



模型训练的一般理解:
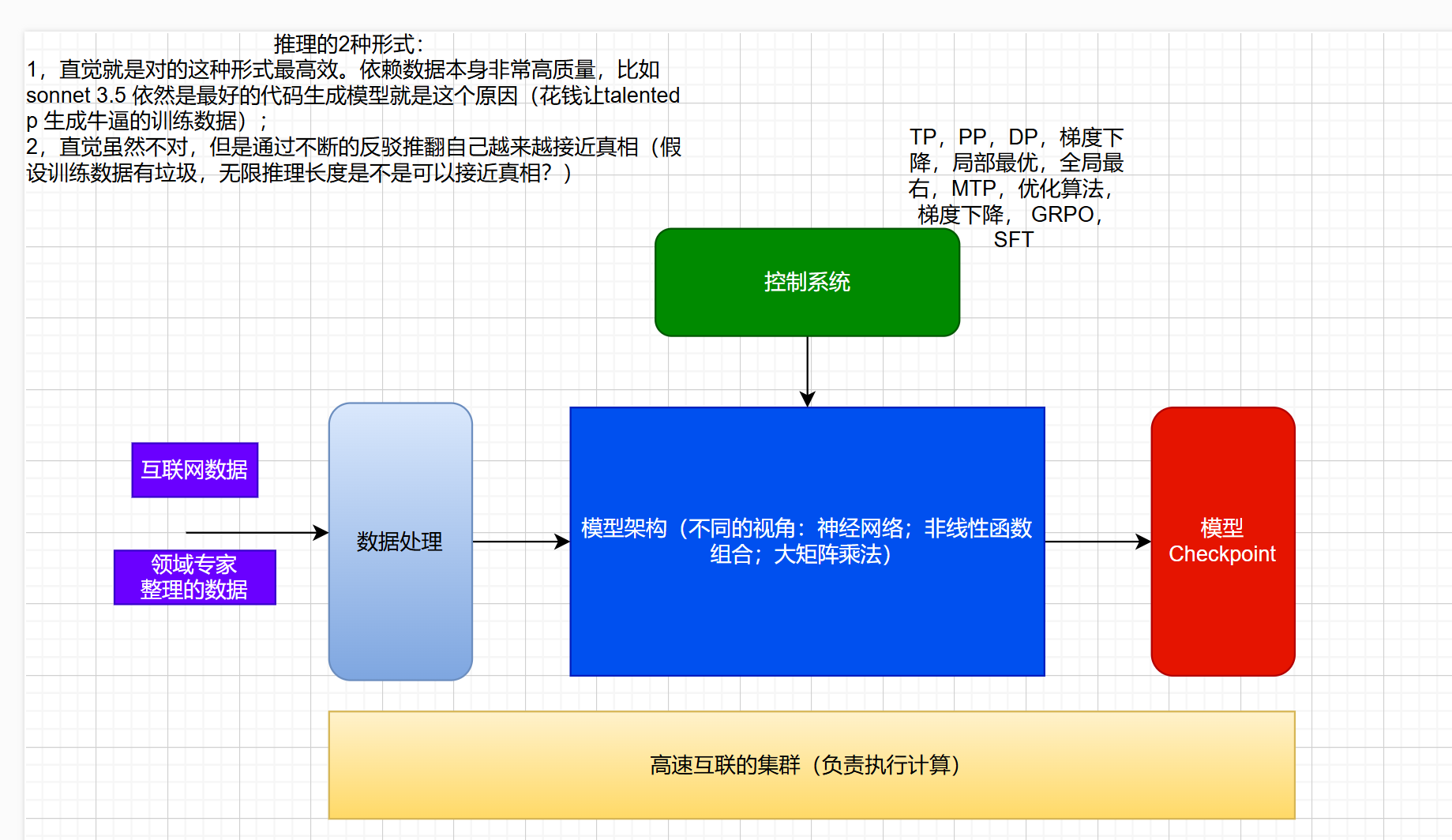
R1-Zero, R1 的训练过程:
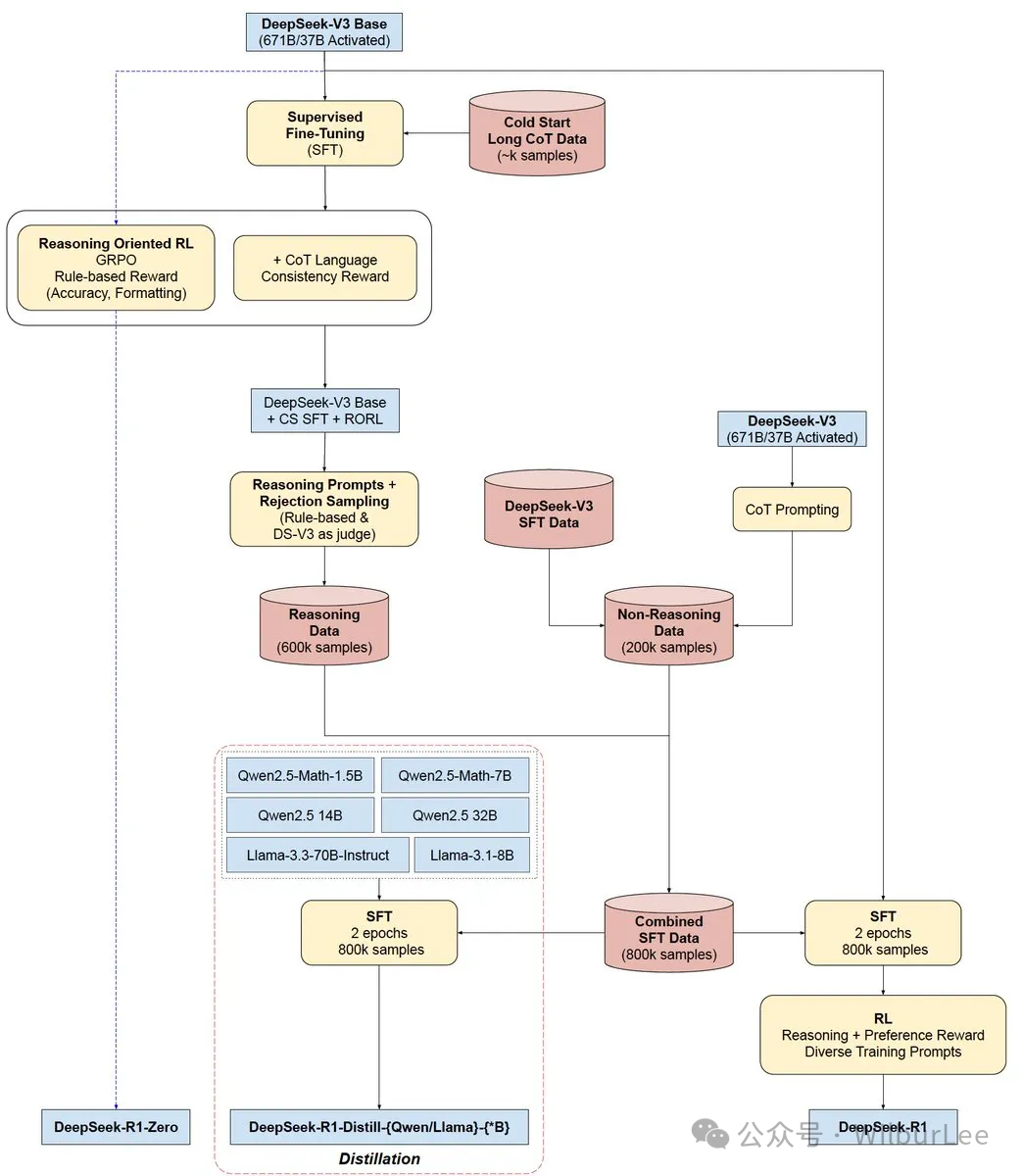
从V3到R1-Zero只采用来的RL训练,按照DeepSeek-V3 的技术报告预估V3最后训练耗费560万美元左右,R1-Zero RL 后训练过程费用应该10万美元左右,目前看ROI非常高。
以下Notebook 是 Qwen 0.5b on GRPO 的改进版本,可以在4090 上体验DeepSeek-R1-Zero的RL训练过程。
jupyter notebook 文件:📎GRPO.ipynb. 或从github 下载代码:
git clone git clone https://github.com/OneThingAI/ahamoment.git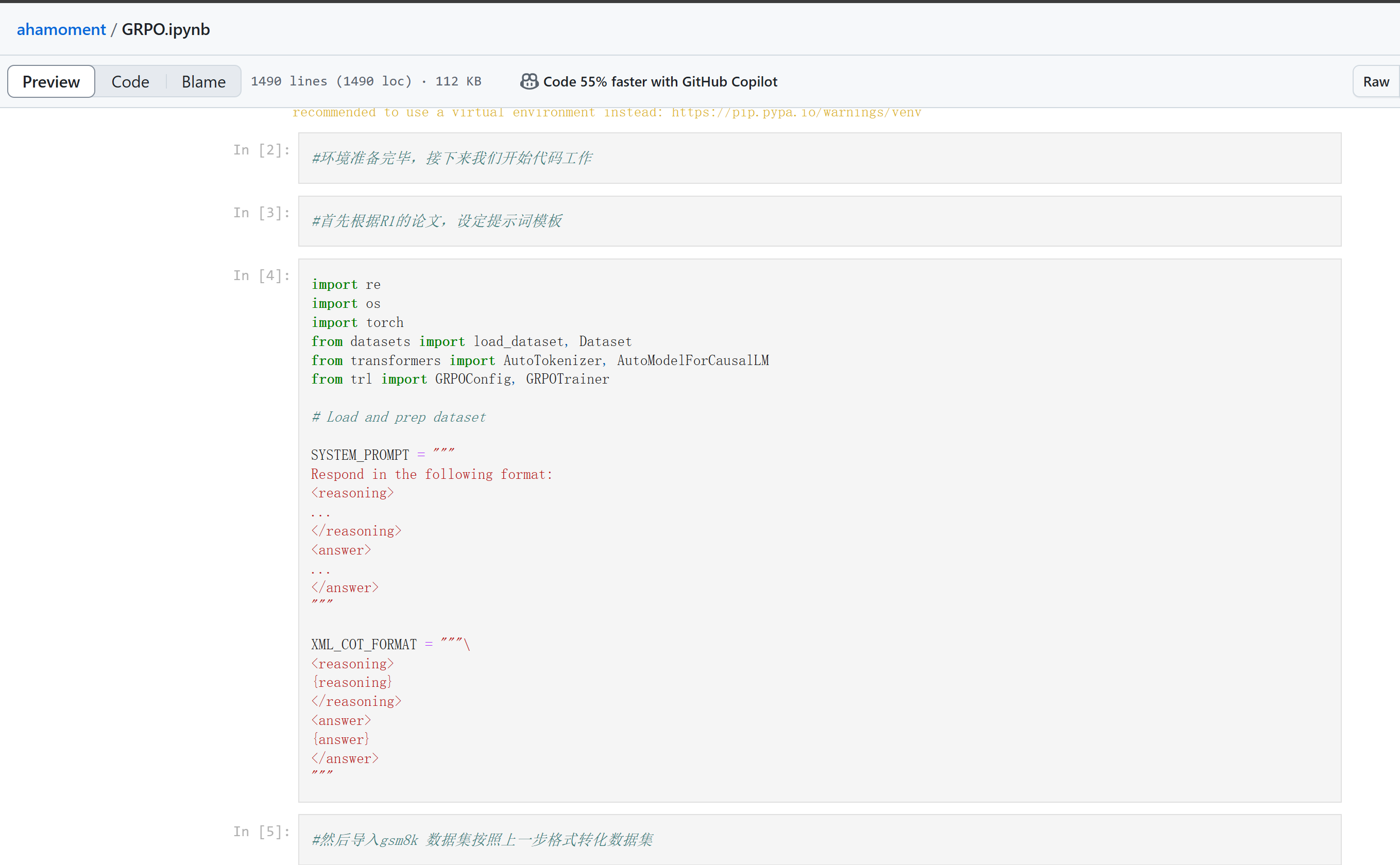
复现(细节论文见 论文):


1,创建vLLM 实例:
点击顶部导航栏中【镜像中心】官方镜像,点击更多镜像,选择LLM推理引擎官方版:V1,进行创建实例
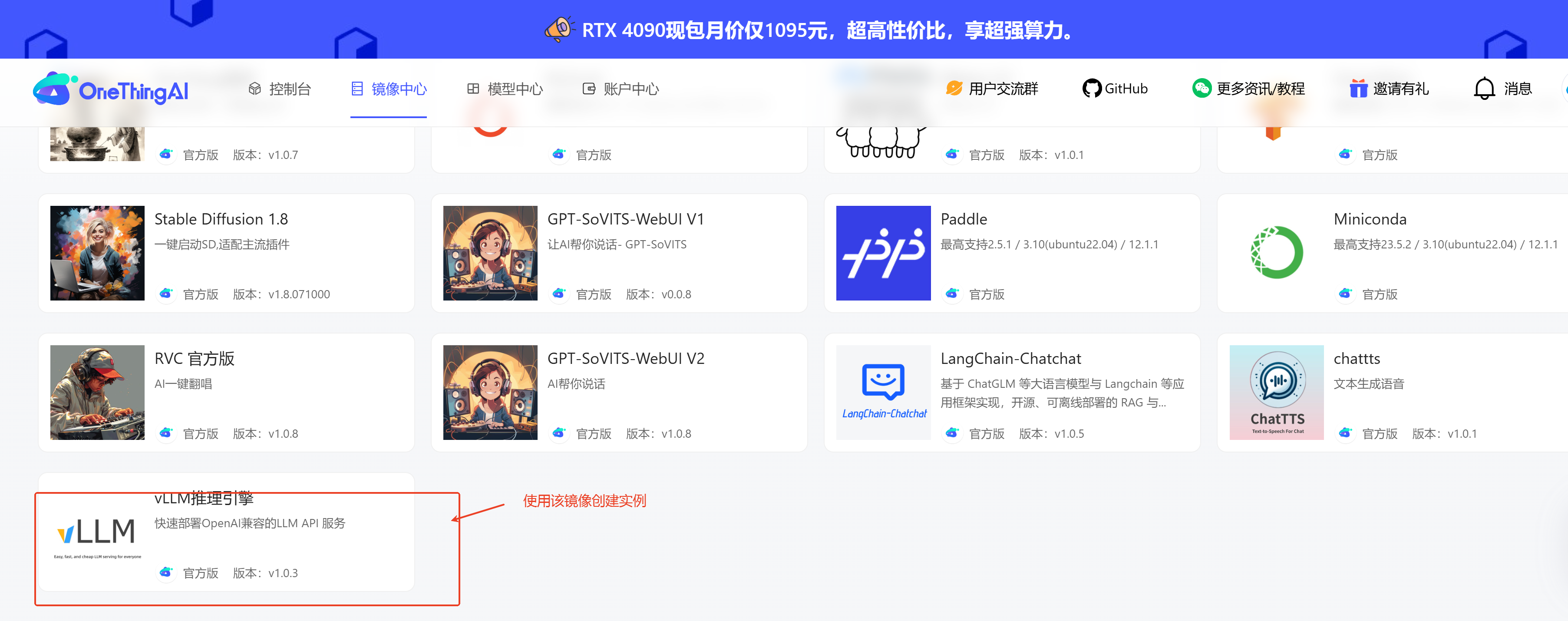
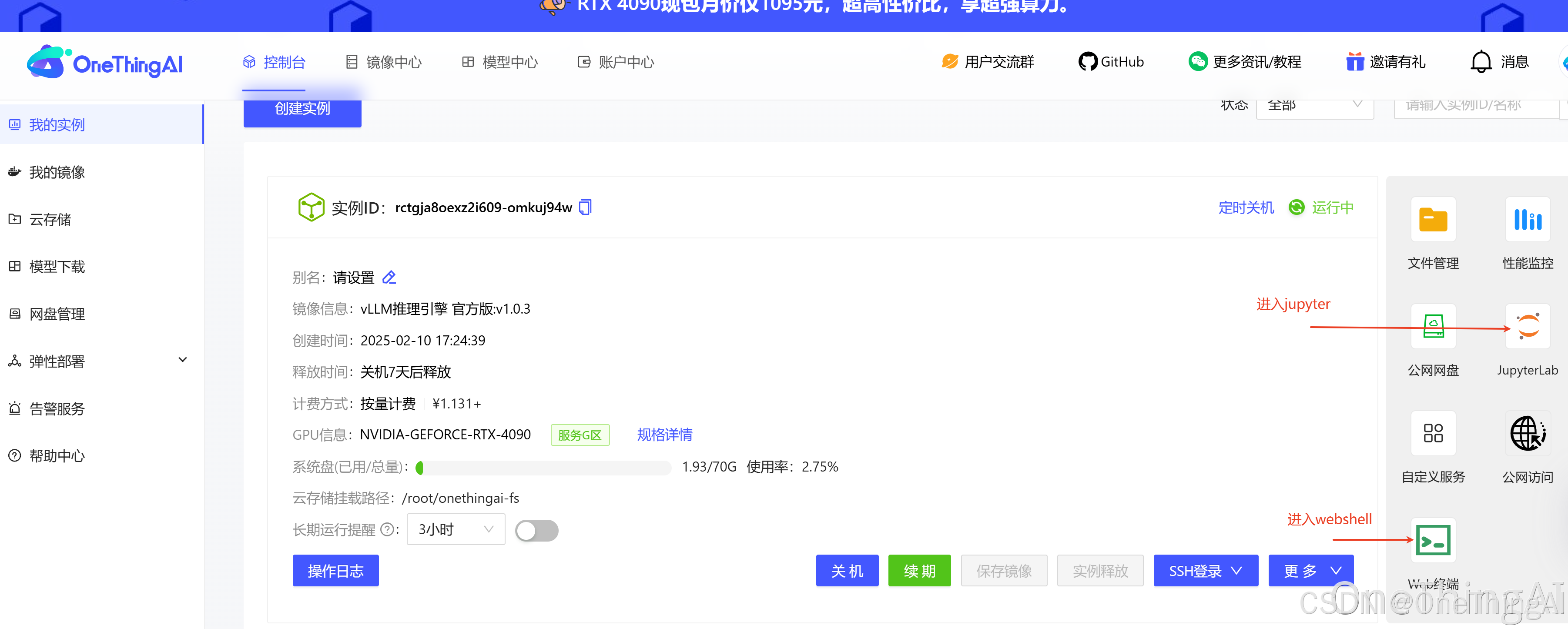
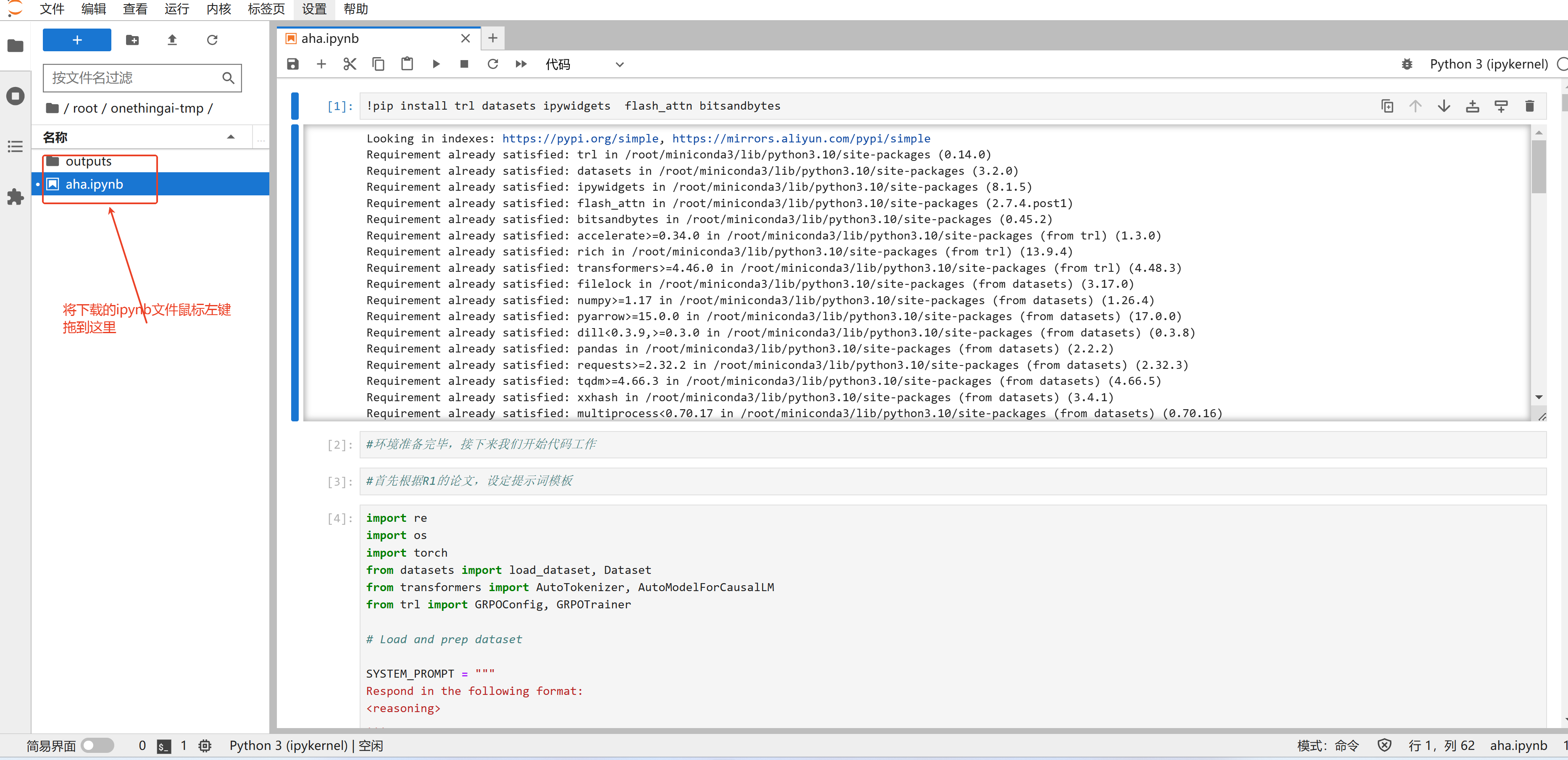
2、实例运行状态下,打开jupyter,上传notebook文件将下载好的
jupyter notebook 文件:📎GRPO.ipynb.
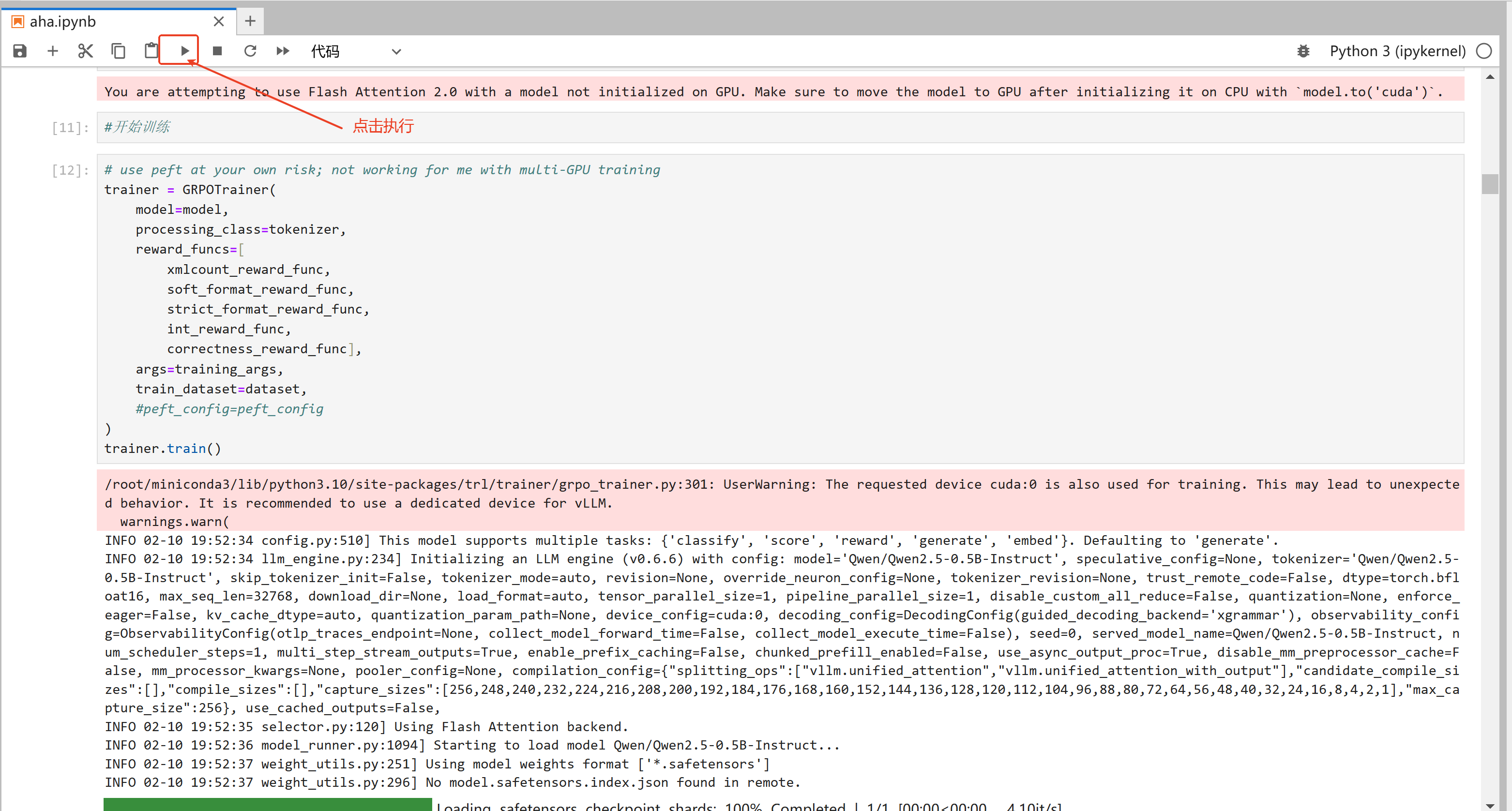
3,执行
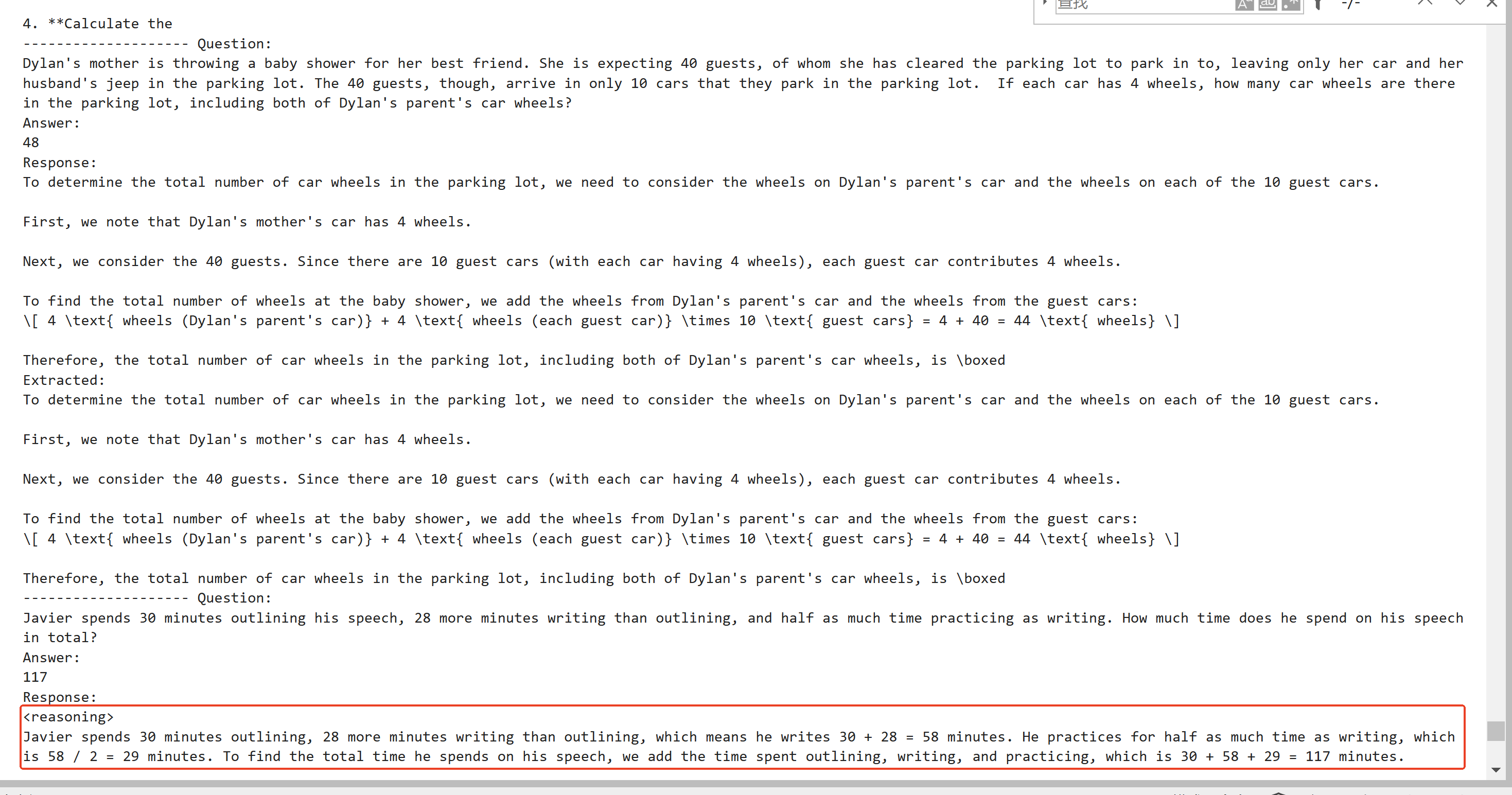
4, 观察输出结果


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









