



这篇文章是关于什么的?
- 本文讨论了传统检索增强生成 (RAG) 模型在企业环境中的局限性。
- 它强调了对更先进的代理 RAG 系统的需求,该系统可以执行迭代推理并处理复杂的多部分查询。
- 本文介绍了代理 RAG 系统擅长的各种企业用例,例如:
- 灵活汇总大量文本数据
- 为旅游公司提供智能行程规划
- 为投资公司提供结构化数据分析,例如文本到 SQL
- 项目管理的多步骤推理和规划
为什么要读这篇文章?
- 您将了解传统检索增强生成 (RAG) 模型的主要局限性,这些局限性使得它们不足以处理复杂的企业用例。
- 您将了解代理 RAG 系统如何通过迭代推理、多数据源集成和多部分任务分解等功能克服这些限制。
- 您将深入了解 agentic RAG 在各个行业的实际应用:
- 如何实现对大量文档进行灵活的、上下文感知的摘要
- 它如何帮助旅游公司制定智能、多约束的旅行计划
- 它如何促进复杂的文本到 SQL 转换以进行投资分析
- 您将会意识到 agentic RAG 能够帮助企业更有效地解决现实世界中的细微问题,从而释放出巨大的商业价值。
- 您将能够评估采用 agentic RAG 是否是您的企业推动创新和解决复杂领域挑战的正确战略举措。
总的来说,我希望通过阅读本文,您能够全面了解 agentic RAG 的强大功能及其改变企业解决问题方式的潜力。
什么是 RAG?
RAG 的形式非常简单,它涉及选择适当的数据(来自公司内部存储)来回答问题,并将其提供给大型语言模型 (LLM)。随后,LLM 可以分析数据并生成响应。
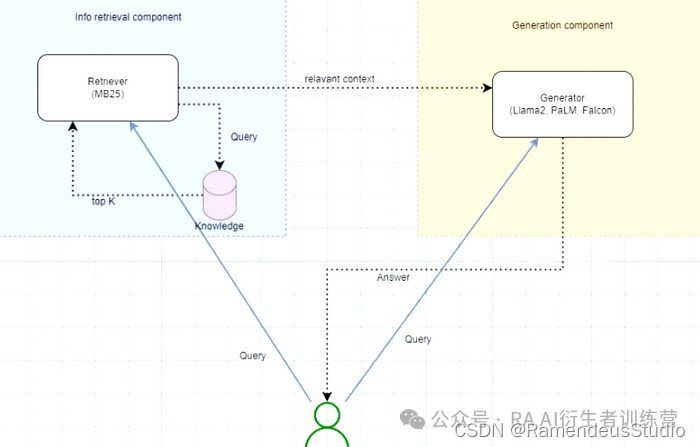
为什么我们首先需要 RAG?
常规检索增强生成 (RAG) 模型的开发是结合大型语言模型和信息检索系统优势的第一步。
数字数据的爆炸式增长意味着,如果能够有效地映射和连接到相关查询,就可以利用大量的文本语料库。RAG 模型首先根据给定的查询或提示从广泛的集合中检索最相关的文档或段落,然后允许语言模型通过引用和推理这些检索到的文本来生成内容,从而实现这一点。这使得 RAG 模型不仅仅是检索和排名段落,而是根据检索到的信息实际生成流畅的语言输出。
因此,RAG 通过利用广泛的数据存储库,在查询回答、摘要、分析和写作辅助等领域开辟了新领域。虽然 RAG 是一项早期创新,但它在处理更复杂、迭代和多部分查询方面的局限性很快就显现出来,这为更先进的范例(如代理 RAG)铺平了道路,以便更稳健地处理现实世界的用例。
为什么当前的常规 RAG 不足以满足企业设置的需求
常规 RAG 模型非常有限。它们只能根据初始查询检索一些最重要的信息。但在许多企业情况下,初始查询只是一个开始。需要更多信息和背景信息才能完全理解和解决问题。
常规 RAG 无法迭代地询问更多细节、组合来自多个来源的信息或执行多步骤流程和规划。它只会获取一些相关信息,然后就此打住。但企业要处理复杂的场景,需要将问题分解为子任务,通过来回交换收集缺失的上下文,调用外部工具和数据源,最后将所有内容拼接成完整的解决方案计划。常规 RAG 缺乏这些对于实际企业用例至关重要的迭代推理能力。
让我们了解一下,为什么企业采用 Agentic RAG?
企业正在转向代理 RAG(检索增强生成),因为常规 RAG 模型对于企业面临的复杂的现实场景来说太有限了。
Agentic RAG 允许 AI 系统进行迭代推理——理解完整的背景,通过来回对话收集缺失信息,根据需要调用外部数据源和 API,并以细致入微和量身定制的方式将解决核心问题的多部分解决方案拼接在一起。
这种迭代推理能力对于企业以现实世界、情境感知的方式处理跨领域的复杂用例(如旅行规划、投资分析、法律推理和项目管理)至关重要。这就是为什么许多企业采用代理 RAG 而不是僵硬的常规 RAG。让我们来探索一些。
为了适应和发展,企业需要迭代推理
虽然不是完全相关,但阅读后可以理解概念
Current RAG 提供什么
现有的 RAG 模型在迭代推理方面存在困难,迭代推理是指理解问题、检索相关信息、评估该信息是否充分,然后根据需要迭代优化搜索或检索过程的能力。RAG 模型只是根据初始查询检索语义上最相似的信息,而没有更深入地了解该信息是否真正解决了核心问题或查询。

企业需要什么
考虑旅游业:想象一下你使用一些“ABC Travel Co.”的服务,需要计划一次家庭度假,然后你问他们的 RAG 模型:“欧洲有哪些不错的家庭度假目的地?” RAG 模型会检索讨论巴黎、罗马、巴塞罗那等热门欧洲旅游景点的文档或段落。但是,它并不能真正理解你的处境和限制——也许你有年幼的孩子,或者你正在寻找一个负担得起的目的地,或者你想在旺季避开拥挤的城市。
如果没有迭代推理,RAG 模型就无法基于这一附加背景来优化其检索。它只会返回有关欧洲目的地的一般信息,而不是根据您的家庭具体需求定制检索。
Agentic RAG 如何解决这个问题
另一方面,Agentic RAG 则具有进行迭代推理的能力。在最初的广泛检索之后,它可以分析结果,意识到需要更多背景信息,并提出后续问题,例如“您有几个孩子,他们多大?”或“您这次旅行的最高预算是多少?”根据您的回答,Agentic RAG 可以指导更精细的检索过程,获取与您的特定情况相匹配的适合家庭、注重预算的目的地信息。

这种检索、分析、收集更多上下文,并根据添加的上下文重新检索的迭代循环是 Agentic RAG 的一个关键优势。它允许模型真正理解查询的细微差别,迭代地构建相关上下文,并提供精确定制以满足用户需求的检索结果,而不仅仅是基于与初始广泛查询的语义相似性。
企业需要灵活的汇总
当今的企业处理许多领域的大量文本数据,如法律文件、研究论文、新闻文章、产品评论等。能够以灵活、情境感知的方式自动汇总这些数据至关重要。
常规 RAG 的局限性
传统的检索增强生成 (RAG) 模型采用文本输入,检索相关文档,并仅根据前 k 个检索到的文档生成输出摘要。但是,这种前 k 个方法对于现实世界的摘要需求有几个缺点:
- 它无法整合不在 top-k 中的文档的相关信息。
- 摘要长度由生成模型的训练固定决定。
- 它无法通过结合跨文档的信息来执行多文档摘要。
- 缺乏根据特定观点或信息需求进行总结的能力。
Agentic RAG 如何解决这个问题
代理 RAG 方法允许 AI 系统以更灵活、更迭代的方式对检索到的整套文档进行推理以进行总结:
- 访问完整的文档内容:代理可以使用工具访问所有检索到的文档的全部文本,而不仅仅是 top-k。
- 长度/信息控制:可以指示代理根据需要生成更长或更短的摘要,其中包含更多或更少的具体信息。
- 多文档融合:通过阅读所有文档,代理可以合成一个结合要点的连贯摘要,llm 可以在这里采用各种 chucking 策略,甚至采用多模型、迭代推理。
- 基于观点/查询的总结:给定特定的查询、立场或信息需求,代理可以相应地定制其总结。

例如,一家律师事务所可能需要从各种报告和证词中获取多文档案件证据摘要,重点关注特定法律问题,并针对不同场景定制不同长度。代理 RAG 系统可以灵活地通过阅读所有文档、整合信息并根据公司需求编写自定义摘要来提供此类摘要。随着企业努力应对不断增长的文本数据,这种级别的摘要能力至关重要。
投资公司等企业需要结构分析
数据驱动的投资分析需要从大量非结构化文本数据(如财务报告、分析师笔记、新闻文章等)中提取结构化见解。一项关键任务是将这些非结构化文本映射到结构化数据库查询(文本到 SQL),以支持分析和决策。
常规 RAG 的局限性
传统的 RAG 模型难以实现稳健的文本到 SQL 所需的迭代、上下文相关推理:
- 他们孤立地看待文本查询,而不了解更广泛的分析背景和目标。
- 它们根据初始文本一次性生成 SQL 查询,但无法进行改进或修改。
- 它们缺乏处理涉及多种条件、聚合等的复杂查询的灵活性。
- 它们无法集成外部数据源或无缝处理特定领域的约定。
Agentic RAG 如何解决这个问题
代理 RAG 方法为投资公司解锁了更智能、迭代的文本到 SQL 功能:
- 任务理解:代理可以进行对话,首先了解更广泛的分析背景和最终目标。
- 迭代细化:它可以将文本查询分解成几个部分,逐步转换为 SQL,并根据反馈进行细化。
- SQL 编辑:对于复杂的查询,代理可以通过多轮编辑和扩展初始 SQL 查询。
- 上下文集成:它可以引入外部数据,应用域逻辑/约定,并相应地生成 SQL。
例如,投资分析师可能想要分析“利润和市场份额不断增长的公司”。代理可以进行对话,而不是一次性的 SQL 翻译——了解分析目标、可用的数据源、日期范围等约定、KPI 定义等。然后,它可以迭代构建正确的 SQL 查询,获取相关指标,应用适当的过滤器、聚合和 KPI 逻辑。

这种迭代式上下文感知方法能够实现更为复杂和强大的文本到 SQL 转换,以满足投资公司的特定分析需求,而僵化的 RAG 模型无法比拟。对于企业数据的这种复杂结构分析,代理能力至关重要。
旅游公司等企业需要规划、分解查询、使用外部工具
对于在线旅行预订服务,客户在规划行程时往往有多约束、多部分的要求,单纯地检索一些关于目的地的热门页面是不够的。
常规 RAG 的局限性
传统的 RAG 模型在处理多部分行程计划查询时存在不足:
- 它不能将查询分解为子任务并制定迭代规划策略。
- 它缺乏调用外部 API 的能力(例如航班搜索、酒店预订、活动推荐)。
- 它无法通过提出澄清问题来解决歧义或收集缺失的背景信息。
- 它尽力将从多个检索到的来源获得的信息连贯地结合起来,并进行推理。
Agentic RAG 如何解决这个问题
代理 RAG 系统可以以深思熟虑、迭代的方式处理复杂的旅行计划:
- 子任务分解:它可以将“为四口之家计划去意大利的 10 天旅行”这样的查询分解为预订航班、酒店、行程规划等子任务。
- API 集成:对于每个子任务,它可以与相关的外部 API 交互(例如,Skyscanner 用于航班,Booking.com 用于酒店,Tripadvisor 用于当地景点)。
- 澄清问题:它可以询问用户缺失的偏好和限制,如预算、日期、孩子的年龄、兴趣等,以完善其计划。
- 多源推理:通过结合来自多个 API/来源的信息,它可以构建出一个平衡所有要求的综合旅行计划。

例如,用户可能会询问“6 月份,一个由 2 名成人和 3 名 12 岁以下儿童组成的家庭前往中欧进行为期 7 天的旅行,预算为 5000 美元”。代理可以进行对话询问偏好 — 孩子的兴趣、游乐园/博物馆倾向、饮食需求等。然后它可以:
- 搜索飞往慕尼黑等中央出发枢纽的航班
- 寻找适合家庭入住且预算合理的酒店和租房选择
- 规划欧洲境内行程,游览萨尔茨堡、维也纳、布达佩斯等目的地,优化旅行
- 通过相关 API 进行预订,捆绑可用的套餐优惠
- 发送完整的旅行计划,包括预订详情、旅行指南等以供批准
与单次检索器相比,这种将多个数据源和服务链接在一起的迭代、多部分推理正是 Agentic RAG 的优势所在。旅行只是其中一个用例——企业可以为物流、建筑项目等复杂领域部署类似的规划功能。
欢迎你分享你的作品到我们的平台上. http://www.shxcj.com 或者 www.2img.ai 让更多的人看到你的才华。
创作不易,觉得不错的话,点个赞吧!!!

















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









