







一、网络爬虫概述
1、网络爬虫按照系统结构和实现结构,分以下类型:
通用网络爬虫、聚集网络爬虫、增量式网络爬虫、深层网络爬虫。
通用网络爬虫:baidu,Yahoo 和 谷歌,这些属于通用性网络爬虫的范畴。
聚焦网络爬虫:一个自动下载网页的程序。根据既定的抓取目标,有选择地访问万维网上的网页与相关的链接,获取所需要的信息。
增量式网络爬虫:对已下载网页采取增量式更新和只爬行新产生的或者已经产生变化网页的爬虫,他能够在一定程序上保证所爬行的网页时尽可能新的网页。例如:想获取赶集网的招聘信息,以前爬取过的数据没有必要重复爬取,只需要获取更新的招聘数据,这个时候就要用到增量式爬虫。
深层网络爬虫:Web 页面按存在方式可以分为表层网页和深层网页。表层网页是指传统搜素引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。深层网络是那些大部分内容不能通过静态链接获取的、隐藏在搜素表单后,只能用户提交一些关键词才能获得的 Web 页面。例如用户登录 或者注册才能访问的页面。可以想象这样一个场景:爬取贴吧或者论坛中的数据,必须在用户登录后,有权限的情况下才能获取完整的数据。
下面展示一下网络爬虫实际运用的一些场景:
1、场景的 BT 网站,通过爬取互联网的 DHT 网络中分享的 BT 种子信息,提供对外的搜素服务。
2、一些云盘搜素网站,通过爬取用户共享出来的云盘文件数据,对文件数据进行分类划分,从而提供对外搜素服务。
2、网络爬虫结构
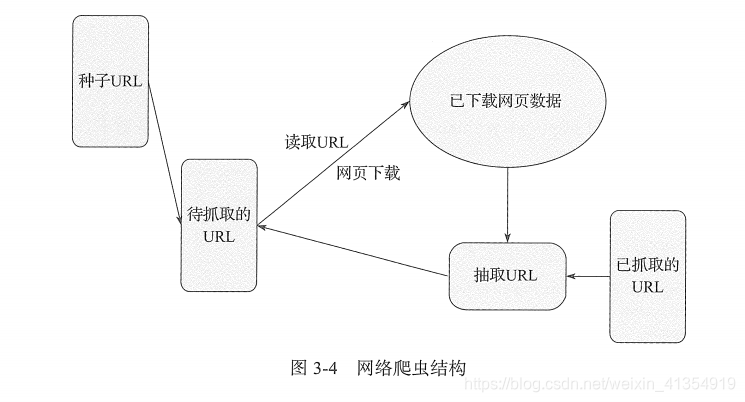
上述的截图来自课本:《Python爬虫开发与项目实战》,网络爬虫的基本工作流程如下:
1、首先选取一部分精心挑选的种子 URL。
2、将这些 URL 放入待抓取 URL 队列。
3、从待抓取 URL 队列中读取待抓取队列的 URL,解析 DNS,并且得到主机的 IP ,并将 URL 对应的网页下载下来,存储进已下载网页库中。此外,将这些 URL 放进已抓取 URL 队列。
4、分析已抓取 URL 队列中的 URL,从已下载的网页数据中分析出其他 URL,并和已抓取的 URL 进行比较去重,最后将去重过的 URL 放入待抓取 URL 队列,从而进入下一个循环。
这便是一个基本的通用网络爬虫框架及其工作流程。
二、HTTP 请求的 Python 实现
1、urllib2/urllib 实现
urllib2 和 urllib 是 Python 中的两个内置模块,要实现 HTTP 功能,实现方式是以 urllib2 为主,urllib 为辅,但是在python3 中 已经将 urllib 和 urllib2 合并成了一个 urllib 库,如果需要实现请求和响应,可以使用 urllib库里的 request。
1、GET 请求:
示例以爬取 www.baidu.com 为例子:
# *-* coding:utf-8 *-*
from urllib.request import urlopen
url="http://www.baidu.com/"
response = urlopen(url)
with open(r'C:\Users\wyb\Desktop\python\BBtest\aa.html',mode='w',encoding="utf-8") as f:
f.write(response.read().decode('utf-8'))
print("over")输出结果:
在复杂一下:每次运行输入某一个明星,搜狗搜索自动生成并记录到某个HTML文件里面
这次使用的是 requests 库中个get 方法,代码如下:
# *-* coding:utf-8 *-*
import requests
query=input("请输入一个明星")
url = 'https://www.sogou.com/web?query=%s'%(query)
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"}
respon = requests.get(url,headers=headers,)
with open(r'C:\Users\wyb\Desktop\python\BBtest\aa.html',mode='w',encoding="utf-8") as f:
f.write(respon.text)
print("over")例子:爬取豆瓣喜剧排行榜
# *-* coding:utf-8 *-*
import requests
#爬取豆瓣喜剧电影
url = 'https://movie.douban.com/j/chart/top_list'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"}
param = {"type":"24",
"interval_id":"100:90",
"action":"",
"start":0,
"limit":20
}
respon = requests.get(url,headers=headers,params=param)
with open(r'C:\Users\wyb\Desktop\python\BBtest\aa.html',mode='w',encoding="utf-8") as f:
f.write(str(respon.json()))
print("over")2、POST 请求
例子:在百度翻译输入某个单词,返回其中文翻译
#百度翻译
query=input("请输入一个英文")
url = 'https://fanyi.baidu.com/sug'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"}
dat = {"kw":query}
respon = requests.post(url,headers=headers,data=dat)
print(respon.json())
with open(r'C:\Users\wyb\Desktop\python\BBtest\aa.html',mode='w',encoding="utf-8") as f:
f.write(str(respon.json()))
print("over")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









