




算法交流群:174495261
每周五篇博客:(1/5)
定义
按照深度优先搜索(DFS)的访问顺序对树节点进行排序,即得到树的dfs序
性质
在dfs序中,每个节点及其整个子树的节点的dfs序是一段数值连续的编号
例如下图中,红色数字表示每个节点的dfs序编号
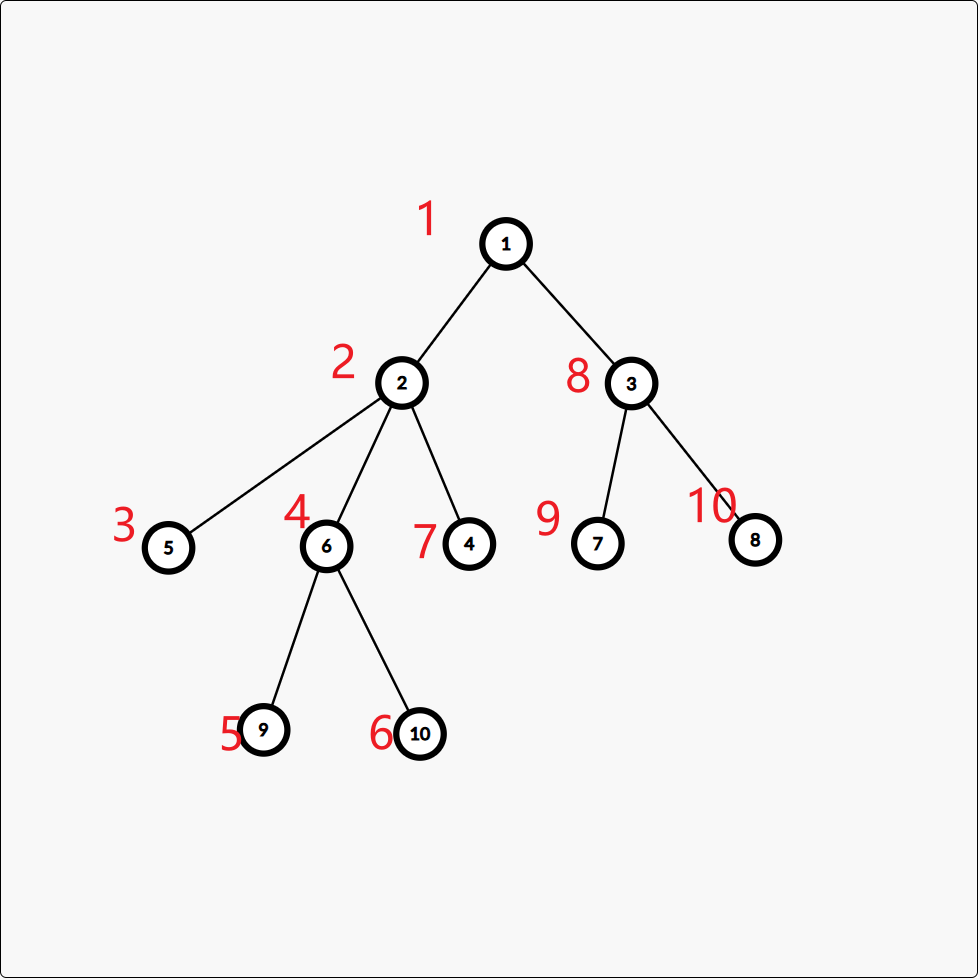
以 222 子树为例,其子树包含节点 {2,4,5,6,9,10}\{2, 4, 5 ,6, 9, 10\}{2,4,5,6,9,10} ,在dfs序的编号中,其dfs序的编号区间为 [2,6][2,6][2,6]
更近一步地,我们可以对每个节点维护两个值——在DFS中每个阶段的进入时间(第一次访问该节点的计数)与退出时间(遍历完以该节点为根的子树中的最后一个节点的计数),在这里我用两个数组 lu,rul_u, r_ulu,ru 分别表示节点 uuu 的进入时间和退出时间
例如上图中的树,引入 lu,rul_u, r_ulu,ru 数组后,我们用红色数字表示 lul_ulu ,用蓝色数字表示 rur_uru 。可以得到
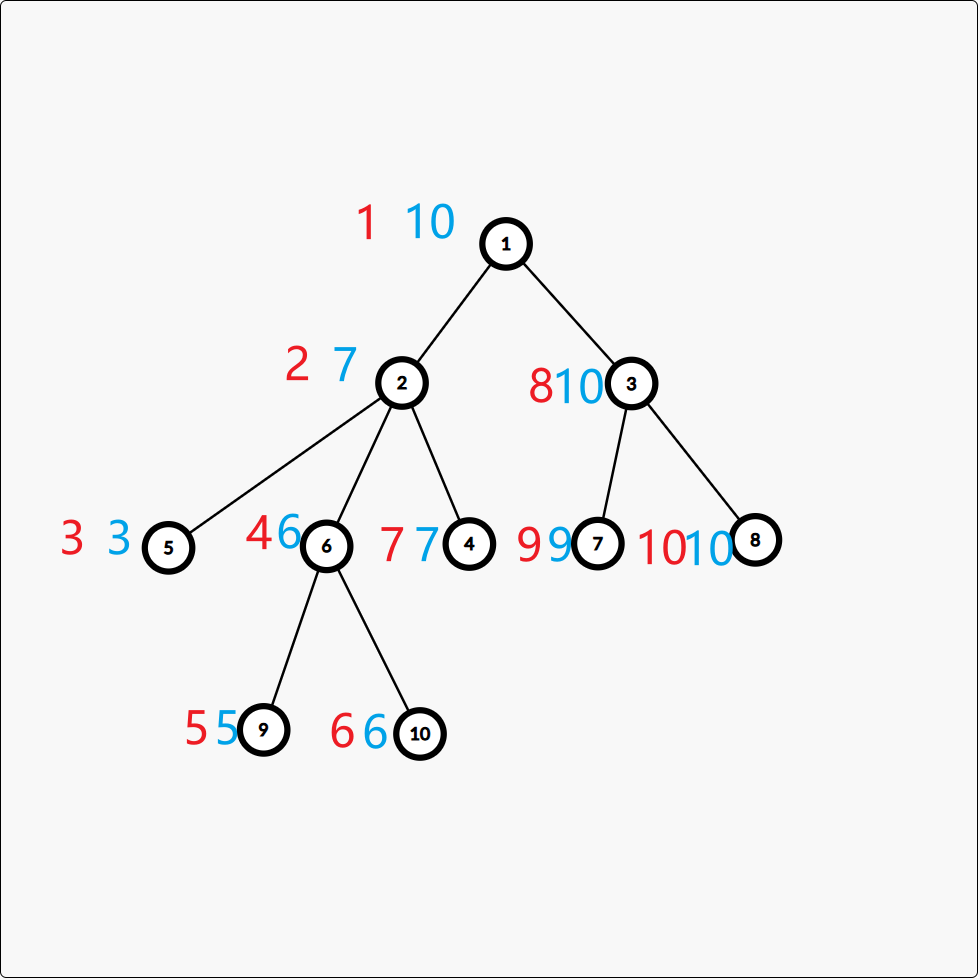
同时 lul_ulu 实际上就是我们最开始定义的dfs序,只不过加上 rur_uru 后我们可以快速知道节点 uuu 为根的子树中包含了哪些节点的dfs序编号
为了维护dfs序与节点的映射关系,所以我们还可以在定义一个数组 idiid_iidi 表示dfs序编号为 iii 对应着树中的哪个节点,例如上图中 id3=5,id8=3id_3 = 5,id_8 = 3id3=5,id8=3 ,换句话说 idlu=uid_{l_u} = uidlu=u (也可以从函数/反函数的角度理解)
注意dfs序并不是唯一的,根据dfs顺序的不同,每个节点所对应的编号也会不同。如果题目中需要保证唯一的话,那么我们可以增加一些约束条件(例如强制要求dfs时优先遍历编号更小的节点)来实现唯一性
应用
- 点 uuu 为根的子树中包含了dfs序处于区间 [lu,ru][l_u, r_u][lu,ru] 的节点
- 判断点 vvv 是否是 uuu为根的子树中的节点:如果满足 lu≤lvl_u \le l_vlu≤lv 并且 ru≥lvr_u \ge l_vru≥lv ,那么点 vvv 是 uuu为根的子树中的节点,否则不是
更进一步地,我们可以配合一些数据结构来实现对树上节点信息的维护
举个简单的例子,如果我们想要让以 uuu 为根的子树上的所有节点的权值加一
如果暴力维护的话时间复杂度会来到单次 O(n)O(n)O(n) 的级别。而区间修改我们有一个很常见的数据结构——线段树,但是线段树只能维护连续区间的信息
结合我们子树内dfs序连续的性质,我们可以用线段树根据dfs序维护信息。如果我们想让 uuu 为根的子树所有节点权值加一,那么只需要用线段树让区间 [lu,ru][l_u, r_u][lu,ru] 加一就可以了。因为线段树是维护的dfs序的权值,如果一开始每个节点都有一个初试权值,那么在初始化线段树时我们应该让线段树的第 iii 个叶子节点对应着原权值数组中的第 idiid_iidi 个节点,或者我们干脆直接用线段树操作 nnn 次让 [lu,lu][l_u, l_u][lu,lu] 区间加上节点权值也是可以的
再进一步地讲,如果我们还想让 u,vu, vu,v 两点在树上的简单路径中的每个节点权值加一,那么我们可以配合上树链剖分进行实现,不过本文就到此为止,关于树链剖分部分在不久的未来也许会写一篇博客
代码
std::vector<int> go[N];
int l[N], r[N], tot, id[N];
void dfs(int u, int fa) {
l[u] = ++ tot;
id[tot] = u;
for (auto v : go[u]) {
if (v == fa) continue;
dfs(v, u);
}
r[u] = tot;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









