



梦瑶 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT发布三周年,OpenAI没发布,各大AI玩家倒纷纷整出大活。
这不,视频生成领域,快手放话可灵要“一周连续上新”,而Day 1第一更,就甩出了可灵AI视频「O1模型」,“全球首个统一多模态视频模型”。
把视频修改、镜头延展、多主体参考这些过去要在好几个模型间倒腾的活,全塞进了一个统一模型里,深层语义理解直接“一把梭”的那种。
emm…怎么说呢?感觉是把NanoBanana的那些玩法做成了AI视频!
先来看这个,我随手把一张“兵马俑+粉饼”的照片扔给O1,结果它直接roll出一段“兵马俑补妆被领导抓现行”的视频:

咱再来玩点有意思的,自从“威尔·史密斯吃意面”实测横空出世后,AI视频模型界就有了个潜在“行规”:
来了先吃碗面。
这回我也让可灵O1上桌来一口——大口吃面+直视镜头,结果人物面部和周围场景都稳得住,小帅吃的那叫一个香啊:

整体实测下来,最直观的感受是:O1多主体元素的镜头切换里确实能稳住一致性,局部编辑也很自然,日常修瑕疵完全够用,还能生成10s长视频,对长视频创作者非常友好。
(前提是要氪金)
更多实测效果,我也先测为敬,你们要有更多奇思妙想,也欢迎评论区开麦~~~
可灵AI视频「O1模型」一手实测
咱先来看页面有啥变化,可灵给O1模型搞了个单独的界面,在这里我们可以直接上传不同的主体/图片/视频。
界面顶部有四个快捷功能,点哪用哪,先选功能再生成,AI会更有针对性,生成效果更稳~
我也简单给大家捋一下这次AI视频O1模型的几个核心亮点:
1.全能指令:照片、视频、文字都能当指令,一句话调度多模态素材。
2.全能参考:镜头无论怎么转,主体都能稳住一致性,支持多个角色自由组合。
3.超多创意:支持组合不同技能,一次生成多种创意变化,并且支持3-10秒自由生成时长。
少说多测,我们就从多图参考、局部编辑、镜头延展三路开打,看看这O1模型能不能把全能指令梭到底!
多图参考生成
多图参考生成能力真正的难点从来不是“把人堆进画面”,而是镜头能不能连贯,主体能不能稳住一致性,这俩要是崩了,整个画面真的会立马垮掉…(sad)
前阵子的卢浮宫偷窃案想必大家都刷到了,咱不妨整点剧情化玩法,拍一出逃离大戏:让蒙娜丽莎听到风声,拔腿开跑!
我把包括蒙娜丽莎、卢浮宫走廊、卢浮宫大厅、门口保安四个主题元素喂给了O1模型,并给予了AI一段剧情提示词:
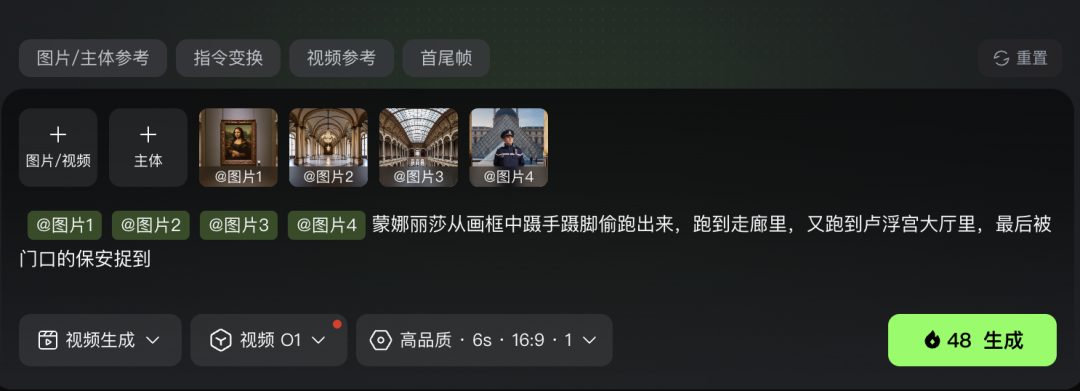
从下面的效果来看,蒙娜丽莎的“逃跑”动作整体确实对上了指令逻辑,从画框到走廊再到大厅的转场自然顺滑,镜头跟踪也跟得很稳:

但还是暴露了一个小问题,AI对动词类指令的理解还没到位,比如“蹑手蹑脚”“捉到”这类更细的动作没有表现出来……不过整体观感还行吧~
再玩点有意思的:我把老黄、小扎、老马三位硅谷大佬的形象丢给O1,希望他仨在东北农村来一场“意外偶遇”:
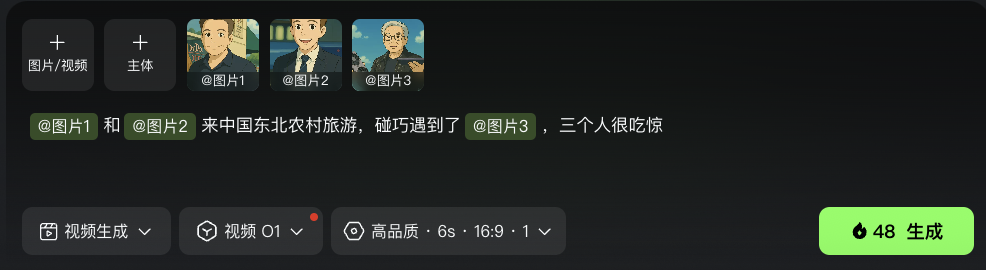
emm…这效果,属实震撼。
老黄到了东北还死攥着自家显卡不撒手,像是大清早坐高铁来村口找小扎谈合作的???

从生成效果来看,AI可能把人物搞混了,提示词是“小扎和老马偶遇老黄”,结果画面演成了“小扎和老马四目相对”,老黄被默默丢在后景当NPC…
此外背景环境要是能更入乡随俗一点就更完美了,现在这味儿还不太东北,看来O1模型对老铁大本营数据和文化,学得还不够深啊,得好好补补。
但不得不说,这种“错位偶遇”,还挺有喜感的???
局部编辑能力
再来试试第二part——视频局部编辑。
在O1模型里,我们可以对视频的局部元素随意“动刀”:替换、删除、增加统统OK,感觉就是把PS的局部功能整个搬进了视频模型里。
我先丢给O1的,是一段超酷的摩登女孩在纽约街头遛狗狗的视频:

都2025了,溜狗有点没意思,于是我让O1把视频中的狗狗“摇身一变”成了赛博「四足机器狗」,这溜在街上多飒啊!

局部替换处理的确实不错,哪怕两个主体都处于移动状态,依旧保证了画面元素没崩。
看够了真实世界,咱再换个画风,这次我丢给O1的是一段像素风的外滩夜景视频,游客们在那儿咔擦咔擦给东方明珠拍照:

心里有个鬼点子,既然在东方明珠下面喝蜜雪冰城会触发防御塔攻击,那我索性直接把东方明珠变成雪王!!!

太对味儿了!一点违和感都没有,O1模型在局部处理这块确实很能打,感觉AI视频现在是真的能当PS来用了。
想怎么P,就怎么P~
咦,那为啥不直接出个图片版呢?(文末有答案)
镜头延展/动作跟踪能力
按官方说法,除了多元素参考和局部编辑,O1模型这次还主推镜头延展与真人动作捕捉。
那咱先来测测动作捕捉能力到底咋样~
这两天《疯狂动物城2》是真的火,一首《ZOO》不仅在电影里狂燃,还一路火到短视频平台,各路博主扎堆跳舞cover。
那就顺势来点离谱的,请出前阵子被全网封神的“顶流魔性企鹅”,让它根据网友的舞蹈动作,copy同款潮舞!

瞧这小舞步小姿势,不敢说一模一样,但是确实每个动作都卡在点上了,几乎也算是1:1还原,动作捕捉成功!
咱们再来试试O1模型的镜头延展能力。
这回我喂给AI一段电影感的5s视频,让AI根据提示词帮我补齐后面的剧情内容,这是原视频:

我给AI的提示词是这样子的——
基于该视频生成下一个镜头:突然,一只手落在男人的肩上,视频里的男人一回头,发现是自己的特工搭档,搭档立刻捂住他的嘴让他别出声,两人神情紧绷地扫视四周。

值得表扬的是,人物一致性保持的还不错,但是“落在肩上”和“回头”的动作被AI吞了,只保留了捂嘴的动作,看来这O1有点自己的想法??
来试点更有意思的玩法
除了咱们刚才测的这几个维度,还有很多有意思的玩可以在O1上实现。
比如这个OOTD换装玩法,当时NanoBanana一上线就掀起一波“万能换装”热潮,现在在O1模型里更简单了,把想搭配的服装、配饰元素往里一拽:
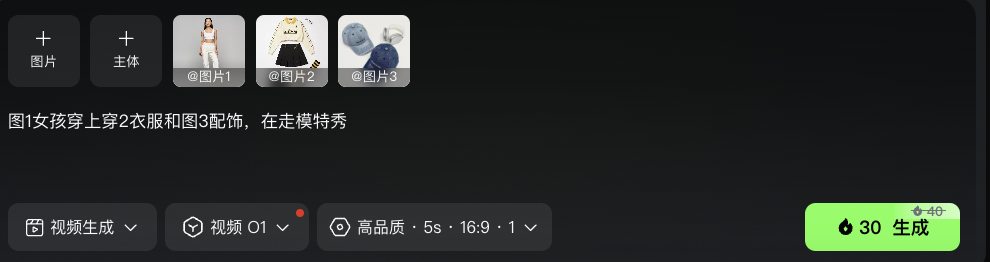
然后立刻就能roll出“动态版QQ秀”,看来买衣服真不能只看平面图,还是得找个专业的模特上身试一下才有效果!

再来玩点网上很火的特效玩法, 这次我喂给O1的是一张印着干裂土地的明信片,指令是:让它“长出枝芽”,顺便来个3D立体效果。
一把复古金属浇水壶从画面右上角伸入,壶口倾斜,将水壶里的水流浇湿到明信片的土地上,照片里干裂的土地迅速变湿,颜色加深,湿润的土地从裂缝中冒出嫩绿春笋破土而出,迅速生长拔高,从明信片中长出来,3D效果。

效果确实很逼真,最主要的是“破土而生”的瞬间很自然,立体感甚至有点像会呼吸的纸面浮雕。
还是一张普通明信片,我们再来试试最近很火的3D丹顶鹤的玩法。
一只手抚摸明信片中的丹顶鹤,丹顶鹤振翅高飞,水面泛起涟漪,飞出画面。

其实这个视频里真正的难点,不是丹顶鹤“跳出明信片”本身,而是它飞出画框、落到水面、激起涟漪这一连串动作里,周围环境元素能不能保持一致性、不穿帮。
这一点上O1做得确实挺到位,转场自然、光影也没有乱。
整体来看,可灵O1不管是视频局部编辑、多元素生成,还是各种特效玩法,表现都算稳,以前要在好几个视频工具之间来回倒腾,现在基本能在一个模型里一站式搞定,方便又高效。
不愧是AI生成视频领域当前的扛把子选手啊。
One More Thing
最后,说一下AI生成视频替代P图的问题——为啥不直接出个图片编辑呢?
这不,实测玩耍可灵视频一整天的我,发现Day 2的上新已经发布了。
昨天是「AI视频」O1模型,今天可灵还发布了「图片」O1模型,即日起即可使用。
据官方介绍,在图片生成上O1模型在高度一致性、细节处理、风格复刻、创意融合等方面表现都不错。
不仅能生成多人自拍合照、室内场景图,还能修改主体元素等等:

不说了,我要拿这个小红书起号去了(手动狗头)~
给看到这里的读者老爷们笔芯,点个赞再走吧…
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🔊 不到2周,量子位MEET2026智能未来大会就要来了!
张亚勤、孙茂松等AI行业重磅嘉宾,以及百度、高通、亚马逊等头部AI企业已确认出席,RockAI、太初元碁、自变量、小宿科技等业内新秀也将参与分享,还有更多嘉宾即将揭晓 👉 了解详情
📍 12月10日
📍 北京金茂万丽酒店
一键报名线下参会,期待与你共论AI行业破局之道 

🌟 点亮星标 🌟


















 1
1

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









