 NVIDIA新模型Nemotron
NVIDIA新模型Nemotron






作者使用 GPT-4o 生成
前言
NVIDIA 发布了一款新机型,Nemotron-340B,在某些特定领域击败了 GPT-4o(以及任何其他敢于比较的模型)。
此外,此版本还包含一些有趣的信息,例如这些模型:
- 擅长合成数据生成(允许用户生成专门的数据来训练他们的模型),
- 代表一种新的最先进的奖励模型,加上一种令人兴奋的全新对齐方法,
- 而且至关重要的是,他们证明了较弱的人工智能可以训练更强大的人工智能,这对于人类在不久的将来驾驭比我们更强大的模型的追求而言,是一个违反直觉但又至关重要的安全训练要求。
此外,NVIDIA 已将该模型作为完全开源项目发布,为业界提供了深厚的宝贵知识。
优化的野兽
那么,Nemotron 是什么?简而言之,Nemotron-4 340B是一个体面的大型语言模型 (LLM),在当今世界的关键任务上表现出色。
可预测的架构
关于架构本身并没有太多惊喜,但确认分组查询注意(GQA)已成为常态。
由于这不是本文的重点,因此我们不必过多赘述,LLM 会缓存(临时存储以避免重新计算)它们在对连续的单词预测进行推理期间执行的一些计算,我们称之为KV 缓存。
但是我们存储什么呢?
LLM 使用标记混合器(即注意力机制)来处理输入序列中的数据,通过更新每个单词相对于序列中其他单词(先前的单词)的含义。
具体来说,每个单词都有一个查询、一个键和一个值向量:
- 一个单词的查询用于与其他单词的键“对话” ,
- 并且值向量用于更新序列中每个单词相对于先前单词的含义。
这个练习通过我们称为“注意力头”的电路重复多次,大大提高了性能......但也提高了计算和内存的要求。
然而,GQA 建议对这些电路进行分组,有效地减少 KV 缓存的大小,该缓存可能会大幅增长(事实上,对于大型序列,它是 LLM 工程中最限制内存的因素)。
要深入了解KV Cache,请阅读此处。
但为了更好地理解 ChatGPT 内部发生的情况以及缓存了哪些元素,请查看下面的图表,了解 ChatGPT 如何更新单词含义以捕捉输入序列的含义:
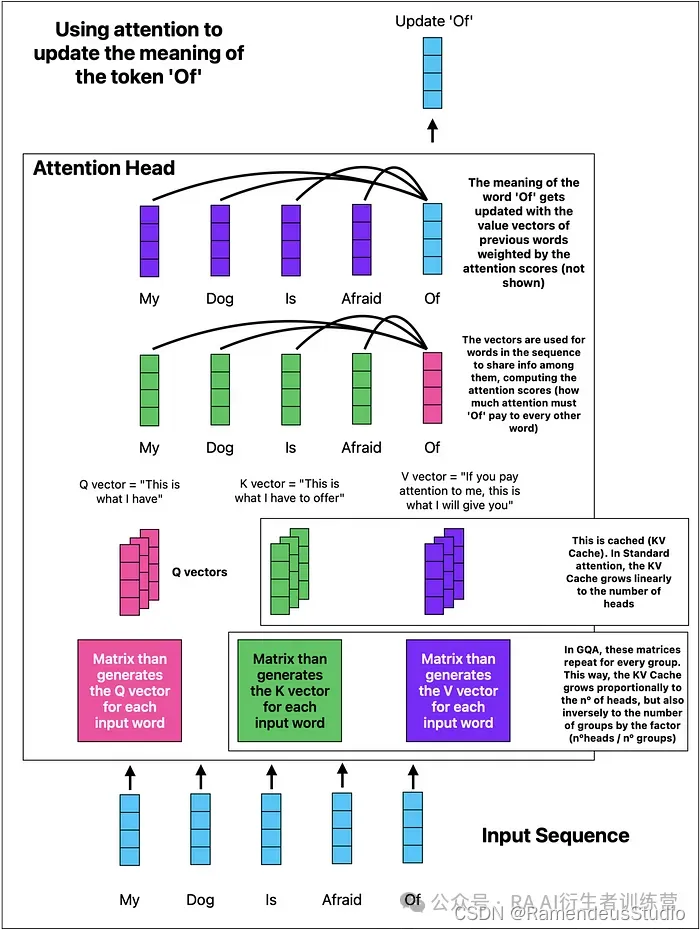
由作者生成的注意层
在上面的例子中,如果我们有 8 个注意力头和 4 个组,则 KV 缓存“仅”增加了 (8/4 = 2) 的倍数。在非 GQA 注意力中,KV 缓存将增加 8 倍。
但为什么大多数研究实验室都转向 GQA 而不是传统关注?答案就在数字中。
需要多少个 GPU 来为 Nemotron 服务?
假设您想提供该模型。
为此,我们还假设引用的 float8 精度(1 字节),这意味着您的模型重达 340 GB。仅此一项就需要 5 个最先进的 NVIDIA H100 GPU 来托管该模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2343
2343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









