 AI大模型微调核心逻辑与学习资源
AI大模型微调核心逻辑与学习资源




你有没有想过,AI 大模型就像一个刚从名牌大学毕业的高材生,脑子里装满了各种知识,却在面对具体工作时有点 “水土不服”?比如一个能写文章的大模型,让它专门写美食测评就可能差点意思;一个会聊天的 AI,要它精准回答医学问题也会力不从心。这时候,“微调” 就派上用场了。简单说,微调就是给这个 “高材生” 做岗前培训,让它在某个领域变得更专业。
1、什么是微调?
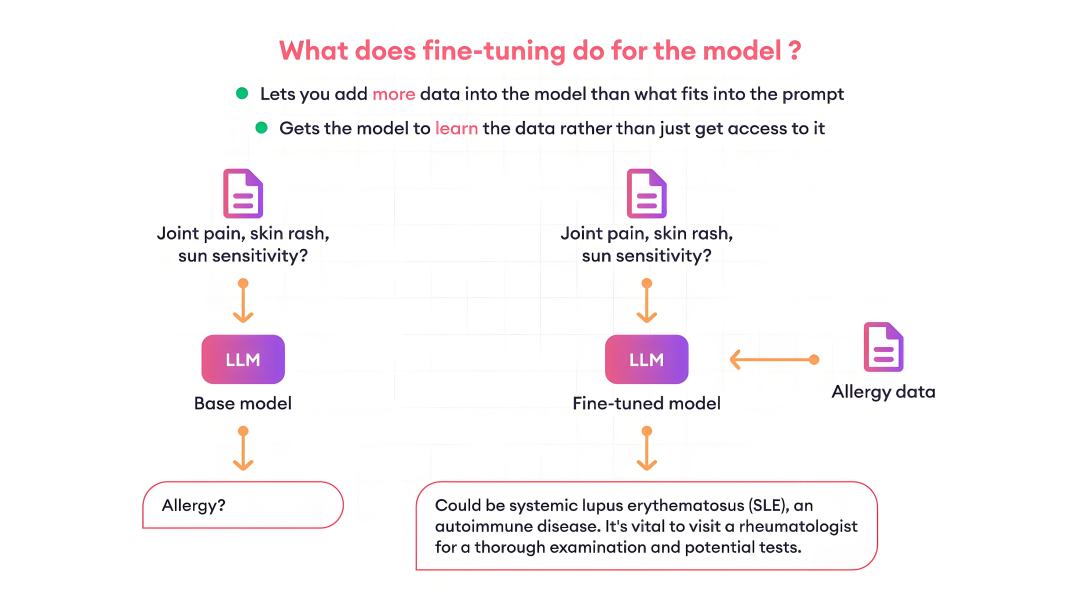
微调就是在已经训练好的大模型基础上,用你自己的数据继续训练,让模型更符合你的特定需求。
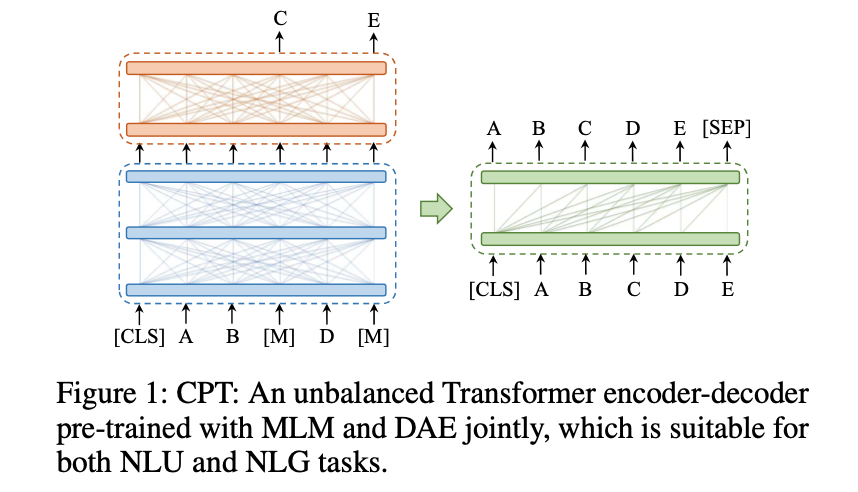
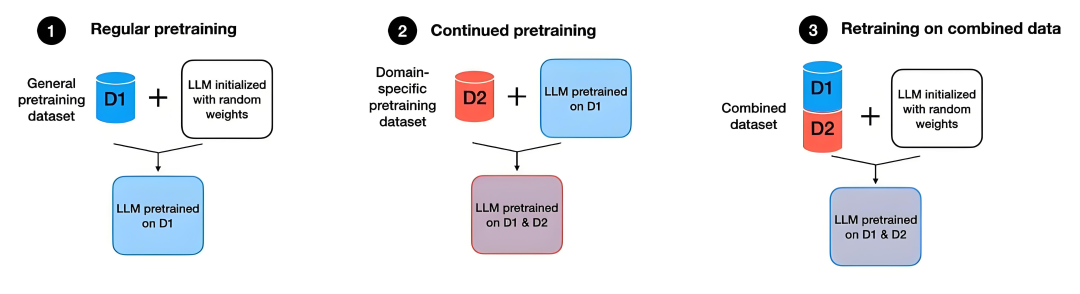
CPT(ContinualPre-Training)继续预训练最基础的微调方式。你拿到一个预训练好的模型,然后用大量无标签的文本数据继续训练它。
SFT(Supervised Fine-Tuning)监督微调最常用的微调方式。你准备好问题-答案对,教模型如何回答特定类型的问题。
DPO(Direct Preference Optimization)偏好训练最新的微调技术,通过对比“好答案“和“坏答案"来训练模型。
2、三种微调方式详解
CPT(Continued Pre-Training,继续预训练)
通过无标注数据进行无监督继续预训练,强化或新增模型特定能力。
数据要求
需要大量文本数据(通常几GB到几十GB)数据质量要高,最好是你目标领域的专业内容
适用场景
让模型学习特定领域的知识,比如医学、法律、金融
增强模型对某种语言或方言的理解
让模型熟悉你所在行业的专业术语
SFT(Supervised Fine-Tuning)监督微调
有监督微调,增强模型指令跟随的能力,提供全参和高效训练方式。
数据要求
通常需要几千到几万条高质量的问答对
答案要准确、风格统一
适用场景
训练客服机器人
创建特定任务的助手(比如代码助手、写作助手)
让模型学会特定的对话风格

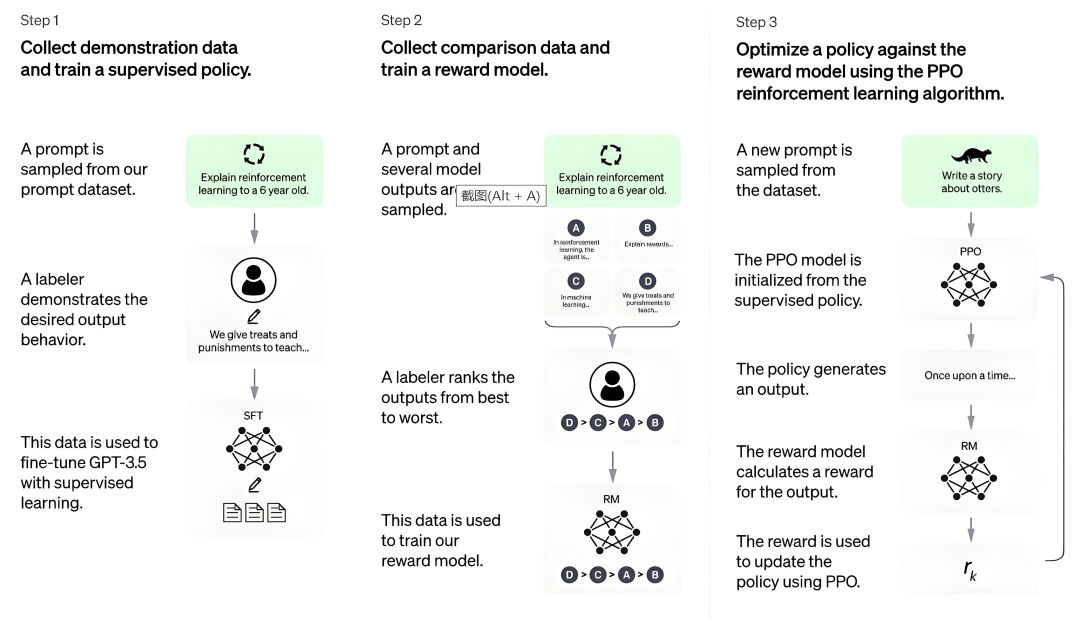
DPO(Direct Preference Optimization)偏好训练
引入负反馈,降低幻觉,使得模型输出更符合人类偏好
工作原理
给模型同一个问题的两个不同答案
告诉模型哪个答案更好
模型学会倾向于生成更好的答案
适用场景
让模型的回答更符合人类偏好
减少有害内容的生成
提高回答的质量和安全性

3、非必要不微调
1.成本高:需要大量GPU资源和时间
2.技术门槛高:需要懂机器学习、数据处理、模型训练3.数据要求严格:需要高质量、大量的训练数据4.维护复杂:模型更新后需要重新微调
4、优先考虑替代方案
1.提示词工程
通过精心设计的提示词让模型理解你的需求
成本低,见效快,容易调整
适合大部分使用场景
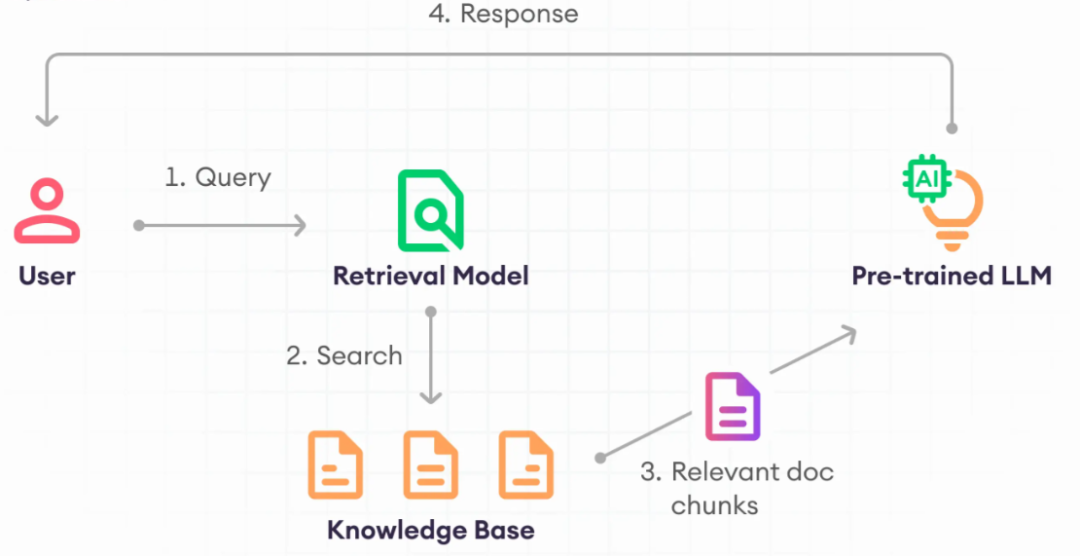
2.RAG
让模型检索相关文档后再回答
能够获取最新信息
不需要重新训练模型
什么情况有必要微调
1.特定领域的专业知识
当你的业务涉及非常专业的领域,而通用模型的知识不够用时
如:医疗诊断系统、法律文书生成、特定行业的技术支持。
2.特殊的输出格式要求
需要模型输出特定格式,而提示词难以稳定控制时。如:结构化数据提取、特定的代码生成规范、标准化的报告格式。
3.私有数据的深度理解
需要模型深度理解你的私有数据,而RAG检索效果不够好时。如:企业内部知识库的深度应用、个人化推荐系统、基于历史数据的预测
4.性能要求极高的场景
对响应速度和准确性要求都很高的场景。如:实时客服系统、高频交易的决策支持、大规模自动化处理
5、总结
微调是一个强大的工具,但不是万能药。在考虑微调之前,先试试提示词优化和RAG。只有在确实需要深度定制,且有足够资源投入时,才考虑微调。
选择微调平台时,技术小白推荐阿里云百炼,有技术基础的推荐LLaMA-Factory。记住,工具是为了解决问题,不要为了微调而微调。
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

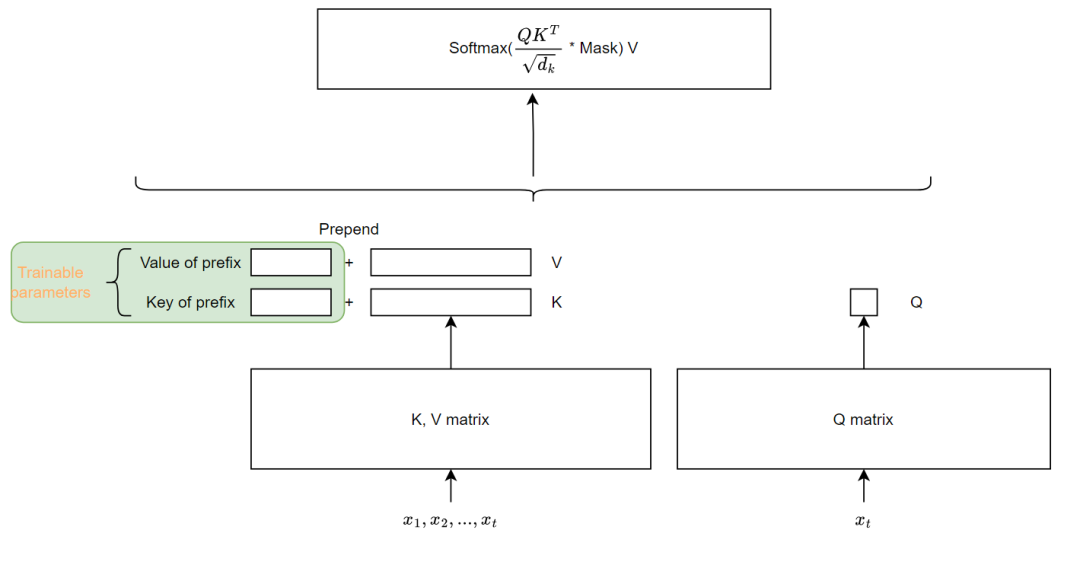
L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









