 KMP算法:匹配、循环节与公共子串
KMP算法:匹配、循环节与公共子串





KPKPKMP
KMP算法
真のKMP算法
在线性时间复杂度内匹配字符串(判断串BBB是否是串AAA的子串,并找出串BBB在串AAA中出现的位置)。
暴力匹配方法:
把BBB的第一位与AAA的每一位进行比较,若匹配则继续向后比较,否则将BBB后移一位。
时间复杂度:O(n2)O(n^2)O(n2)
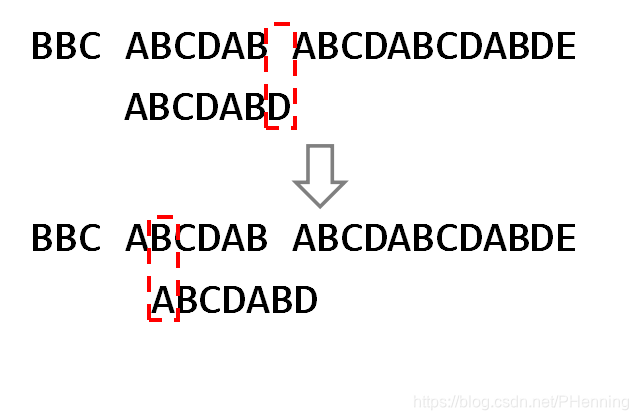
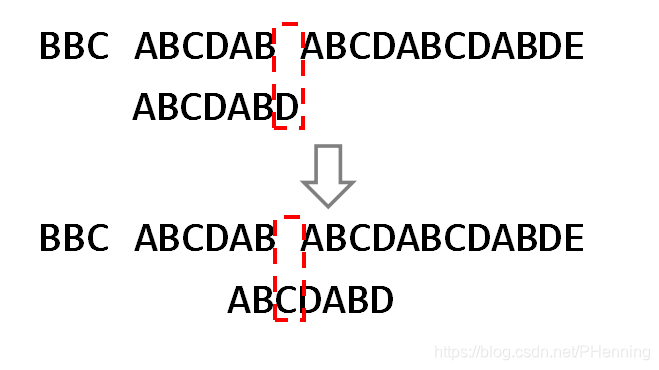
当比较到BBB的某个位置与AAA不匹配时,这个位置前的部分已经被比较过了,若继续逐个比较就会导致效率极低。效率高的做法是,若BBB的某个前缀在已匹配部分的其它位置出现过(如图中的"AB"),可以直接将BBB移至这些位置;否则已匹配部分中的字符都不可能与BBB的首字符匹配,直接跳过。
而KMP算法通过针对BBB计算出一张回退表来实现这个过程。
| 搜索词BBB | A | B | C | D | A | B | D |
|---|---|---|---|---|---|---|---|
| 回退表failfailfail | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
串BBB中每个位置的回退值就是当前已匹配部分的前缀与后缀集合中最长相同元素的长度。例如"ABCDABD"中第六位的回退值为222,因为"ABCDAB"的前缀与后缀集合中最长相同元素为"AB",其长度为222。
根据回退表,移动位数===已匹配的字符数−-−对应的回退值。
记两个串长度分别为n,mn,mn,m。分别给串A,BA,BA,B两个指针i,ji,ji,j,始终满足BBB的前jjj个字符正好匹配AAA的以A[i]A[i]A[i]结尾的长度为jjj的子串,即B[1…j]B[1\dots j]B[1…j]与A[i−j+1…i]A[i-j+1\dots i]A[i−j+1…i]匹配。
- 若A[i+1]=B[j+1]A[i+1]=B[j+1]A[i+1]=B[j+1],则可以增加i,ji,ji,j的值,继续往后比较。若某个时候j=mj=mj=m,说明BBB是AAA的字串。
- 若A[i+1]≠B[j+1]A[i+1]\neq B[j+1]A[i+1]̸=B[j+1],则将jjj改为fail[j]fail[j]fail[j],相当于BBB向右移动了j−fail[j]j-fail[j]j−fail[j]位。
如何求串BBB的failfailfail数组?显然fail[1]=0fail[1]=0fail[1]=0。然后从i=2i=2i=2开始,拿两个BBB串进行KMP,一边匹配一边记下每个位置的回退值。因为iii始终大于jjj,当jjj需要改为fail[j]fail[j]fail[j]时,fail[1…j]fail[1\dots j]fail[1…j]都已经算好了。
时间复杂度:O(n)O(n)O(n)
void kmp(char *a,char *b,int *fail){
int n=strlen(s+1),m=strlen(b+1);
for(int i=2,j=0;i<=m;i++){
while(j&&b[j+1]!=b[i])j=fail[j];
if(b[j+1]==b[i])j++;fail[i]=j;
}
for(int i=1,j=0;i<=n;i++){
while(j&&b[j+1]!=a[i])j=fail[j];
if(b[j+1]==a[i])j++;
if(j==m){cout<<i-m+1<<endl;j=fail[j];}
}
}
求最短循环节
failfailfail数组有一个奇妙的性质:对于长度为lenlenlen的字符串,其最短循环节长度为len−fail[len]len-fail[len]len−fail[len]。
但这样算出的循环节可能在原串中是不完整的。例如"ABCAB"算出的最短循环节为"ABC",长度为333。所以有些题目需要特判。
求最长公共子串
利用KMP可以在O(nL2)O(nL^2)O(nL2)的时间内求nnn个长度不超过LLL的字符串的最长公共子串的长度。原因是在匹配过程中,BBB串的长度为jjj的前缀会一直是AAA串的子串。随便取一个串,枚举这个串的后缀,把这个后缀与其它的串进行KMP,每个串记录匹配过程中出现过的最大的jjj,取被匹配的每个串的最小值,再取匹配串每个后缀的最大值。

















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









