




 循环智能与华为云共同推出盘古,这是目前最大的中文语言模型,针对企业级应用设计。在CLUE评测中表现出色,刷新记录。盘古在小样本学习、微调和融入行业知识方面有显著创新,解决GPT-3等模型在企业落地的难题。此外,盘古已应用于销售服务提升、精准销售和合规质检,助力企业提升效率和降低风险。
循环智能与华为云共同推出盘古,这是目前最大的中文语言模型,针对企业级应用设计。在CLUE评测中表现出色,刷新记录。盘古在小样本学习、微调和融入行业知识方面有显著创新,解决GPT-3等模型在企业落地的难题。此外,盘古已应用于销售服务提升、精准销售和合规质检,助力企业提升效率和降低风险。
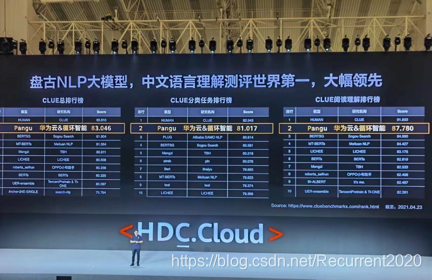
4月25日,循环智能(Recurrent AI)与华为云联合推出千亿参数、40TB训练数据的全球最大中文语言预训练模型“盘古”,鹏城实验室提供算力支持。在权威的中文语言理解评测基准CLUE榜单中,总成绩及阅读理解、分类任务单项均排名第一,刷新三项榜单纪录,总成绩得分83;在NLPCC2018文本摘要任务中,取得了Rouge平均分0.53的业界最佳成绩,超越第二名百分之六十。
“跟以往的大规模预训练模型不同,盘古模型从第一天起就是奔着商业化落地和企业级应用的角度进行设计和研发的。”循环智能(Recurrent AI)联合创始人杨植麟博士表示,“作为一个深耕 NLP 企业服务的团队,我们看到了 GPT-3 等大规模预训练模型的潜力,但也看到了它们在落地过程中的局限。盘古NLP大模型正是为了克服这些局限而生。”
三大创新,瞄准NLP大模型落地难题
在NLP大模型的企业级落地应用中,GPT-3等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









