 手写实现R语言逻辑回归LogisticRegression
手写实现R语言逻辑回归LogisticRegression





 本文介绍了如何在R语言中手动实现逻辑回归。通过读取数据、可视化和使用R内置的glm函数进行预分析,然后详细阐述了自定义逻辑回归的步骤,包括定义交叉熵损失函数、计算梯度、预测概率、迭代过程,并最终分析模型效果。
本文介绍了如何在R语言中手动实现逻辑回归。通过读取数据、可视化和使用R内置的glm函数进行预分析,然后详细阐述了自定义逻辑回归的步骤,包括定义交叉熵损失函数、计算梯度、预测概率、迭代过程,并最终分析模型效果。
1.读取数据
[数据来源:https://en.wikipedia.org/wiki/Logistic_regression]
rm(list=ls())
setwd("C:\\Users\\xiaokang\\Desktop\\课程\\博一下学期\\广义线性模型\\")
data=read.csv("Simulation\\dataset\\LogisticRegression\\exam_pass.csv")
print(data)
#这里我发现了Rmarkdown的一个警告,因为我在这里修改了默认的工作路径,
#但是 Rmarkdown提醒了我:我的工作路径已经改变了
可以看到该数据集只有20个样本;其中Hours表示学生考试复习用的时间;Pass=1表示学生通过考试;Pass=0表示学生并没有通过考试。
2.可视化
library(ggplot2)
ggplot(data=data,aes(x=Hours,y=Pass))+geom_point()
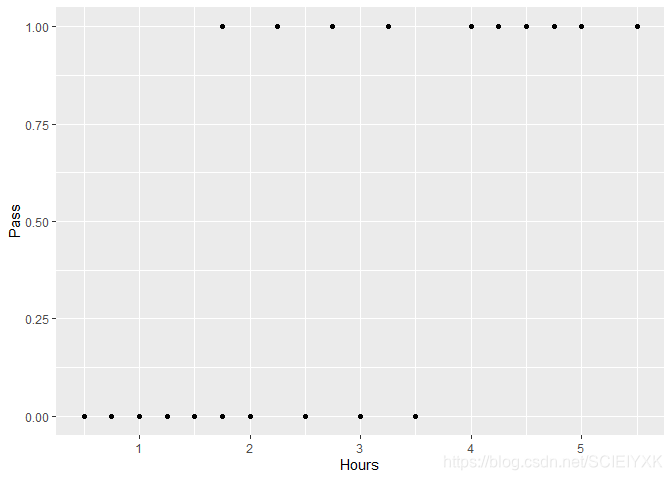
可以看到,只有一个变量HoursHoursHours,那么如果判别函数是线性函数,即分类平面等价于Hours=cHours=cHours=c,当Hours<cHours<cHours<c时,判定为考试不合格,当Hours>cHours>cHours>c时,判定为不合格,从图像上看,此数据显然是线性不可分的数据集,例如存在一个Hours=1.75Hours=1.75Hours=1.75,但该学生考试及格了,但是又有比他用的时间多的点考试不合格。所以建立的LogisticRegression的准确率肯定不能达到100%
3.使用R自带的glm函数拟合logisticRegression
library(stats)
data=as.data.frame(data)
y.glm=glm(Pass~Hours,family=binomial(link="logit"),data=data)
print(summary(y.glm))
print(y.glm$fitted.values)
print(predict(y.glm))
pred_val=y.glm$fitted.values>0.5
sprintf("一共预测正确了%d个样本",sum(pred_val==data$Pass))
print("预测错误的Hours为:");print(data$Hours[pred_val!=data$Pass])
# 分别是第 7, 9,12,14
可以看到和维基百科上拟合的效果完全一致,其中得到的判定函数为p(Y=1∣Hours)=e−4.0777+1.5046Hours1+e−4.0777+1.5046Hours=11+e4.0777−1.5046Hoursp(Y=1|Hours)=\frac{e^{-4.0777+1.5046Hours}}{1+e^{-4.0777+1.5046 Hours}}=\frac{1}{1+e^{4.0777-1.5046Hours}}p(Y=1∣Hours)=1+e−4.0777+1.5046Hours
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









