









 SIMVIT是一种新的视觉Transformer模型,它通过引入基于滑动窗口的注意力机制,解决了传统Transformer破坏局部结构和缺乏平移不变性的问题。模型使用中央自注意力来计算局部patch间的相关性,并在前三个阶段保持局部结构,第四个阶段使用标准的多头自注意力来捕获全局依赖。实验表明,SIMVIT在图像分类、检测和分割任务上表现出色,且通过消融实验验证了其设计的有效性。
SIMVIT是一种新的视觉Transformer模型,它通过引入基于滑动窗口的注意力机制,解决了传统Transformer破坏局部结构和缺乏平移不变性的问题。模型使用中央自注意力来计算局部patch间的相关性,并在前三个阶段保持局部结构,第四个阶段使用标准的多头自注意力来捕获全局依赖。实验表明,SIMVIT在图像分类、检测和分割任务上表现出色,且通过消融实验验证了其设计的有效性。
Arxiv 2112 | SIMVIT: EXPLORING A SIMPLE VISION TRANSFORMER WITH SLIDING WINDOWS

- 论文:https://arxiv.org/abs/2112.13085
- 代码:https://github.com/ucasligang/SimViT/blob/main/classification/simvit.py
- 核心改进:基于划窗计算local attention。比较类似于NAT和Stand-Alone Self-Attention in Vision Models。
现有方法的问题
- 主要针对于图像或窗口内部的token计算全局注意力,而破坏了patch之间在2D结构上的空间和局部相关性。
- 此外,由于位置编码的独特性,目前视觉Transformer缺少平移不变性(translation invariant)。
本文的工作
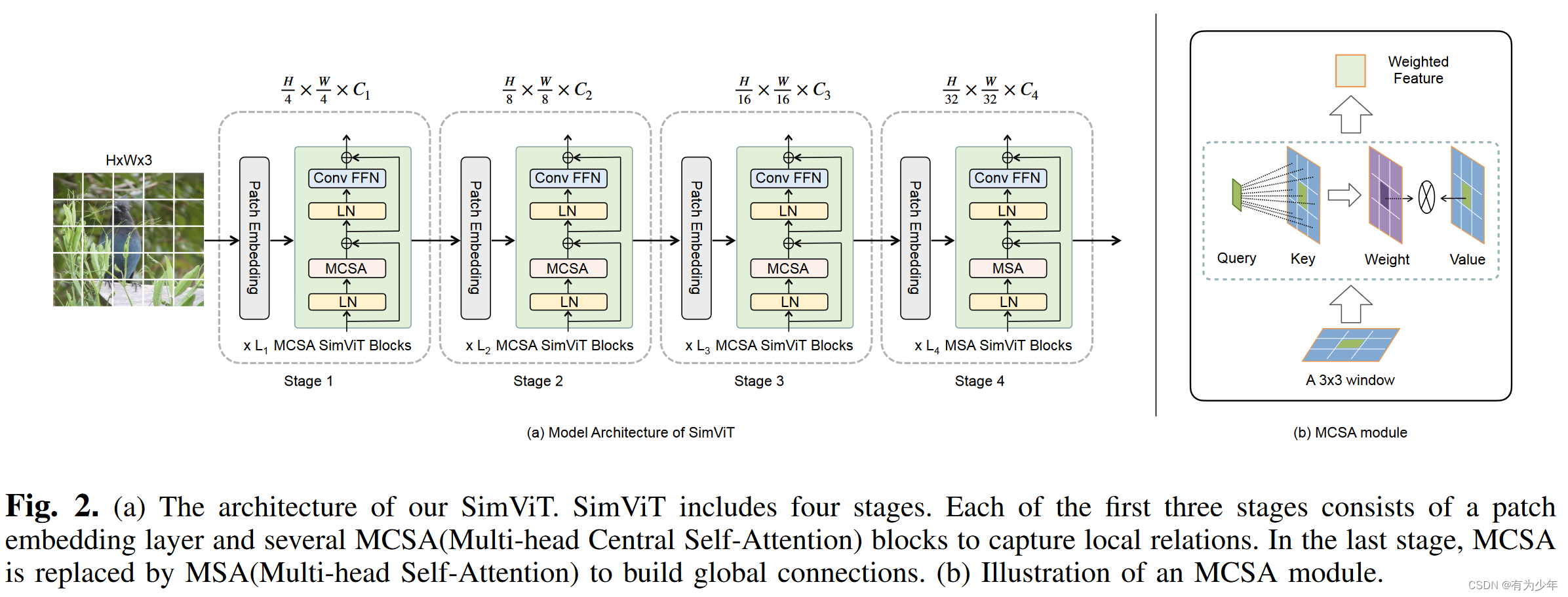
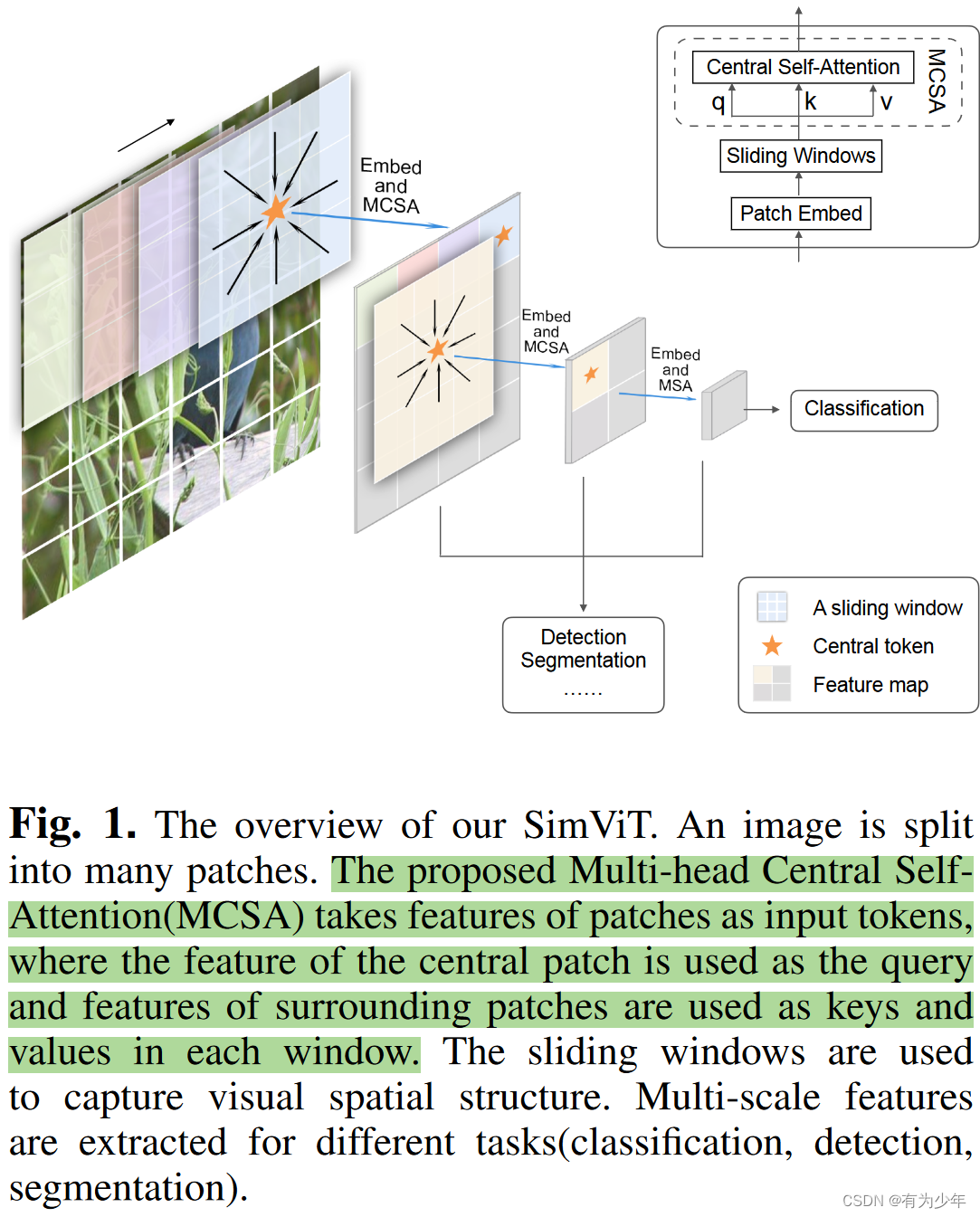
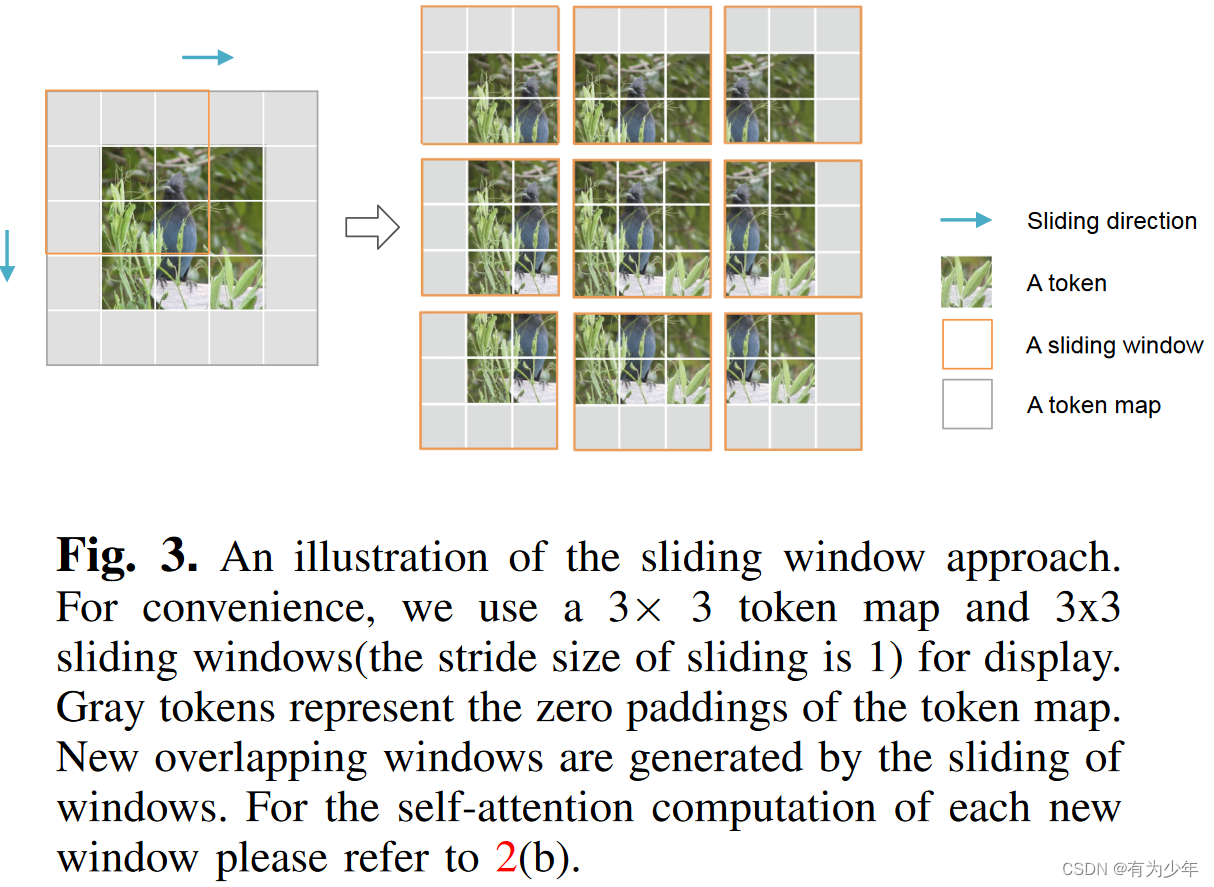
| 核心计算逻辑 | 划窗逻辑 |
|---|---|
 |  |
通过使用CNN中基于滑动窗口的层次结构带来的局部结构保留,以及Transformer中的自我注意力的信息聚集,这份工作弥合了CNN和变压器对于视觉数据建模的认知差距。
- 提出了multi-head central self-attention来替换标准的msa。
- 使用重叠划窗的形式集成空间信息和跨窗口的连接,保留局部结构。
- 每个划窗中,仅计算中间的patch与周围patch之间的相关性。
- 仅使用在前三个阶段中。第四个阶段中使用MSA被用来建立全局依赖。
- 因为交互关系本身限制在了局部范围,这可以引入平移不变性,所不再使用位置编码。
核心代码
可见这里是基于unfold操作来将k和v对应位于划窗中的token聚集到一个独立的维度上得到ks*ks, hc大小的tensor,而q则是1, hc大小,qk计算则消去hc得到1, ks*ks,qkv计算得到1, hc。
class CenterAttention(nn.Module):
def __init__(self,
dim,
num_heads=1,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
proj_drop=0.,
stride=1,
padding=True,
kernel_size=3):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.k_size = kernel_size # kernel size
self.stride = stride # stride
self.in_channels = dim
self.num_heads = num_heads
self.head_channel = dim // num_heads
# it seems that padding must be true to make unfolded dim matchs query dim h*w*ks*ks
self.pad_size = kernel_size // 2 if padding is True else 0 # padding size
self.pad = nn.ZeroPad2d(self.pad_size) # padding around the input
self.scale = qk_scale or (dim // num_heads)**-0.5
self.unfold = nn.Unfold(kernel_size=self.k_size, stride=self.stride, padding=0, dilation=1)
self.qkv_bias = qkv_bias
self.q_proj = nn.Linear(dim, dim, bias=qkv_bias)
self.kv_proj = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.softmax = nn.Softmax(dim=-1)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.reshape(B, H, W, C)
assert C == self.in_channels
self.pat_size_h = (H+2 * self.pad_size-self.k_size) // self.stride+1
self.pat_size_w = (W+2 * self.pad_size-self.k_size) // self.stride+1
self.num_patch = self.pat_size_h * self.pat_size_w
# (B, NumHeads, H, W, HeadC)
q = self.q_proj(x).reshape(B, H, W, self.num_heads, self.head_channel).permute(0, 3, 1, 2, 4)
# query need to be copied by (self.k_size*self.k_size) times
q = q.unsqueeze(dim=4)
q = q * self.scale
# if stride is not 1, q should be masked to match ks*ks*patch
# (2, B, NumHeads, HeadsC, H, W)
kv = self.kv_proj(x).reshape(B, H, W, 2, self.num_heads, self.head_channel).permute(3, 0, 4, 5, 1, 2)
kv = self.pad(kv) # (2, B, NumH, HeadC, H, W)
kv = kv.permute(0, 1, 2, 4, 5, 3) # (2, B, NumH, H, W, HeadC)
H, W = H + self.pad_size * 2, W + self.pad_size * 2
# unfold plays role of conv2d to get patch data
kv = kv.permute(0, 1, 2, 5, 3, 4).reshape(2 * B, -1, H, W) # (2*B, NumH*HeadC, H, W)
kv = self.unfold(kv)
kv = kv.reshape(2, B, self.num_heads, self.head_channel, self.k_size**2,
self.num_patch) # (2, B, NumH, HC, ks*ks, NumPatch)
kv = kv.permute(0, 1, 2, 5, 4, 3) # (2, B, NumH, NumPatch, ks*ks, HC)
k, v = kv[0], kv[1]
# (B, NumH, NumPatch, 1, HeadC)
q = q.reshape(B, self.num_heads, self.num_patch, 1, self.head_channel)
attn = (q @ k.transpose(-2, -1)) # (B, NumH, NumPatch, 1, ks*ks)
attn = self.softmax(attn) # softmax last dim
attn = self.attn_drop(attn)
out = (attn @ v).squeeze(3) # (B, NumH, NumPatch, HeadC)
out = out.permute(0, 2, 1, 3).reshape(B, self.pat_size_h, self.pat_size_w, C) # (B, Ph, Pw, C)
out = self.proj(out)
out = self.proj_drop(out)
out = out.reshape(B, -1, C)
return out
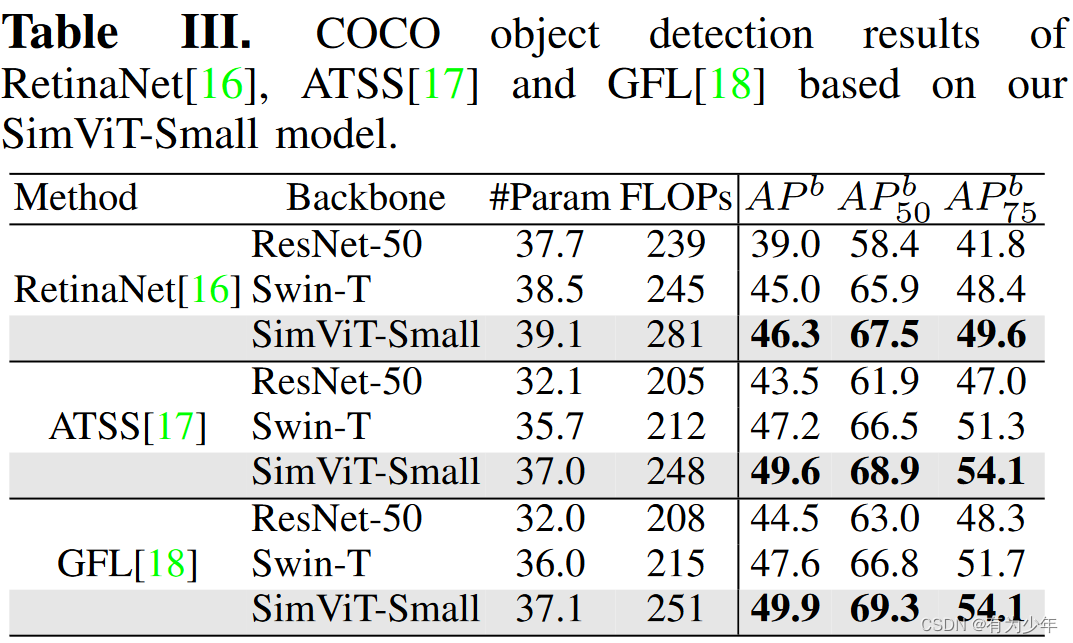
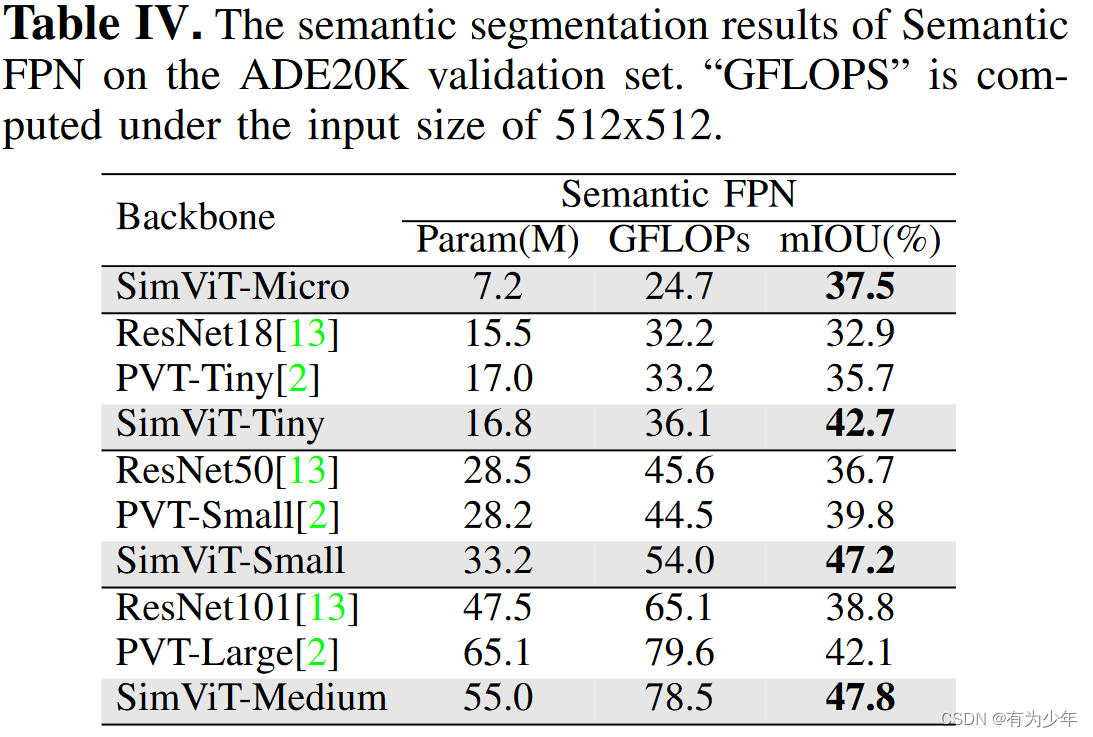
实验结果

对比实验
| 分类 | 检测 | 分割 |
|---|---|---|
 |  |  |
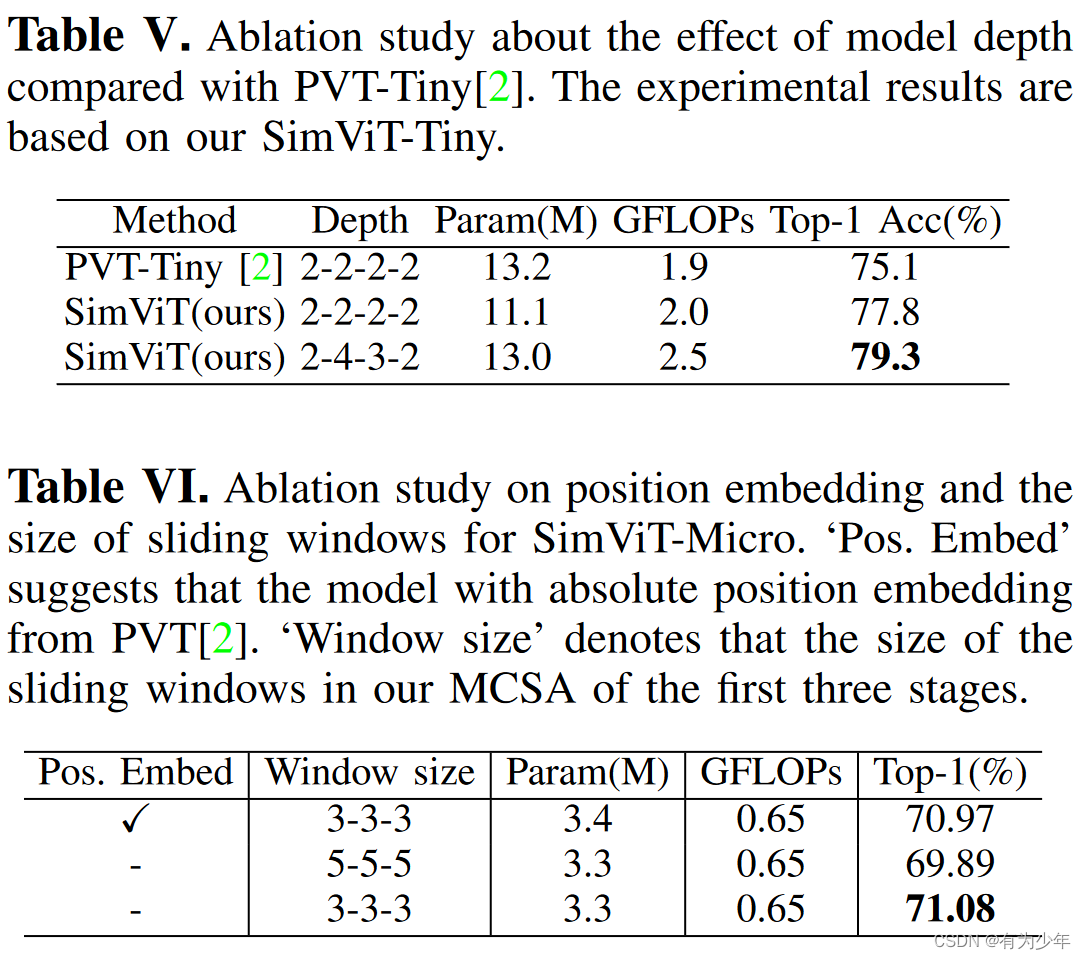
消融实验

















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









