




本文通过
AssemblyScript— 通过写ts编译到wasm的语言(非常好用!)生成的wasm文件,用于做 A4×4⋅B4×4A_{4\times 4}\cdot B_{4 \times 4}A4×4⋅B4×4 的矩阵乘法,用到了SIMD技术、Relaxed-SIMD技术。
结论
调用延迟:500ms / 100,000,000 次 = 5 纳秒/次
| 场景 | 调用路径 | PC 端 (高性能桌面) | 移动端 (高端手机) | 移动端 (中低端手机) |
|---|---|---|---|---|
| 简单类型 | 热路径 (Hot Path) (JIT 优化后, 像你的测试) | 5 - 20 纳秒 | 20 - 100 纳秒 | 100 - 500 纳秒 |
| (i32, f64) | 冷路径 (Cold Path) (首次或少量调用) | 50 - 200 纳秒 | 200 - 800 纳秒 | 1,000+ 纳秒 (1µs+) |
| 复杂类型 | 任何路径 (传递字符串、对象等) | 几百纳秒到几微秒 | 数微秒到数十微秒 | 可能更长 |
- 我的测试设备(没插电源😂)

为什么会这么快?
- JIT 的威力:当你用一个
for循环调用同一个 WASM 函数一亿次时,V8 的 JIT (Just-In-Time) 编译器会识别出这是一个 “超级热点” 。它不会傻傻地每次都走通用的调用流程。 - Trampoline:V8 会为这个特定的调用点(JS 调用 WASM 的地方)生成一段高度优化的、专门的机器码,我们称之为“蹦床”(Trampoline)或“调用存根”(Thunk)。这个蹦床知道确切的函数签名(3个
i32参数,无返回值),所以它可以以最快的方式完成参数传递和上下文切换。 - 类型稳定:循环中传递给 WASM 函数的参数类型始终是数字,这让
JIT的优化工作变得非常简单。
2. JS/WASM 调用的“正常范围”是多少?
这才是你问题的核心。这个开销不是一个固定的数字,它受多种因素影响,其中最主要的是硬件平台和调用路径是否为热点。
以下是一个大致的范围,可以作为参考:
| 场景 | 调用路径 | PC 端 (高性能桌面) | 移动端 (高端手机) | 移动端 (中低端手机) |
|---|---|---|---|---|
| 简单类型 | 热路径 (Hot Path) (JIT 优化后, 像你的测试) | 5 - 20 纳秒 | 20 - 100 纳秒 | 100 - 500 纳秒 |
| (i32, f64) | 冷路径 (Cold Path) (首次或少量调用) | 50 - 200 纳秒 | 200 - 800 纳秒 | 1,000+ 纳秒 (1µs+) |
| 复杂类型 | 任何路径 (传递字符串、对象等) | 几百纳秒到几微秒 | 数微秒到数十微秒 | 可能更长 |
名词解释:
- 纳秒 (ns): 十亿分之一秒。
- 微秒 (µs): 百万分之一秒 (1 µs = 1000 ns)。
影响调用开销的其他因素:
- 参数的复杂性:这是除了硬件之外最大的影响因素!
- 传递简单的数字(如
i32,f64)是最快的。 - 传递字符串、对象、
anyref等复杂类型,开销会急剧增加几个数量级。因为这涉及到更复杂的内存操作、数据编码/解码(如 TextEncoder/Decoder)、甚至垃圾回收(GC)的交互。
- 传递简单的数字(如
- JavaScript 引擎:V8 (Chrome/Node.js), SpiderMonkey (Firefox), JavaScriptCore (Safari) 的实现不同,开销也略有差异,但总体趋势相似。
- WASM 调用 JS:从 WASM 内部调用一个导入的 JS 函数,通常比 JS 调用 WASM 的开销更大,因为它需要中断 WASM 的执行流,进入 JS 引擎的运行时环境。
最重要的结论
- WebAssembly 编程的第一原则:
最小化边界穿越,采用“粗粒度”调用而不是“细粒度”调用。
-
把频繁的、小数据的调用,重构成“块状”(Chunky)的、单次的、处理大批量数据的调用。尽量将循环移入 WASM 内部。
-
对于游戏循环、物理模拟、图像处理等场景,将核心循环和大量计算放在 WASM 内部是至关重要的。
操作步骤
- 使用
AssemblyScript编写代码生成*.wasm文件 - 由于
wasm是跨平台的,node/bun跑比浏览器跑我吞吐高个5%~8%,注意跑的时候关闭浏览器开发模式(开发者工具),这个默认开启debug会测出比实际高 20~30% 的延迟(我的Mac M1pro上是这样的数据表现)。 - 我每个线程调用
一亿次矩阵 A4×4⋅B4×4A_{4\times 4}\cdot B_{4 \times 4}A4×4⋅B4×4 运算。
跑分
单线程、JS单次调用WASM、同步循环一亿次
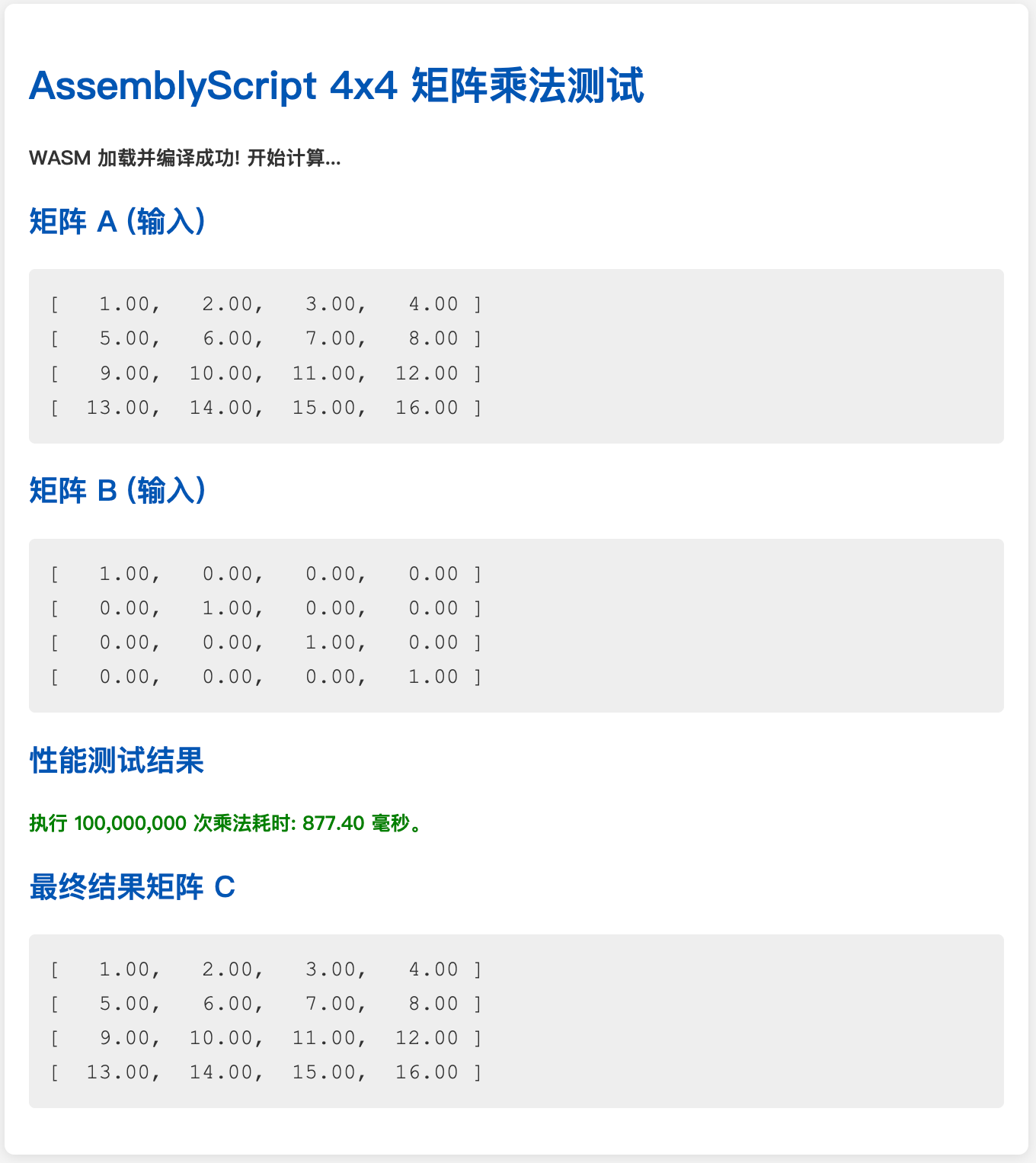
单线程、纯JS运算一亿次
- 已被V8高度优化
inline后的JS方法

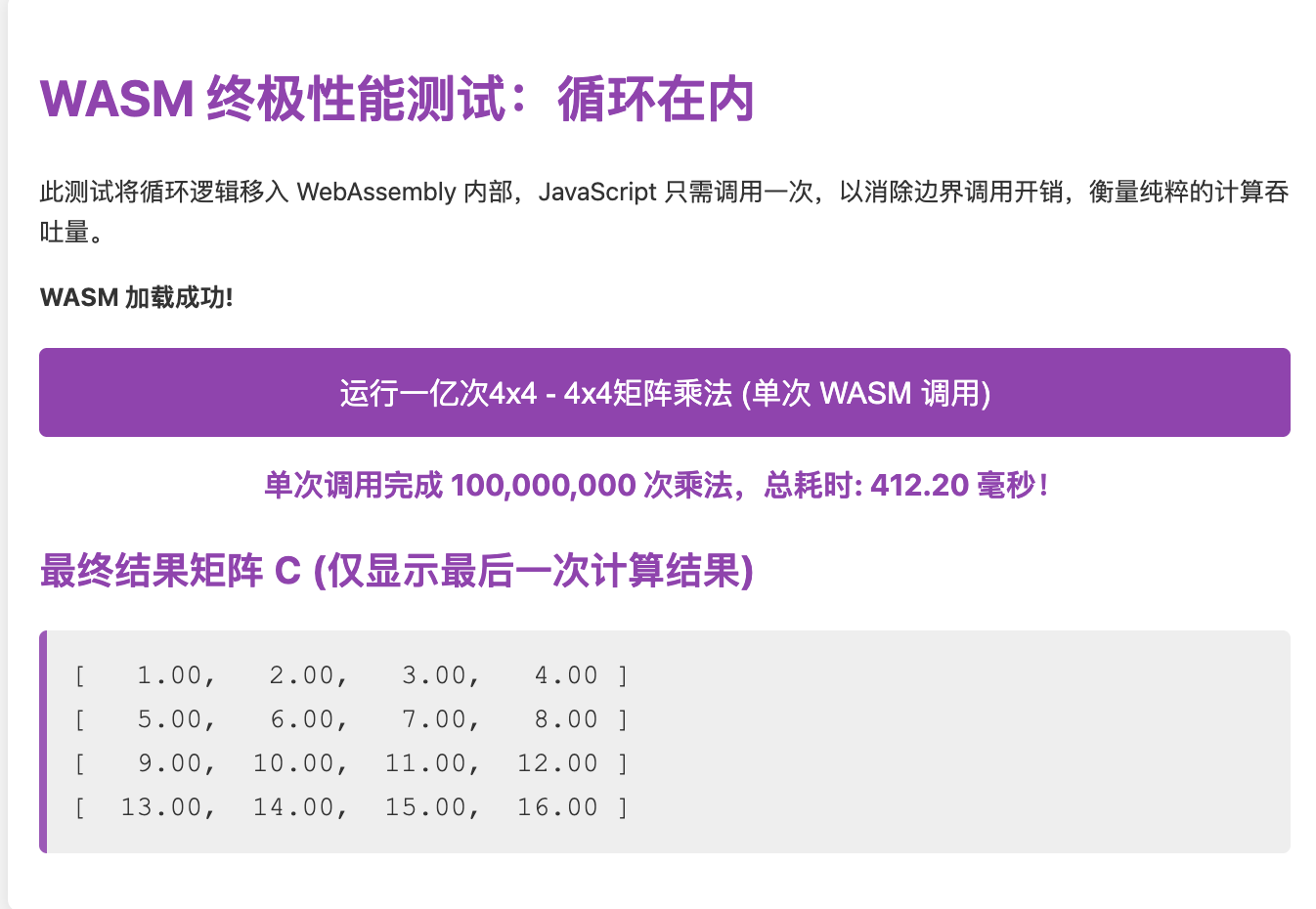
单线程、JS单次调用WASM、循环在WASM内部
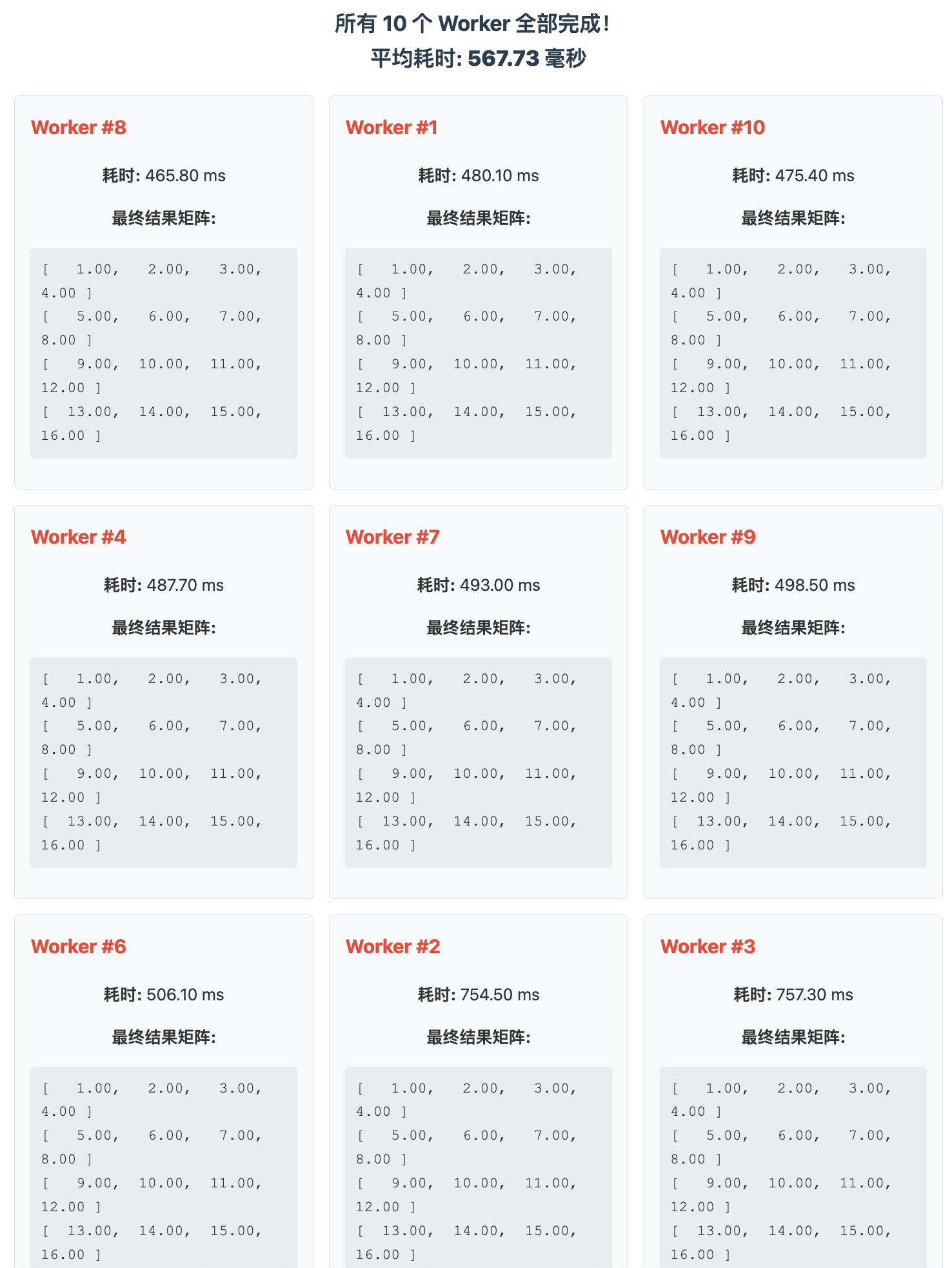
多线程、JS单次调用WASM、循环在WASM内部
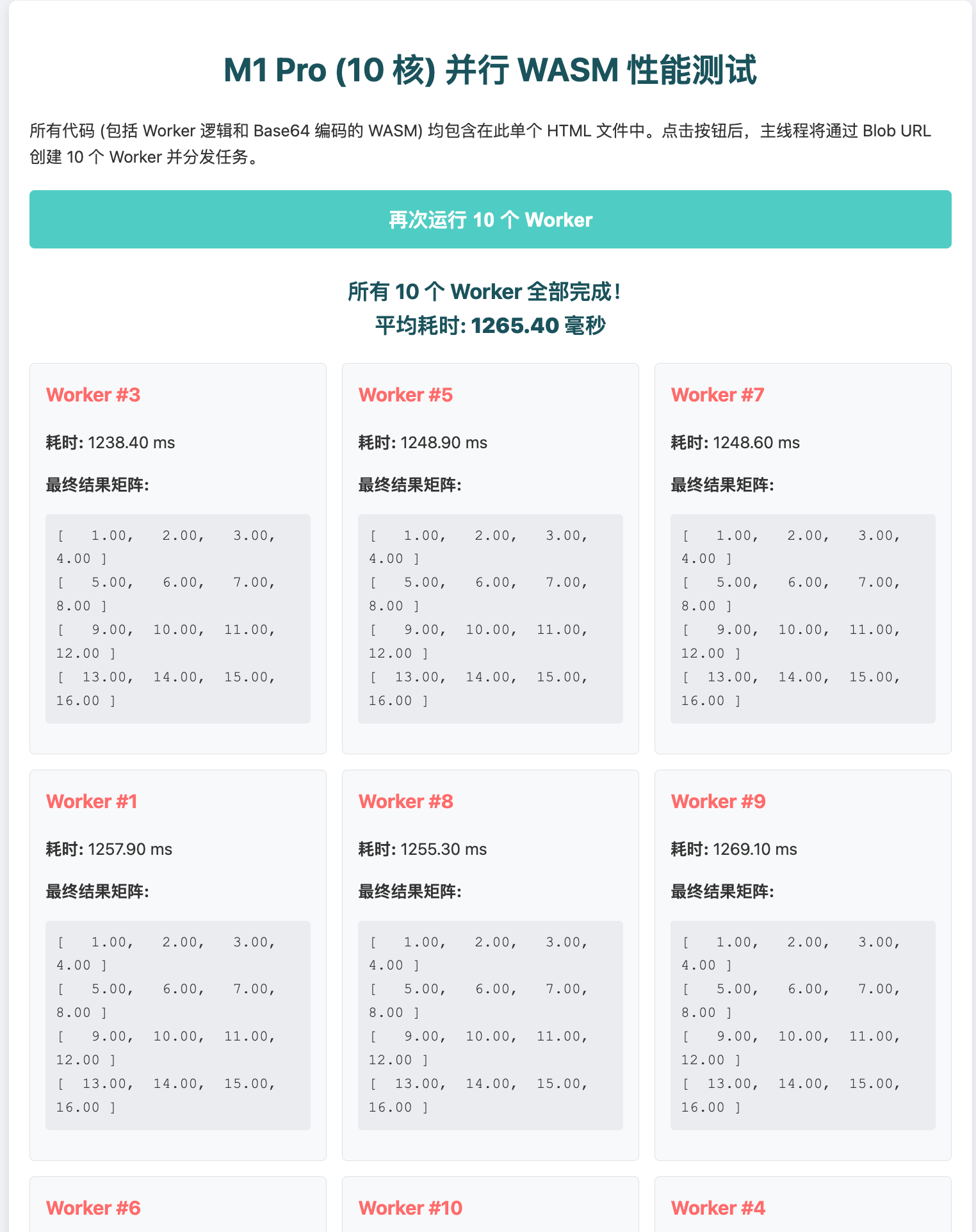
多线程、JS单次调用WASM、JS同步循环一亿次调用
项目目录结构
.
├── assembly/
│ └── index.ts # AssemblyScript 源代码
├── build/ # 编译后的 WASM 文件会在这里
├── asconfig.json # AssemblyScript 编译器配置
├── package.json # 项目依赖和脚本
└── index.js # 用于加载和测试 WASM 的 JavaScript 文件
AssemblyScript 源代码
export function multiply(
matA_ptr: usize,
matB_ptr: usize,
result_ptr: usize
): void {
const rB0 = v128.load(matB_ptr);
const rB1 = v128.load(matB_ptr + 16);
const rB2 = v128.load(matB_ptr + 32);
const rB3 = v128.load(matB_ptr + 48);
// 计算每一行
for (let i = 0; i < 4; ++i) {
const row_offset = i * 16;
// 加载A矩阵当前行的4个元素并splat成4个向量
let sA0 = f32x4.splat(f32.load(matA_ptr + row_offset));
let sA1 = f32x4.splat(f32.load(matA_ptr + row_offset + 4));
let sA2 = f32x4.splat(f32.load(matA_ptr + row_offset + 8));
let sA3 = f32x4.splat(f32.load(matA_ptr + row_offset + 12));
// 使用 relaxed_fma (如果编译器支持) 或 mul/add 链
// 这种写法能让现代编译器(如Binaryen)更好地优化,生成FMA指令
let term0 = f32x4.mul(sA0, rB0);
let term1 = f32x4.mul(sA1, rB1);
let term2 = f32x4.mul(sA2, rB2);
let term3 = f32x4.mul(sA3, rB3);
let res = f32x4.add(f32x4.add(term0, term1), f32x4.add(term2, term3));
v128.store(result_ptr + row_offset, res);
}
}
asconfig.json
{
"targets": {
"release": {
"target": "browser",
"outFile": "build/release.wasm",
"textFile": "build/release.wat",
"sourceMap": false,
"debug": false
}
},
"options": {
"bindings": "esm",
"optimizeLevel": 3,
"shrinkLevel": 1,
"noAssert": true,
"runtime": "stub",
"enable": ["simd"]
}
}

















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









