






以下的创作来源依旧是这篇文章呀!
零基础入门深度学习(4) - 卷积神经网络_0基础学卷积神经网络-优快云博客
放个传送门在这里:小白学习machine learning的第一天-优快云博客
小白学习machine learning的第二天-优快云博客
小白学习machine learning的第三天-优快云博客
小白学习machine learning的第四天-优快云博客
小白学习machine learning的第五天-优快云博客
小白学习machine learning的第六天-优快云博客
那么,西部延时O(∩_∩)O,我们进入正题!
一、循环神经网络RNN小小介绍一下
(1)首先,使用循环神经网络而非前面所学习的网络 ——> 需要处理序列相关数据,即相邻输入数据间都存在着相应的关系。
(2)接下来,我们来看看以下几种循环神经网络:
①基本循环神经网络
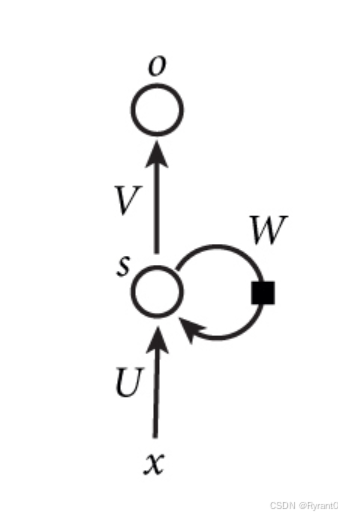
x:输入向量
U:输入层到隐藏层的权重矩阵
V:隐藏层到输出层的权重矩阵
s:向量,代表隐藏层的值
W:隐藏层上次的值计算作为这次值的权重矩阵
展开可以得到下面这张图呀!
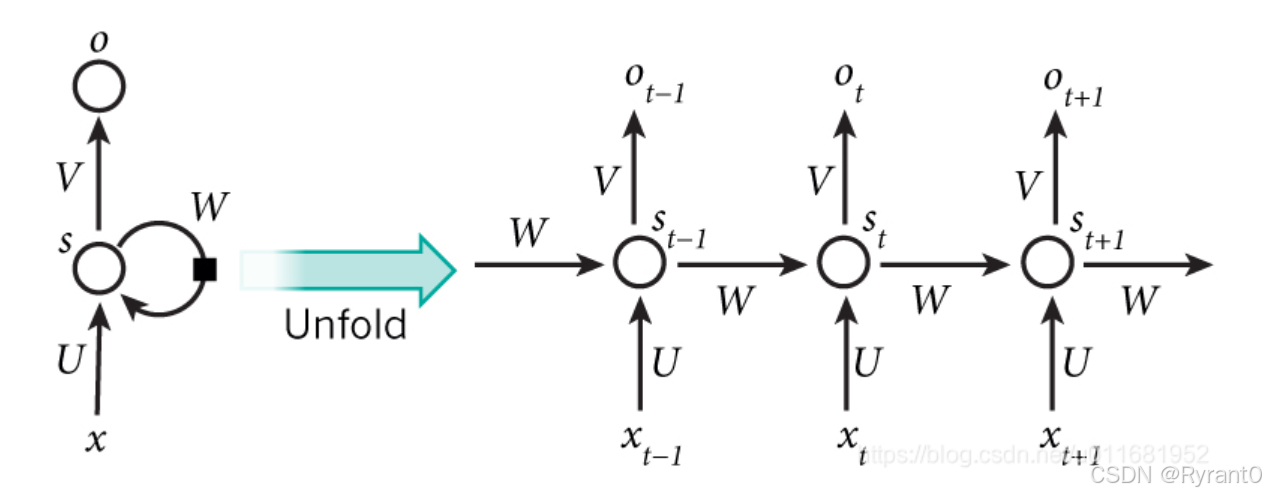
那么,依据图形解释,我们可以推出简单的公式:
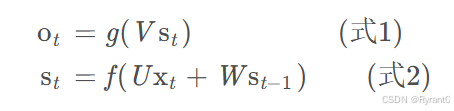
而循环网络在如下这张图应该看的更清楚(其实就是反复带入反复循环):
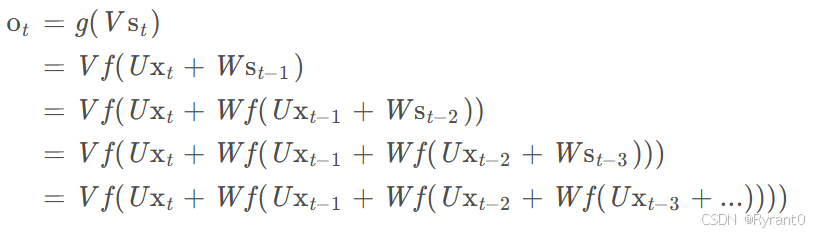
式1是输出层的公式,是全连接层,每个节点都和隐藏层相连!
式2是隐藏层之间的公式,它是循环层。
f,g是激活函数哦!
②双向循环神经网络
(1)这里原文给出了很形象的例子,这里作者同样采用呀!
eg. 我的手机坏了,我打算____一部新手机。
对于语言模型来说,只是循环前置内容,“手机坏了”然后是“伤心”“维修”还是其他?但是看后面
”新手机“我们知道空格补”买“。由此,我们引入双向循环神经网络。
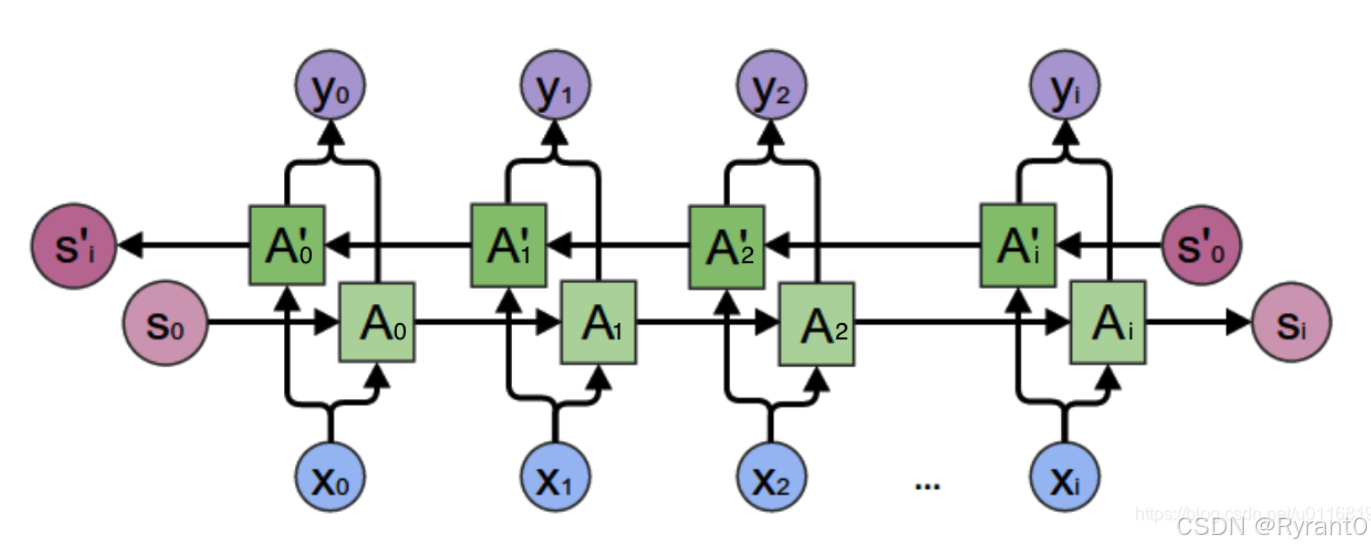
由图所表示,隐藏层有2个值需要保存并使用,一个A参与正向计算,另一个值A’参与反向计算。
公式如下:
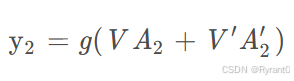
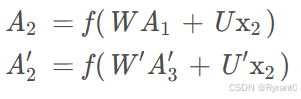
那么,总的双向循环神经网络的计算公式如下:
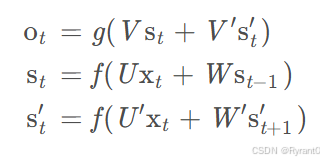
A2计算中,W和U是计算输入层和循环隐藏层中的值的权重矩阵。
计算出A2和A2'(st和st')之后,可以分别再乘上不同的权重矩阵V和V'从而计算出y2(ot)输出层的值呀!
其中,我们需要注意的是正向计算和反向计算并不共享权重矩阵哦~~~
③深度循环神经网络
定义一下:实际上,只要有2个隐藏层以上的循环神经网络就称得上“深度”了。
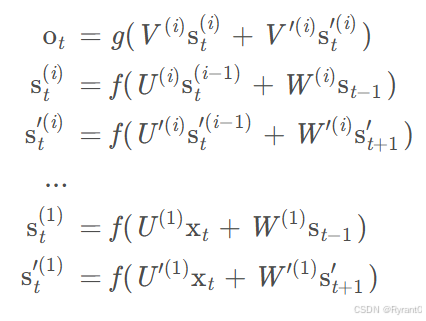
其中,(i)代表隐藏层的记号啦。
二、循环神经网络该咋训练?
那么,这里我们采用BPTT算法来进行训练,而这种算法与BP算法亦有共通之处。
来浅浅看一下步骤吧:
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项δj值,它是误差函数E对神经元j的加权输入netj的偏导数;
- 计算每个权重的梯度。
4.再用随机梯度下降算法更新权重。
(1)前向计算
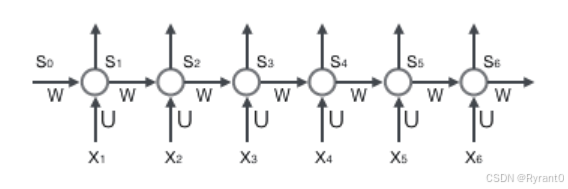
根据图像,我们给出公式:
![]()
换成逼格更高,指代数据更明确的公式:
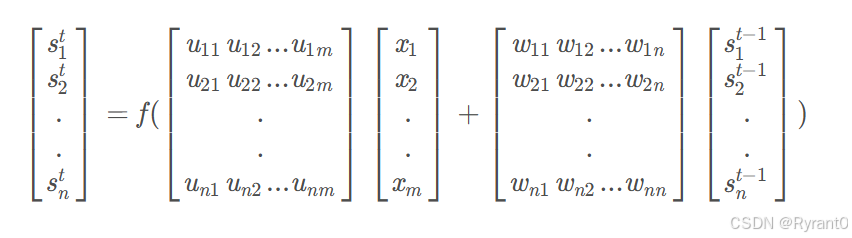
注意:1.下标表示它是这个向量的第几个元素,它的上标表示第几个时刻。
2.Uji表示输入层第i个神经元到循环层第j个神经元的权重。Wji表示循环层第t−1时刻的第i个神经元到循环层第t个时刻的第j个神经元的权重哦!
(2)误差项的计算
误差项在原文中用求偏导得到,这里不在赘述啦,直接给出公式:
①将误差项沿时间反向传播:

②将误差项反向传递到上一层:
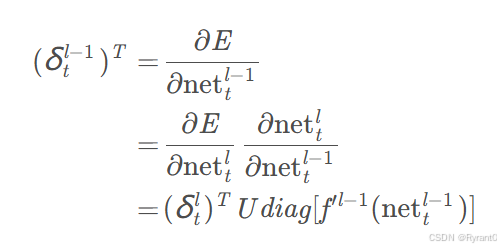
(3)权重梯度的计算
上公式咯: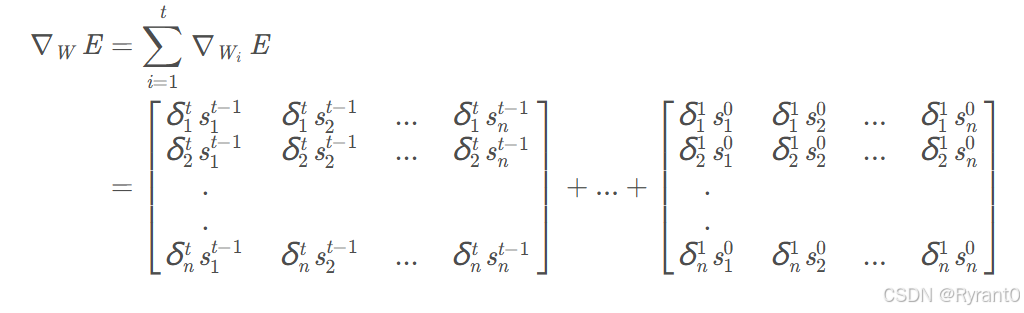
这就是循环层权重矩阵W的梯度啦!
笔者突然想到吴恩达老师在训练模型是给出的“工具”:正则化和training set、Cross-validation的使用。
相似的是,权重矩阵U的计算公式在这:
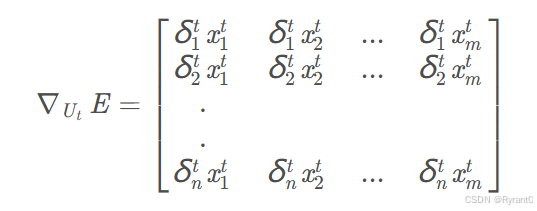
那么,把各个时刻的U加起来就是权重矩阵U的计算公式:
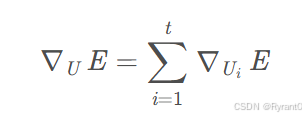
(4)RNN的梯度爆炸和梯度消失
①原因:并不能很好的处理长序列数据。在t - k很大的时候,即向前看很远(长序列一定会遇到的情况),那么就会遇到误差项增长或者缩小非常快的情况,即梯度爆炸和梯度消失。
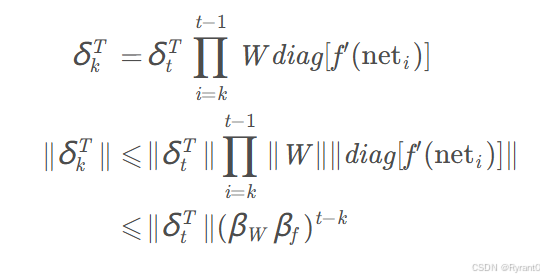 .
.
②解决办法:
1.首先,针对梯度爆炸,就只要设置一个梯度阈值即可,在梯度过快增长到达后直接截停。
2.其次,原文中对于梯度消失采用如下三种办法:
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。(这里原文中无介绍,需要自行寻找资料)
三、例子——基于RNN的语言模型
(1)向量化
①为了把语言模型的word让神经网络读得懂,要把它们转成向量的形式。
②创建一个词典,用n维独热编码的形式:
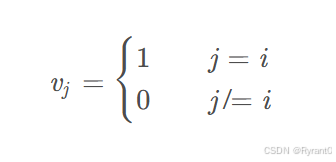
然后,我们用图像来演示一下:是不是明了很多了呢O(∩_∩)O
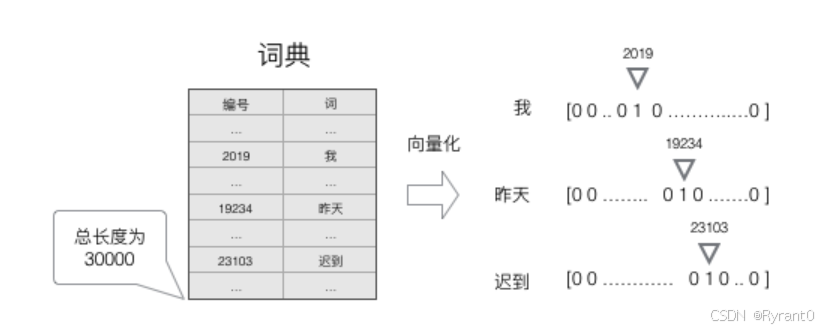
③这里,运用”词典“找到最有可能出现在空格里的词:
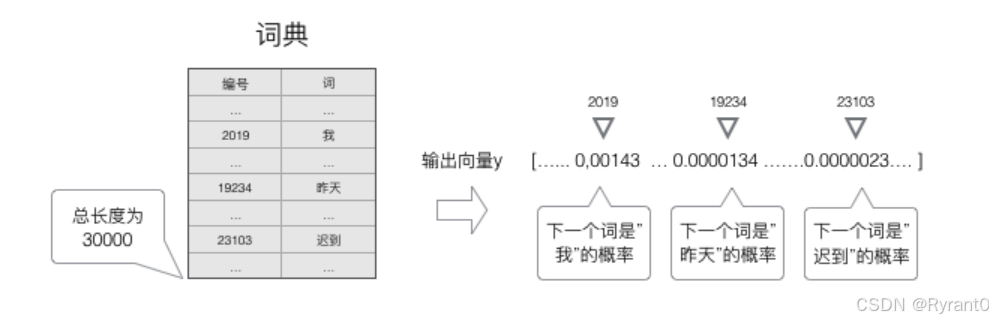
注意的是,向量化方法,我们就得到了一个高维、稀疏的向量(稀疏是指绝大部分元素的值都是0)。处理这样的向量会导致我们的神经网络有很多的参数,带来庞大的计算量。因此,往往会需要使用一些降维方法,将高维的稀疏向量转变为低维的稠密向量。(这里参考原文原句哦)
(2)softmax层
①为什么要用softmax层?为了作为神经网络的输出层输出预测词的概率。
②图示来啦!
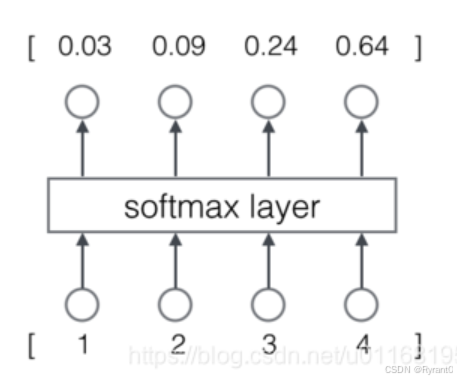
通过这个公式: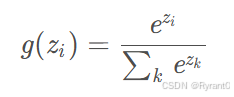 输入的向量数据在softmax层转化成了”概率“输出呢。
输入的向量数据在softmax层转化成了”概率“输出呢。
你问为什么是概率?因为
- 每一项为取值为0-1之间的正数;
- 所有项的总和是1。
而这些特征与概率“不谋而合”呀!
(3)语言模型的训练 & 交叉熵误差
这里,我们的损失函数E采用交叉熵误差:
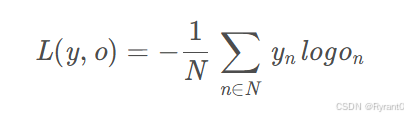
原文给了一个计算栗子:
N是训练样本的个数,向量是样本的标记,向量是网络的输出。标记是一个one-hot向量,例如y 1 = [ 1 , 0 , 0 , 0 ] ,如果网络的输出o=[0.03,0.09,0.24,0.64],那么计算过程如下:
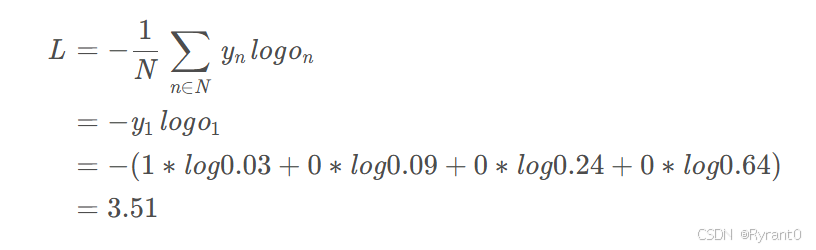
那么,我们下次再见啦!!!!!!

















 1810
1810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









