



非羊 整理自 凹非寺
量子位 | 公众号 QbitAI
在AIGC的浪潮中,3D生成模型(如TRELLIS)正以惊人的速度进化,生成的模型越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。复杂的去噪过程、庞大的计算量,让生成一个高质量3D资产往往需要漫长的等待。
为了加速,人们通常会想到在2D视频生成中大杀四方的“缓存(Caching)”技术——复用上一步的计算结果,跳过重复劳动。但在3D领域,直接照搬这套逻辑却翻车了:2D画面里的一点像素误差可能只是噪点,但在3D结构里,一点误差就会导致模型出现破洞、面片错位,甚至结构崩塌。
如何在加速的同时,保住3D几何的“命根子”?
西湖大学AGI实验室提出的Fast3Dcache给出了完美答案。这是一种无需训练(Training-free)、即插即用的几何感知加速框架。它像一位经验丰富的雕刻师,能敏锐地判断哪些部位已经成型(可以“偷懒”复用),哪些部位还在变化(需要精雕细琢),从而在大幅提升速度的同时,完美保持甚至提升了模型的几何质量。


核心洞察:3D形状的“三段式”演化律
Fast3Dcache的诞生,源于研究团队对3D几何生成过程的深入解剖,研究团队对直生3D框架TRELLIS的第一阶段——结构生成阶段进行了观察。他们发现,在扩散模型的去噪过程中,体素(Voxel)的变化并不是杂乱无章的,而是呈现出一种“三阶段稳定模式”:
1. 剧烈震荡期:生成初期,物体的大致轮廓正在形成,体素变化剧烈,这时候必须全力计算,不能偷懒。
2. 对数线性衰减期:中期,越来越多的体素开始稳定下来,不再发生翻转。这种稳定性的增加遵循着美妙的对数线性规律。
3. 精细调整期:尾声,绝大多数体素已经定型,只剩下微小的细节修补,可以采用固定采样的激进加速方法。
基于这一发现,Fast3Dcache并没有简单粗暴地切掉计算量,而是设计了两大核心模块来精准“排兵布阵”。
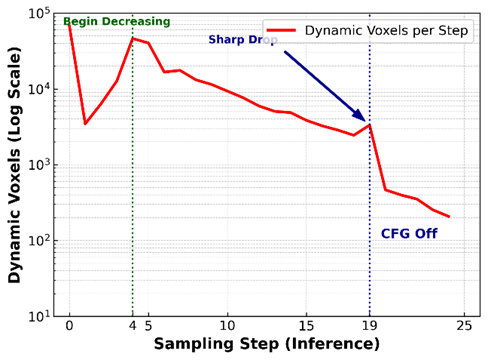
△ 图1 体素变化的三阶段图
两大杀手锏:PCSC与SSC
为了将上述观察转化为算法,Fast3Dcache引入了两个精巧的机制:
1. PCSC:预测“预算”的指挥官
既然体素的稳定过程是有规律的,我们就可以“预判”!PCSC(Predictive Caching Scheduler Constraint)模块通过在早期的锚点步骤进行一次校准,就能画出一条“衰减曲线”,精准预测后续每一步有多少体素是稳定的。它动态地分配每一部的“计算预算”——变化大的时候多算点,稳定的时候多存点,绝不浪费一度电,也绝不错过一个细节。
2. SSC:挑选“懒人”的监工
有了预算,具体该复用哪些token呢?SSC(Spatiotemporal Stability Criterion)模块通过分析特征在潜空间(Latent Space)中的速度(Velocity)和加速度(Acceleration)来做决定。
如果一个特征的速度和加速度都很小,说明它已经“稳如泰山”,直接复用缓存即可。
如果它还在剧烈波动,说明它是几何生成的关键点,必须重新计算。
这种基于时空动力学的筛选机制,比传统的仅看数值相似度要靠谱得多,彻底解决了3D结构断裂的问题。
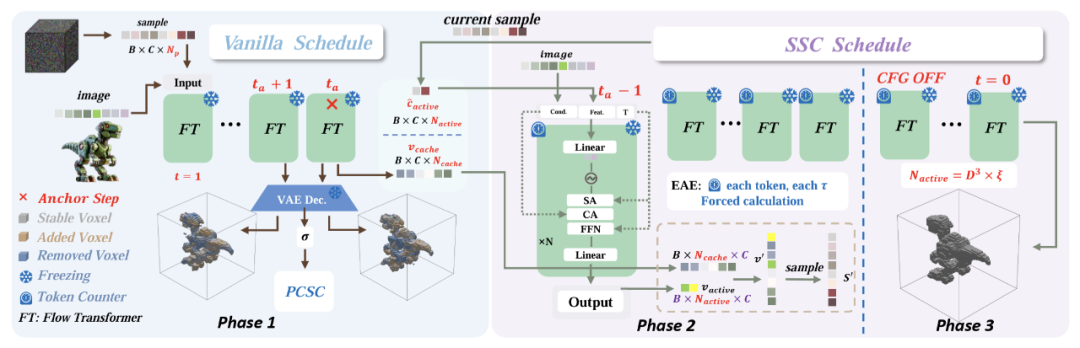
△ 图2 Fast3Dcache整体流程图
打破“不可能三角”,实现提速、减量与质量保持
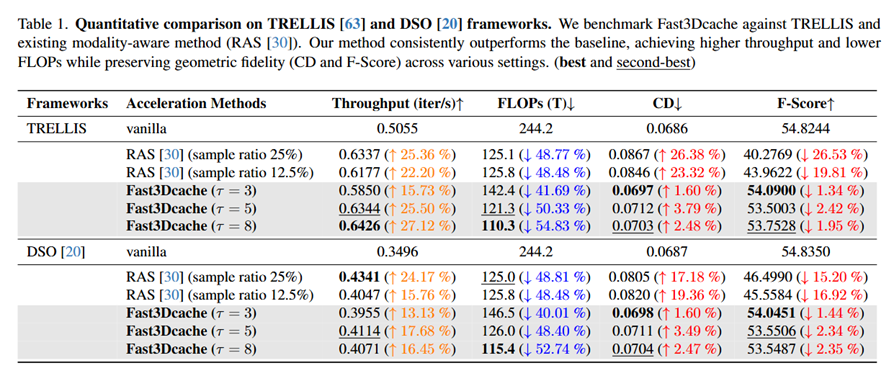
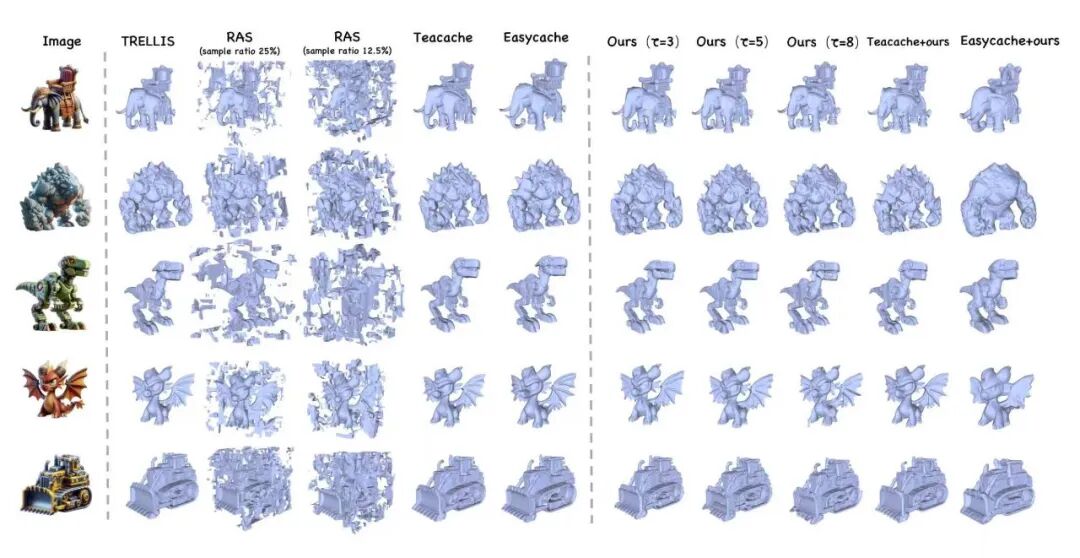
Fast3Dcache同时实现了提高几何生成速度,减少计算量以及保持高质量。在TRELLIS和DSO框架上的测试显示,Fast3Dcache在保证几何质量的前提下,显著提升了推理吞吐量。当参数τ=8时,模型提速27.12%,计算量(FLOPs)降低54.83%,如论文中表1所示。
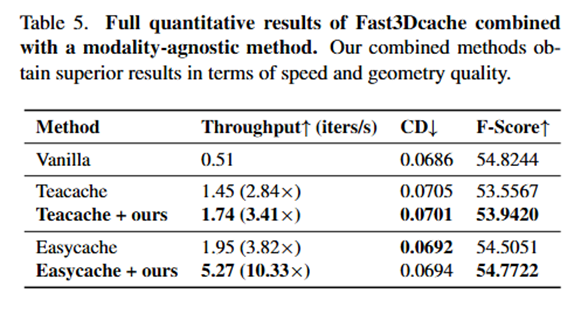
更重要的是,Fast3Dcache具有正交性,可以与现有的视频/图像加速算法(如TeaCache, EasyCache)无缝叠加,如论文中表2所示,Fast3Dcache + TeaCache推理速度为原来的3.41倍。此外作者在附录中补充了实验,如论文中表5所示,作者验证了Fast3Dcache + EasyCache推理速度提升更快,是原来的10.33倍!

下图所示,Fast3Dcache自身以及和其他方法结合在提高速度以及降低计算量的同时,仍然保持了高质量的几何特征。


















 3
3

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









