



包含编程籽料、学习路线图、爬虫代码、安装包等!【点击领取】

在本文中,我们将介绍如何使用Python编写一个简单的音乐爬虫,从网页上抓取音乐文件并保存到本地。我们将使用requests库来发送HTTP请求,BeautifulSoup库来解析HTML页面,以及os库来处理文件路径。
1. 准备工作
在开始之前,确保你已经安装了以下Python库:
requests
BeautifulSoup
os
你可以使用以下命令来安装这些库:

2. 分析目标网站
在编写爬虫之前,我们需要分析目标网站的结构,找到音乐文件的下载链接。假设我们要从一个音乐网站(例如:example.com)下载音乐。
打开目标网站,找到音乐播放页面。
使用浏览器的开发者工具(通常按F12打开),检查音乐播放器的源代码,找到音乐文件的URL。
3. 编写爬虫代码
3.1 导入必要的库

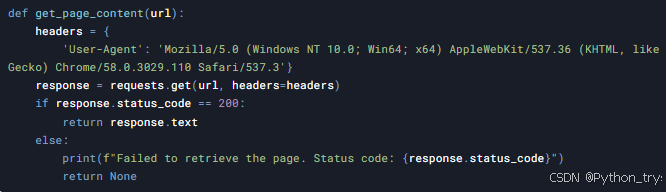
3.2 发送HTTP请求并获取页面内容
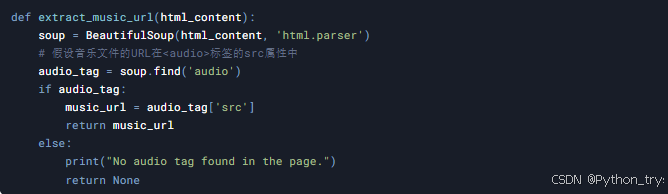
3.3 解析页面内容并提取音乐链接
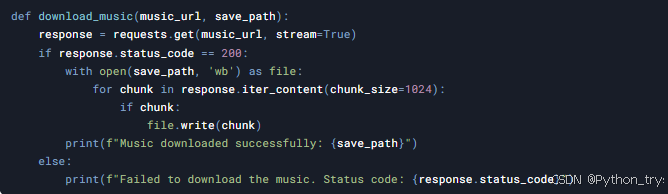
3.4 下载音乐文件
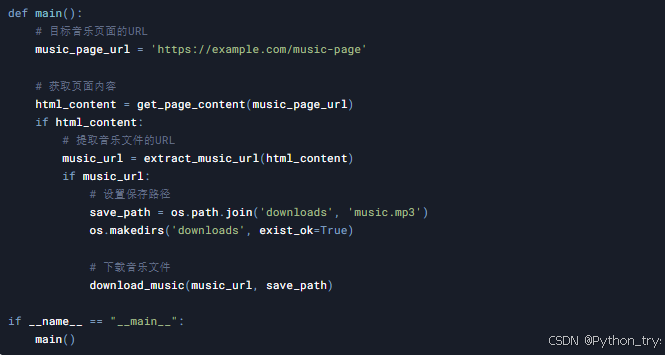
3.5 主函数
4. 运行代码
将上述代码保存为一个Python文件(例如:music_downloader.py),然后在终端或命令行中运行:

如果一切顺利,你将在downloads文件夹中找到下载的音乐文件。
5. 注意事项
合法性:在爬取任何网站之前,请确保你遵守该网站的robots.txt文件和相关法律法规。未经授权的爬取可能会违反网站的使用条款。
反爬虫机制:一些网站可能会使用反爬虫机制,如IP封禁、验证码等。你可能需要使用代理、模拟浏览器行为等方法来绕过这些机制。
错误处理:在实际应用中,建议添加更多的错误处理代码,以应对网络问题、文件不存在等情况。
6. 总结
通过本文,我们学习了如何使用Python编写一个简单的音乐爬虫,从网页上抓取音乐文件并保存到本地。虽然这个爬虫非常简单,但它涵盖了爬虫的基本流程:发送请求、解析页面、提取数据、保存文件。你可以根据实际需求对这个爬虫进行扩展和优化。
希望这篇文章对你有所帮助!如果你有任何问题或建议,欢迎在评论区留言。
最后:
希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里领取!】
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习


















 5662
5662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









