



OpenDriveLab 投稿
量子位 | 公众号 QbitAI
叶问蹲、跳舞、跑步,一个策略全搞定!
|
|


近日,来自香港大学、NVIDIA和清华大学的联合研究团队提出了一种名为AMS(Agility Meets Stability)的统一人形机器人全身控制框架,首次实现了在单一策略中同时具备动态运动跟踪和极限平衡控制能力。

核心思路:
AMS从三个关键方面解决动态运动与平衡控制的统一问题:
1. 异构数据源:从机器人动作空间直接采样生成可扩展的平衡数据,突破人类数据限制,缓解长尾分布问题。
2. 混合奖励机制:选择性应用平衡先验奖励,精准平衡指导不牺牲敏捷性,化解优化目标冲突。
3. 自适应学习策略:动态调整采样概率,同时对每个动作”因材施教”,实现高效的自适应学习。
下面来看详细内容。
人形机器人的“两难困境”
人形机器人要在人类环境中执行各种任务,需要同时具备两个看似矛盾的能力:敏捷的动态运动和精确的平衡控制。
反观人类,却能轻松自然的实现这种协同——比如在动态行走后精确放置物体,或者在单腿站立时用自由肢体作为临时支撑去够取物体。
然而,对于人形机器人来说,同时实现这两种能力却是一个巨大的挑战。
目前,相关研究主要沿着两个不同的方向推进:
- 动态运动跟踪方向:专注于实现敏捷、流畅的动态动作,如跳舞、跑步等。以ASAP等为代表的工作展示了人形机器人在动态运动方面的出色表现,能够完成各种高机动性的动作。

- 平衡控制方向:专注于实现精确、稳定的平衡控制,如单腿平衡、极限平衡姿态等。以HuB等为代表的工作在人形机器人的平衡能力方面取得了显著进展,能够完成人类都难以完成的平衡动作。

然而,现有的方法很难在统一框架中同时实现两者。这背后的原因主要有两个方面:
首先是数据限制。现有方法主要依赖人类动作捕捉(MoCap)数据来训练策略,虽然这些数据提供了丰富的动态行为,但存在"长尾分布"问题——极端平衡等场景的数据严重不足,使得策略在部署时很容易遇到训练数据分布外的动作,导致表现显著下降。此外,这种依赖使得策略的能力上限被限制在了部分的人类可执行动作空间内,无法充分利用机器人独特的机械能力。
其次是优化目标的冲突。多样化的目标动作具有不同的分布特征,需要不同的优化目标。在强化学习框架中,为一种运动类型设计的奖励函数可能会无意中阻碍另一种运动类型的学习。例如,限制质心保持在支撑脚上方可以为平衡任务提供精确指导,但对依赖自然动量传递和协调全身运动的动态动作来说,这种限制过于严格。
AMS:人形机器人统一全身控制框架
为了解决这些挑战,研究团队提出了AMS框架,如图所示,通过三个关键创新实现了动态敏捷性和平衡鲁棒性的统一:
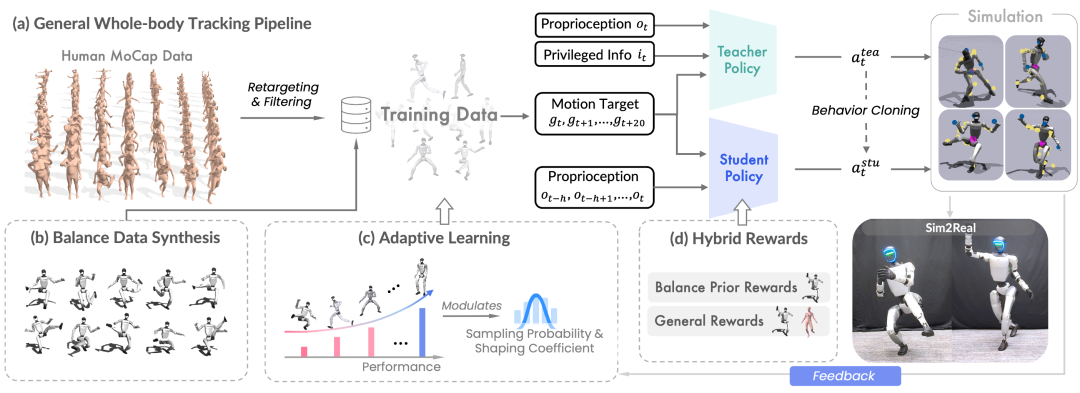
异构数据源:从机器人动作空间采样生成平衡数据
目前在基于全身跟踪的人形机器人控制框架中,研究者们通常遵循这样的流程:
首先收集大量的人类运动轨迹,然后通过运动学重定向技术将这些人类运动转换为机器人可用的参考轨迹,最后通过强化学习(RL)将这些仅考虑运动学的参考轨迹转换为动力学可行的机器人动作。
在这个流程中,参考人类运动轨迹至关重要——这些轨迹不仅决定了策略的学习目标,也在一定程度上决定了策略的能力上限。
为了提升策略能力,最近的研究者们通过收集更大规模、高质量、多样化的参考动作数据来实现可扩展学习(Scalable Learning),不断扩大训练数据集规模以提升策略性能。
AMS的核心洞察是:手动收集人类动作数据并不是获取参考动作的唯一途径。
研究团队提出了一个全新的思路——从机器人自身出发,通过在机器人的动作空间直接采样生成参考动作数据,覆盖各种可能的平衡动作。这种方法生成的合成平衡动作数据具有以下优势:
- 物理可行性保证:
直接在机器人运动空间中采样,避免了动捕数据中的传感器噪声和运动学重定向误差,确保动作的物理合理性,如下图所示,展示了准确可控的足部接触状态和质心轨迹。
- 可扩展性:
通过采样生成,可以轻松扩展数据规模,无需人工采集,大幅降低数据获取成本。此外,不受人类身体限制,能够生成人类也难以完成的极限平衡动作,充分挖掘机器人独特机械结构带来的动作空间。
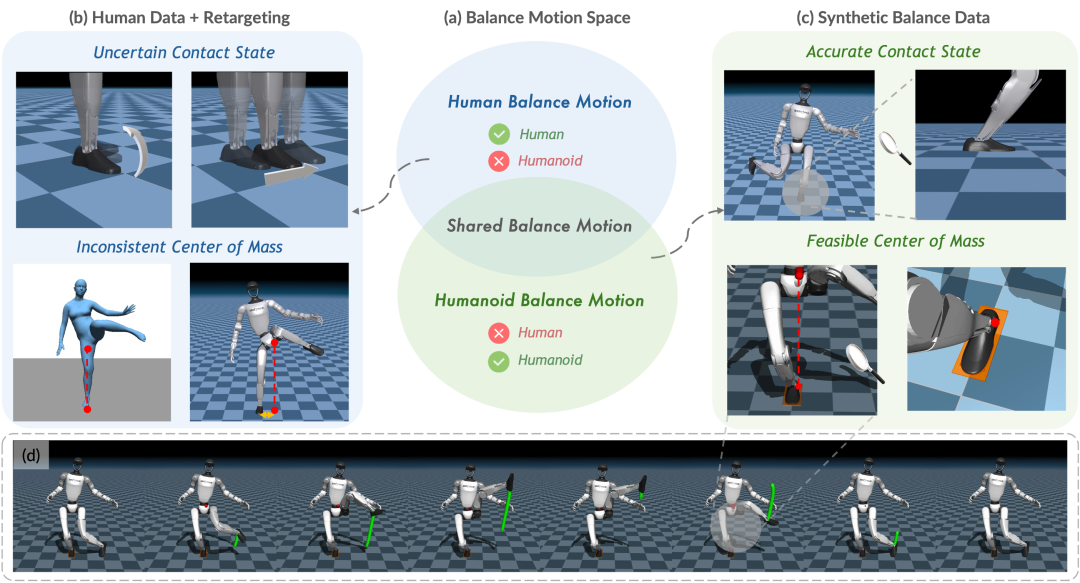
通过整合人类动捕数据和可控的合成平衡动作,AMS有效缓解了数据的长尾分布问题,为策略训练提供了更加丰富和多样化的参考动作数据。
实验结果显示,基于合成平衡动作的训练,策略学会了在各种挑战性姿态中保持平衡,能够零样本跟踪训练集中未见过的极端平衡动作,如”叶问蹲”这样的功夫式单腿蹲动作,展现了良好的泛化能力。
|
|


混合奖励机制:精准平衡指导,不牺牲敏捷性
动态运动和平衡动作的优化目标存在冲突,如何在不牺牲敏捷性的前提下提供精确的平衡指导?
对此,AMS设计了混合奖励机制:
- 通用奖励:
应用于所有数据,鼓励鲁棒的运动跟踪(如关节位置、速度、根方向等)。 - 平衡先验奖励:
仅应用于合成平衡数据,包括质心奖励和足部接触一致性奖励等,为平衡动作提供明确的物理先验引导。这种选择性应用平衡先验奖励的设计,使得策略既能从人类动作中学习敏捷行为,又能在挑战性姿态中保持可靠的稳定性,避免了优化目标的冲突。
自适应学习策略:动态调整采样概率,每个动作“因材施教”
为了实现高效学习,AMS引入了自适应学习策略,包含两个关键组件:
- 自适应采样:
根据跟踪性能动态调整运动序列的采样概率,实现有效的困难样本挖掘。
- 自适应奖励调整:
为每个运动维护特定的误差容忍度参数,基于个体性能而非统一处理所有运动,使策略能够同时适应训练进度和运动多样性,实现“因材施教”的个性化自适应学习。
实验结果:一个策略,多种能力
研究团队在Unitree G1人形机器人上进行了大量真机实验验证。结果显示,AMS的统一策略能够:
1、动态运动跟踪
AMS策略在动态运动方面表现出色,能够流畅地执行折返跑、篮球运球、武术等多种高动态动作:
|
|


△动态动作
2、极限平衡控制
得益于可扩展的合成平衡动作数据,AMS展现了精确的平衡控制能力:
|
|


△随机采样生成的单腿平衡动作
3、实时遥操作
AMS还支持多种实时遥操作模式,低实验实时跟踪人类运动,展示了其作为基础控制模型的实用价值:
|
|


△基于惯性动捕的实时遥操作
|
|


△基于RGB相机的实时遥操作
总的来说,AMS展示了统一框架在人形机器人控制中的巨大潜力。
通过异构数据源、混合奖励机制和自适应学习策略,一个策略就能同时实现动态敏捷性和平衡鲁棒性,为人形机器人在人类环境中的应用奠定了重要基础。
论文链接:https://arxiv.org/abs/2511.17373
项目主页:https://opendrivelab.com/AMS/


















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









