




随着大语言模型(LLM)技术的不断发展,行业内的竞争日趋白热化。近日,谷歌推出的实验性大模型 Gemini-Exp-1114 凭借卓越性能,成功登顶 lmarena.ai 榜单,超越了 OpenAI 的 ChatGPT O1。这一成果标志着谷歌在 AI 领域取得了新的突破,也为全球 LLM 的发展树立了新的标杆。本文将深入探讨这一成就背后的数据和原因。
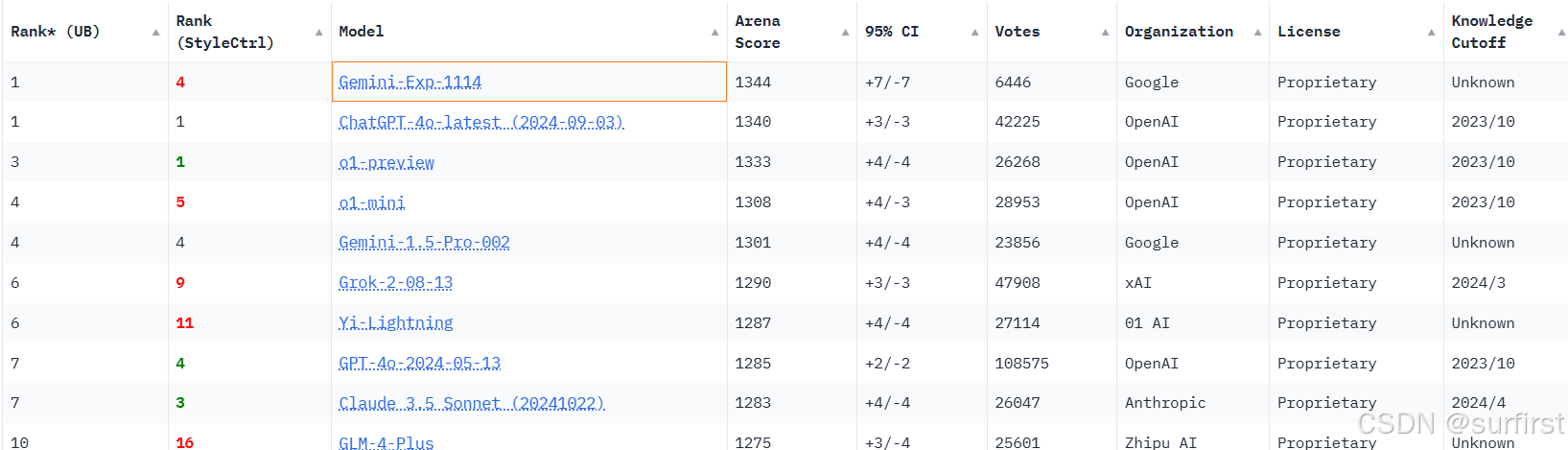
Gemini-Exp-1114 在 lmarena.ai 榜单上的卓越表现
谷歌于近期发布了实验性语言模型 Gemini-Exp-1114,并通过 Google AI Studio 向公众开放测试。该模型以全面的任务能力和跨领域表现脱颖而出:
- 多任务表现优异:在数学、创意写作、指令执行、多轮对话等多个类别中取得顶级成绩。
- 视觉 AI 实力突出:能够从图片中精准生成对应的 HTML 和 CSS 代码,展现了在视觉任务中的强大能力。
- 综合能力领先:即便在复杂的代码生成和硬提示风格控制任务中表现略逊,仅排名第三,但其整体表现依然强劲,足以确保榜单第一的位置。
这也是谷歌大模型首次在综合性排行榜中超越 OpenAI 的旗舰产品,成为行业的全新标杆。
lmarena.ai 榜单的排名方法与权威性
lmarena.ai 是由 UC Berkeley SkyLab 和 LMSYS 团队开发的开放式社区平台,用于通过人类偏好评估 LLM 的性能。其特点如下:
- 排名方法
- 平台采用 Bradley-Terry 模型,通过对模型的两两比较,计算得出相对评分。
- 数据来源广泛,既有专家评审,也有普通用户投票,确保多样性和公平性。
- 平台权威性
- 平台已经积累了超过 100 万次投票,数据覆盖了多种任务类型。
- 研究显示,投票结果与专家评分高度一致,验证了其评价机制的可信性。
- 行业认可度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6327
6327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











