AAAI 2022 - LIT: Less is More: Pay Less Attention in Vision Transformers

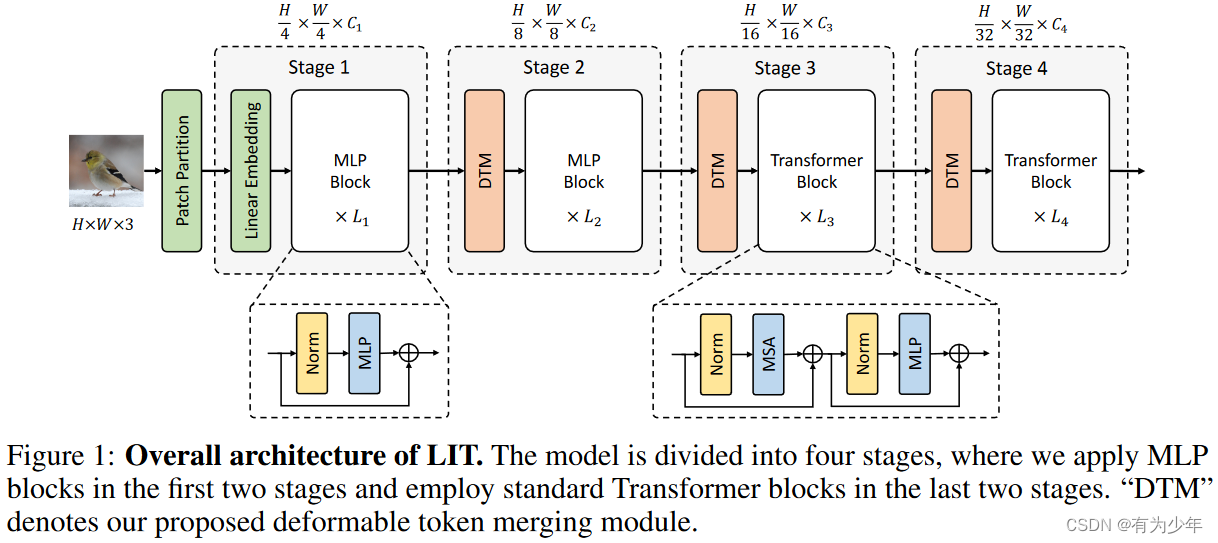
主要内容

- 模型早期使用纯MLP编码丰富的局部模式,而后期使用标准自注意力模块捕获长距离依赖关系。
- 这样在早期可以避免过高的计算成本和内存占用,深层中又可以完整的保留长距离依赖处理的能力,同时基于金字塔架构的形式也可以保持一个较为温和的FLOPs。
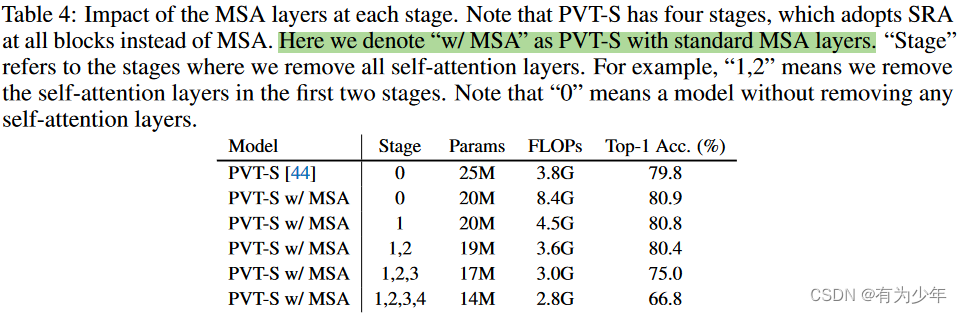
- 图3中也可以看到,PVT-S(这里将PVT-S中的MSA都替换成了标准的MSA,即表4中第2个模型)浅层中的MSA中仅会关注到query像素附近的很小的局部区域,这也说明了早期阶段的对于长距离关系的需求并不大。按照表4中的实验可以知道,早期的MSA移除了也不会带来太多的性能损失。
- 将可变形卷积引入patch merging层中,来自适应地以非均匀采样的方式融合可以提供有用信息patch。
class DeformablePatchEmbed_GELU(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.c_in = in_chans
self.c_out = embed_dim
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.dconv = DeformConv2dPack(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size, padding=0)
self.norm_layer = nn.BatchNorm2d(embed_dim)
self.act_layer = nn.GELU()
for m in self.modules():
if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x, return_offset=False):
B, C, H, W = x.shape
x, offset = self.dconv(x, return_offset=return_offset)
x = self.act_layer(self.norm_layer(x)).flatten(2).transpose(1, 2)
H, W = H // self.patch_size[0], W // self.patch_size[1]
if return_offset:
return x, (H, W), offset
else:
return x, (H, W)
实验结果











 LIT通过在早期阶段采用纯MLP减少计算成本,在后期使用标准MSA捕捉长距离依赖,结合可变形卷积改进patch merging,实现了高效且性能优秀的视觉Transformer。
LIT通过在早期阶段采用纯MLP减少计算成本,在后期使用标准MSA捕捉长距离依赖,结合可变形卷积改进patch merging,实现了高效且性能优秀的视觉Transformer。


















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









