




本文不讨论模型结构,而只回答一个看似简单、但极其关键的问题:
大语言模型(LLM)训练时,究竟在“吃”什么样的数据?这些数据是如何被构造出来的?
在之前的文章中(【LLM基础教程】从序列切分到上下文窗口02_三种数据切分方法),我们讨论了序列建模中的数据切分策略(滑动窗口、随机采样、顺序采样),那更多发生在 DataLoader / 序列级别。而当模型规模上升到 LLM 之后,数据问题会整体上移一个层级:从“怎么切序列”,变成了“怎么组织 token 级别的训练样本”。
本文将系统梳理 LLM 训练数据集的构造流程,并刻意与传统 RNN / 小模型的数据加载方式做区分。
一、先澄清一个常见误解:LLM 并不是在“读文章”
从人类直觉出发,我们很容易认为:模型是不是一篇一篇地读文档、学会理解整篇文章?
但在实际训练中,LLM 并不知道什么是“文章”或“段落”。
-
对模型来说:
- 最小单位是 token
- 唯一训练目标是 next-token prediction
-
模型真正看到的是这样的形式:
[ t 0 , t 1 , ⋯ , t k − 1 ] → t k [t_0, t_1, \cdots, t_{k-1}] \to t_k [t0,t1,⋯,tk−1]→tk
无论这些 token 原本来自:- 同一篇文章
- 不同文章
- 甚至不同语种
在模型眼中,它们只是一个 有限长度的 token 序列。
二、为什么 LLM 不能使用 stride=1 的滑动窗口
为什么在 LLM 规模下,“理论上正确”的滑动窗口,在工程上彻底不可行?
2.1 Attention 复杂度被放大
Transformer 的核心是 Attention,其计算复杂度为: O ( n 2 ) O(n^2) O(n2)
如果使用 stride=1 的滑动窗口:
-
同一个 token 会被反复参与 attention 计算
-
上下文高度重叠
-
单位 token 的有效梯度贡献迅速下降
换句话说,算力被浪费在大量重复上下文上。
2.2 LLM 的工程目标已经发生变化
在 LLM 训练中,更重要的不是:是否覆盖所有可能的上下文窗口。而是在有限算力下,让尽可能多的 不同 token 被“看到一次”。
因此,LLM 的核心数据目标是:最大化 token throughput,而不是样本数量。
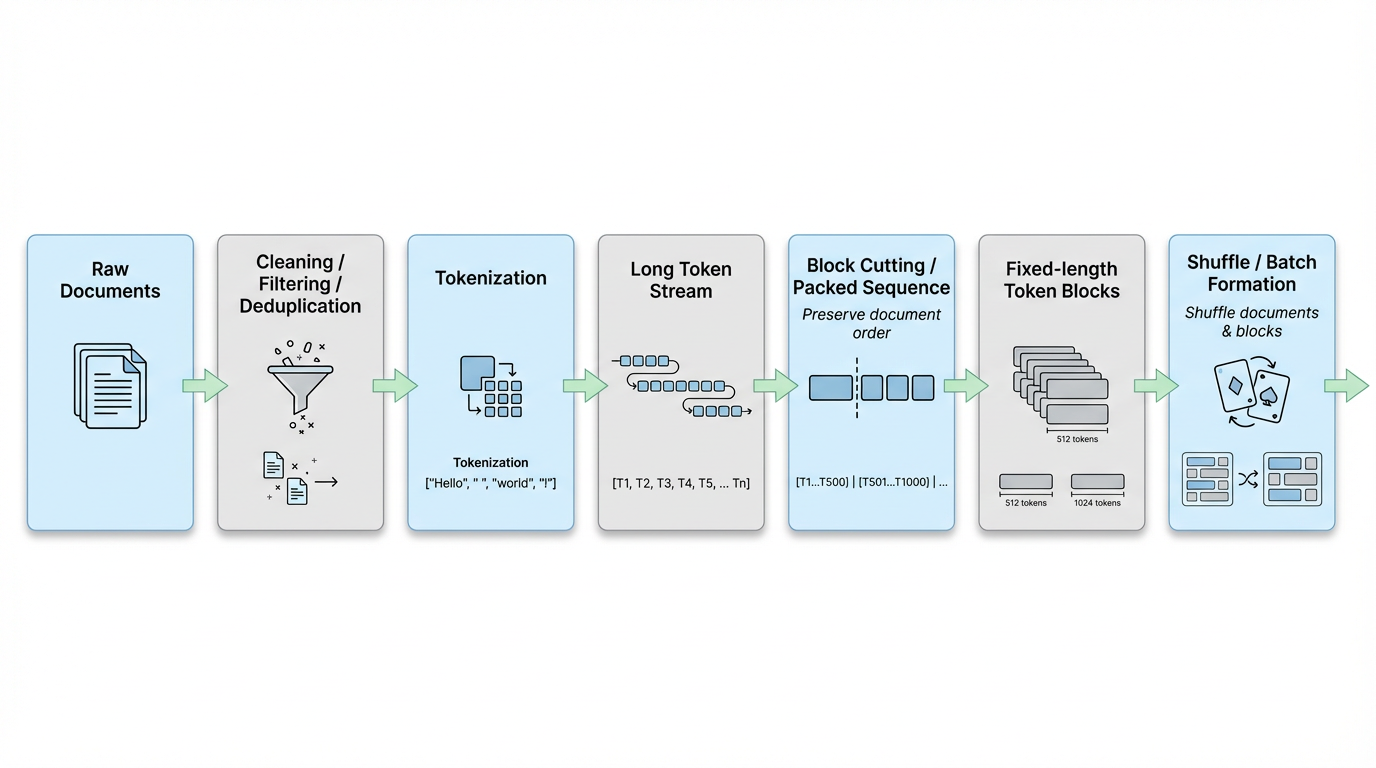
三、从文档到 Token Block:LLM 的真实数据流水线
从原始语料到模型真正使用的数据,LLM 的训练数据通常会经历如下流水线:
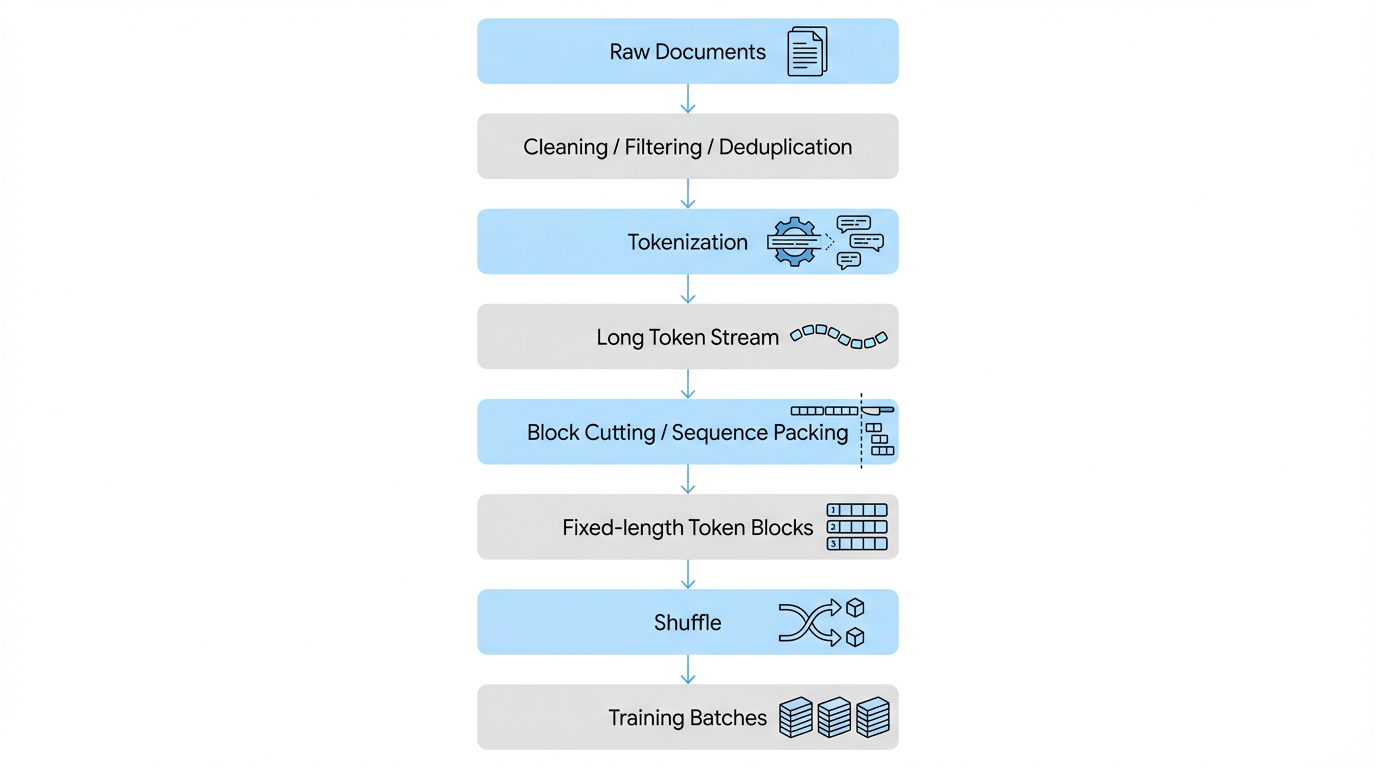
下面我们沿着这条流水线逐步拆解。
3.1 Dataset 阶段:先把“文档”变成“高价值 token”
在 LLM 中,数据处理的第一步发生在 Dataset 构建阶段,而不是训练时。
-
常见操作包括:
- 文档清洗(HTML、乱码、模板)
- 语言过滤
- 去重(exact / fuzzy)
- 长度裁剪
-
这些步骤的目标只有一个:提高“每一个 token 的训练价值”。
-
此阶段的输出,仍然是文档集合,尚未转化为模型可以直接消费的训练样本。
3.2 Tokenize 之后:文档边界为什么会消失
经过 tokenizer 后,每篇文档会被转换为 token ID 序列。
此时,系统往往会做一件非常“反直觉”的事情:不再强行保留文档边界。
-
多个文档的 token 会被拼接成一个或多个 长 token 流(token stream):
Doc A tokens | Doc B tokens | Doc C tokens | ... -
原因很简单:
- 模型并不具备“文档”这一概念,只感知 token 序列
- 强行保留边界会导致大量 padding,从而显著降低 token 利用率
-
从这一刻开始,“文档”这一人类语义单位,正式退出训练视角。
3.3 切 block:num_steps 思想在 LLM 中的升级版
接下来,系统会将长 token 流切分为 固定长度的 token block:
block_size = context_window #e.g. 4096 / 8192
-
切分方式通常是:
- 不重叠
- 顺序切分
[t0 ... t4095] [t4096 ... t8191] ... -
这一步,本质上对应我们在RNN 中熟悉的:
num_steps = T -
只是切分的位置,从 DataLoader 上移到了 Dataset 构建阶段。
这一变化并非算法思想的转变,而是工程规模的必然结果:
- LLM 的训练语料规模达到 TB / PB 级
- 训练通常运行在大规模分布式系统中
- 训练时动态切分长文本,会成为严重的 I/O 和计算瓶颈
因此,LLM 选择将序列切分这一高频、确定性的操作,提前固化到 Dataset 构建阶段,从而:
- 提高 token 吞吐率
- 降低训练阶段的系统复杂度
- 保证大规模并行训练的稳定性
3.4 Packed Sequence:提高 token 利用率的关键技巧
Packed sequence 并不是把多篇文档“混在一起训练”,而是通过 attention mask,在同一个 block 内并行训练多条彼此独立的序列,从而最大化 token 利用率。
现实中,文档长度往往无法整除 block_size,如果处理不当,将造成大量算力浪费。
(1) padding到底浪费了什么
假设:block_size = 16
-
有三篇文档,token 长度分别是:
Doc A: 10 tokens Doc B: 4 tokens Doc C: 6 tokens -
如果不做 packed sequence,而是“一篇文档一个 block”:
Block 1: [A A A A A A A A A A PAD PAD PAD PAD PAD PAD] Block 2: [B B B B PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD] Block 3: [C C C C C C PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD]问题在于:
-
每个block都在计算attention
-
大量 token 是 PAD
-
PAD token 没有任何训练价值
-
attention 复杂度是 KaTeX parse error: Expected 'EOF', got '_' at position 24: …{O}(\text{block_̲size}^2)
👉 PAD 也会参与计算
算力被浪费在“空位置”上,这在 LLM 里是不可接受的。
-
(2) 不能把不同文档拼在一起吗
你可能会自然地问:那我把 Doc A、B、C 直接拼起来不就好了?**
比如:
[A A A A A A A A A A | B B B B | C C]
-
**问题来了:**如果什么都不做,模型会认为:
- Doc B 的 token
- 可以 attend 到 Doc A 的 token
- Doc C 的 token
- 可以 attend 到 Doc A、B 的 token
- Doc B 的 token
-
这意味着模型在学习:“一篇文章的结尾,逻辑上可以接另一篇完全无关的文章”,这显然是错误的上下文假设。
(3) Packed Sequence 真正在做什么?
Packed sequence 的核心不是“拼接”,而是物理上拼在一起,逻辑上彼此隔离。
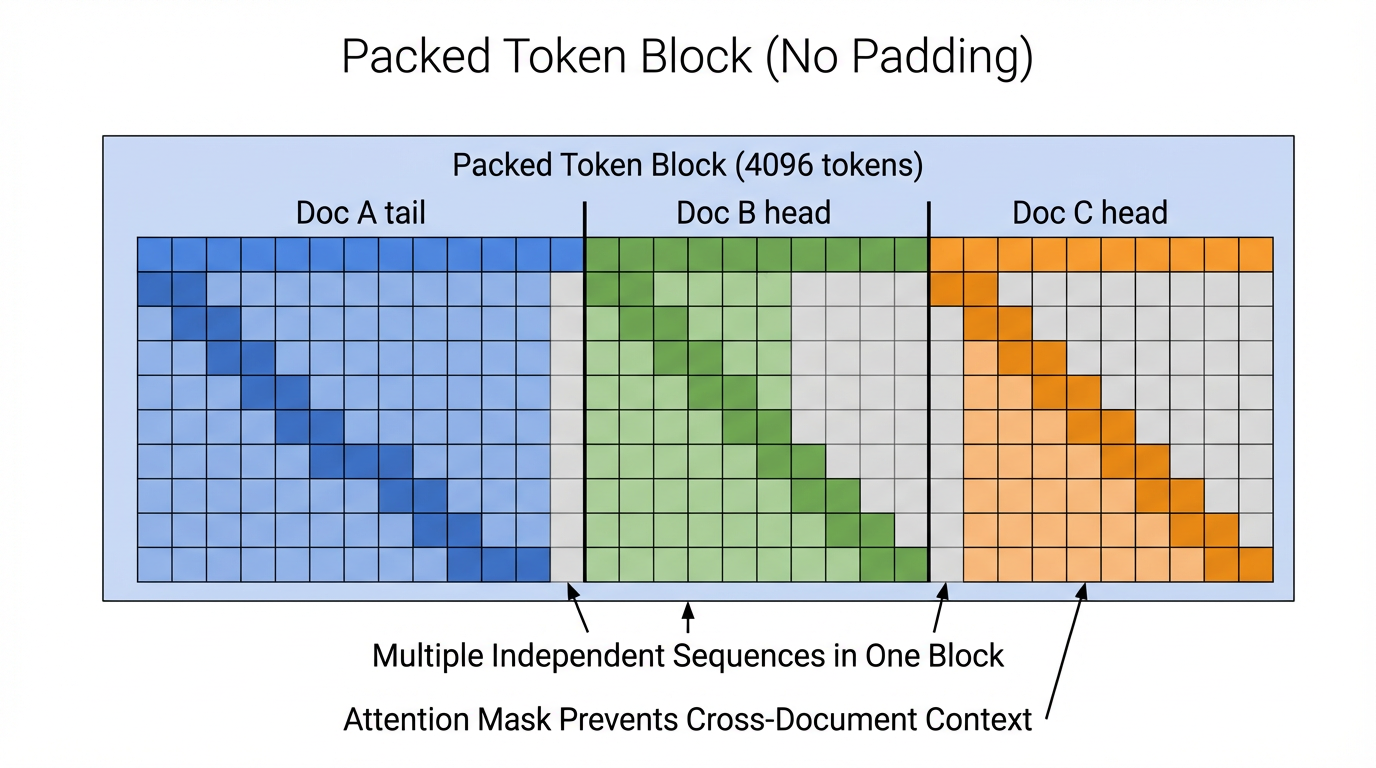
-
在构造 block 时:
Block: [DocA_tail | DocB_head | DocC_head] -
这样做可以:
- 填满 block
- 避免 padding
- 提高 token 密度
-
真正起作用的是 attention mask:
- Doc A 的 token:
- ❌ 看不到 Doc B / C
- Doc B 的 token:
- ❌ 看不到 Doc A
- ❌ 看不到 Doc C
- Doc C 的 token:
- ❌ 看不到 Doc A / B
用“视野”来理解就是:
Doc A tokens: [只能看到 A] Doc B tokens: [只能看到 B] Doc C tokens: [只能看到 C]它们处在同一个 block 中,但在 attention 里是多条完全独立的序列。
- Doc A 的 token:
(4) 为什么这一步如此重要
Packed sequence 同时解决了三个 LLM 级别的问题:
-
token 利用率
- 几乎没有 padding
- 每个 attention 计算都在“算有效 token”
-
吞吐率(throughput)
- attention 复杂度不变
- 单位算力学习到的 token 数显著增加
-
不破坏语言建模假设
- next-token prediction 仍然成立
- 不会引入“跨文档胡乱接话”的错误信号
如果说,切 block 解决的是「序列长度如何规模化」,那么 packed sequence 解决的就是「如何不浪费每一个算出来的 attention」
3.5 随机性从哪里来?
在前面的文章里,我们讲过 随机采样(random sampling) 的核心目的是为了打破样本之间的强相关性。
在 LLM 中,随机性不再通过滑动窗口制造,而是通过文档、token 与 block 的多层 shuffle 实现;目标始终只有一个:避免模型被局部顺序强相关性主导。
-
文档级 shuffle(Dataset 构建时)
在 tokenize 之前或之后:
- 文档顺序会被打乱
- 多语料源会被混合
于是 token 流本身就已经是“非连续语义”的。
-
在 LLM 预训练中:
- ✅ 会打乱:Doc A / Doc B / Doc C 的出现顺序
- ❌ 不会打乱:Doc A 内部 token 的顺序
-
假设你有三个文档:
Doc A: [a1 a2 a3 a4] Doc B: [b1 b2 b3] Doc C: [c1 c2 c3 c4 c5]Dataset 层面会做的是:
[A, B, C] → [C, A, B]
即这一步只改变文档之间的相对位置,而:
- 每个文档内部 token 顺序严格保持
- next-token 预测仍然合法
-
Token block 级 shuffle(训练时)
即使 block 是顺序切的:
Block 1: [t0 ... t4095] Block 2: [t4096 ... t8191] Block 3: [t8192 ...]在真正送进模型前:
Block 17 Block 3 Block 204 Block 58 ...👉 模型看到的 block 顺序是随机的,而不是原始文本顺序。
-
多 epoch 的重新混合
每一轮训练:
- 文档会重新 shuffle
- block 重新排列
- packed sequence 重新组合
于是:
同一个 token,在不同 epoch 中,往往会和“不同的邻居”一起出现。
这正是 LLM 版的“随机采样”。
四、训练 vs 推理:为什么你“感觉”模型是顺序的?
一个非常容易被忽略的事实是:
| 阶段 | 数据形态 | 核心目标 |
|---|---|---|
| 训练 | 并行、打乱的 token block | token 吞吐最大化 |
| 推理 | 严格顺序 token | 连贯生成 |
-
推理阶段通过 KV Cache:
- 避免重复计算历史 token
- 表现得“像顺序采样”
但这是一种 系统级优化,而不是训练数据的构造方式。
五、结语
当你真正理解这一点:语言模型训练,本质上是在用有限上下文,近似学习无限长序列的统计规律
你就会发现,无论是 RNN 时代的 num_steps,还是 LLM 时代的 token block,本质上解决的都是同一个问题。

















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









