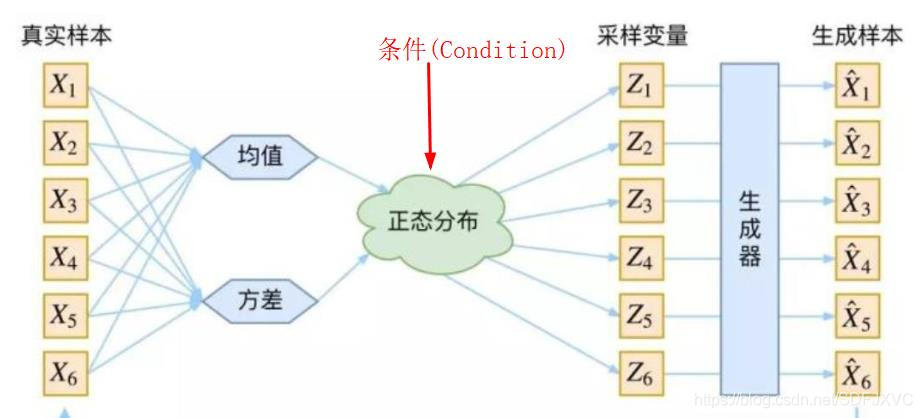
#计算Z
def sample_z(mu,log_var):
#标准正态分布
eps = tf.random_normal(shape=tf.shape(mu))
#Z的分布
return mu + tf.exp(log_var / 2) * eps
#获取Z的分布
z = sample_z(mu,logvar)
#将标签加入Z中
z_c = tf.concat([z,Y],1)

















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









