




包含编程籽料、学习路线图、爬虫代码、安装包等!【点击领取】
大家好,我是Python_trys,一名热爱Python的程序员。爬虫作为Python的拿手好戏,一直备受关注。但对于初学者来说,爬虫可能显得有些神秘和复杂。
为了帮助大家快速入门Python爬虫,我整理了10个简单易懂的爬虫小案例,涵盖了爬虫的基本原理、常用库以及实战技巧。通过这些案例,你将学习如何使用Python抓取网页数据,并从中提取有价值的信息。

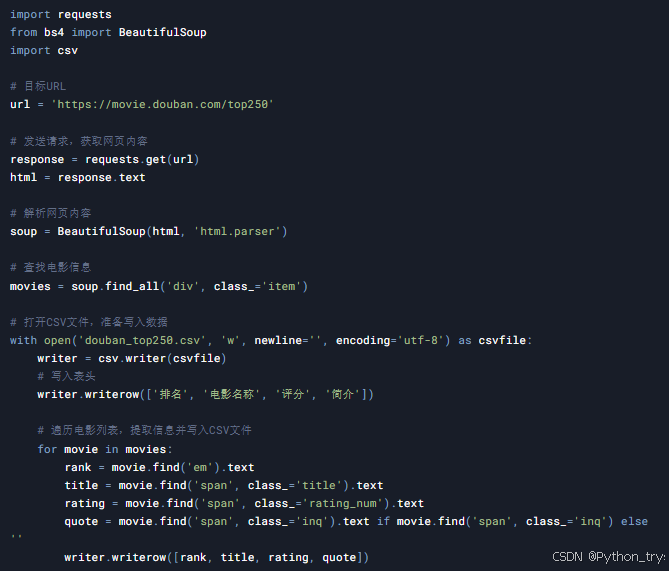
案例1:爬取豆瓣电影Top250
目标: 爬取豆瓣电影Top250的电影名称、评分、简介等信息,并保存到CSV文件中。
技术点: requests库、BeautifulSoup库、CSV文件操作
代码示例:
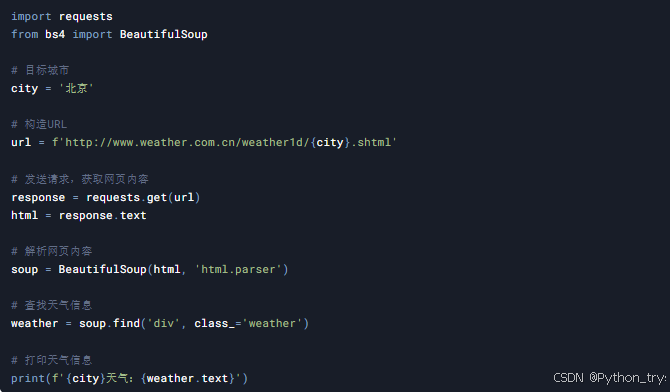
案例2:爬取天气信息
目标: 爬取中国天气网指定城市的天气信息,并打印到控制台。
技术点: requests库、BeautifulSoup库
代码示例:
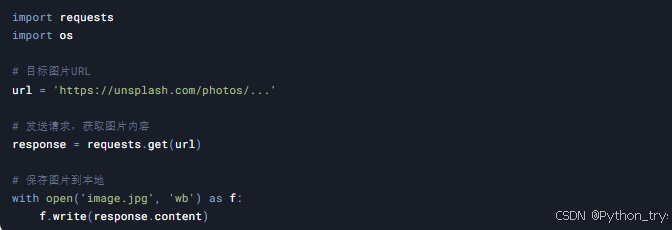
案例3:爬取图片
目标: 爬取Unsplash网站上的图片,并保存到本地。
技术点: requests库、os模块
代码示例:
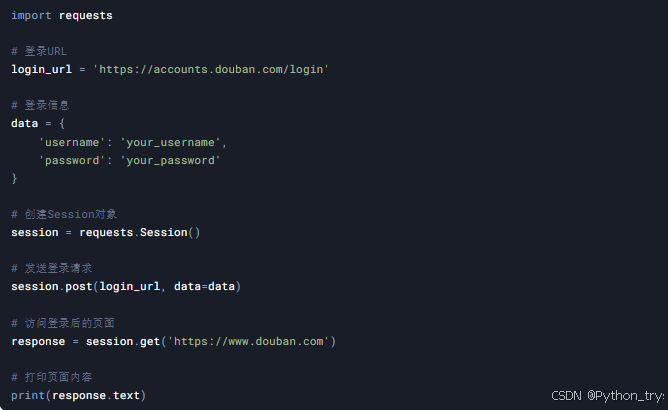
案例4:模拟登录
目标: 模拟登录豆瓣网站,并获取登录后的页面内容。
技术点: requests库、Session对象
代码示例:
案例5:爬取动态网页
目标: 爬取使用JavaScript渲染的动态网页数据。
技术点: Selenium库
代码示例:
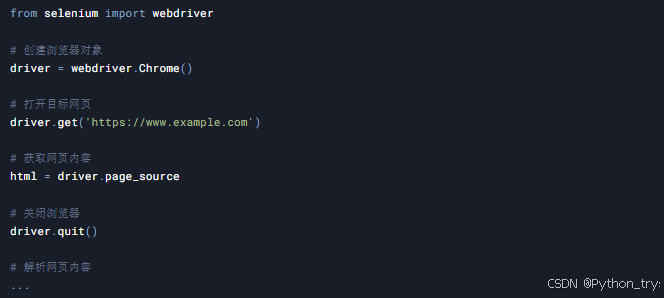
案例6:爬取API数据
目标: 爬取公开API提供的数据,例如天气API、股票API等。
技术点: requests库、JSON数据处理
代码示例:
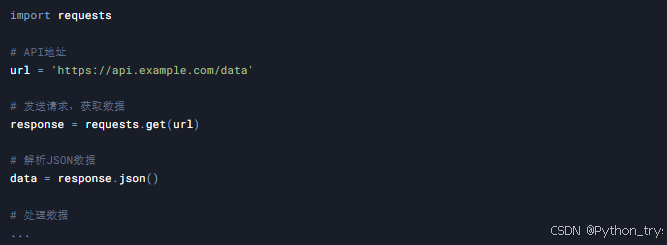
案例7:使用代理IP
目标: 使用代理IP隐藏真实IP地址,防止被封禁。
技术点: requests库、代理IP
代码示例:
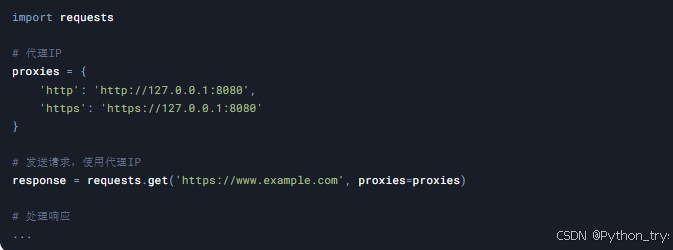
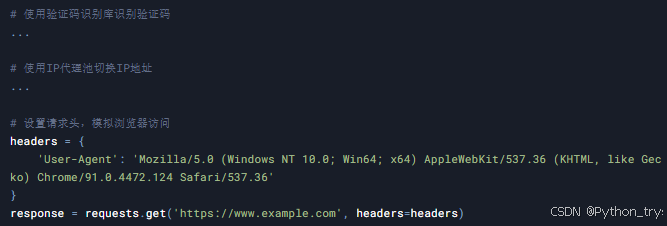
案例8:处理反爬虫机制
目标: 应对网站的反爬虫机制,例如验证码、IP封禁等。
技术点: 验证码识别、IP代理池、请求头设置
代码示例:
案例9:数据存储
目标: 将爬取到的数据存储到数据库或文件中。
技术点: MySQL数据库、MongoDB数据库、CSV文件、Excel文件
代码示例:

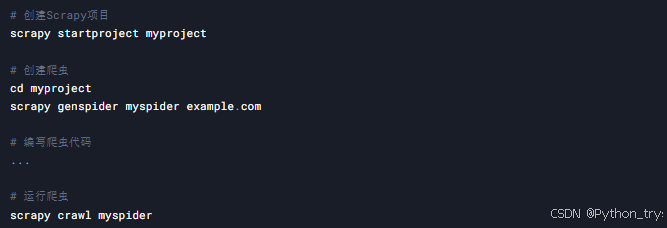
案例10:爬虫框架
目标: 使用Scrapy框架快速构建爬虫项目。
技术点: Scrapy框架
代码示例:
结语
以上10个Python爬虫小案例,涵盖了爬虫的各个方面,相信通过学习和实践这些案例,你一定能够快速入门Python爬虫,并掌握爬虫的基本技能。
当然,爬虫技术博大精深,还有很多值得学习和探索的地方。希望大家能够保持学习的热情,不断进步,成为一名优秀的Python爬虫工程师,祝大家学习愉快,早日成为爬虫大神!
最后:
希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里领取!】
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习


















 2458
2458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









