




Abstract
贡献:
提出了Transformer,完全基于注意力机制,摒弃了循环和卷积网络。
结果:
本模型在质量上优于现有模型,同时具有更高的并行性,并且显著减少了训练时间。
1. Introduction
- long short-term memory(LSTM)——长短期记忆网络
- gated recurrent neural networks——门控循环神经网络
循环模型通常沿着输入和输出序列的符号位置来分解计算。通过将位置与计算时间步骤对齐,它们生成一系列隐藏状态 ht,作为前一个隐藏状态 ht−1 和位置 t 的输入的函数。
Transformer完全摒弃循环网络、完全依赖注意力机制来捕捉输入和输出之间全局依赖关系的模型架构。
显著允许增加并行化。
2. Background
减少序列计算。
- Extended Neural GPU
- ByteNet
- ConvS2S
在这些模型中,关联任意两个输入或输出位置信号所需的操作次数随着位置之间的距离而增加。
Self-attention,是一种通过关联同一序列中不同位置来计算该序列表示的注意力机制。
End-to-end memory networks,基于一种循环注意力机制,而不是与序列对齐的循环网络。
Transformer是第一个完全依赖自注意力来计算输入和输出表示的转换模型,没有使用与序列对齐的RNN或卷积网络。
3. Model Architecture
编码器输入x,输出z;解码器输入z,输出y。
在每一步,模型都是自回归的,在生成下一步时,使用先前生成的符号作为附加输入。
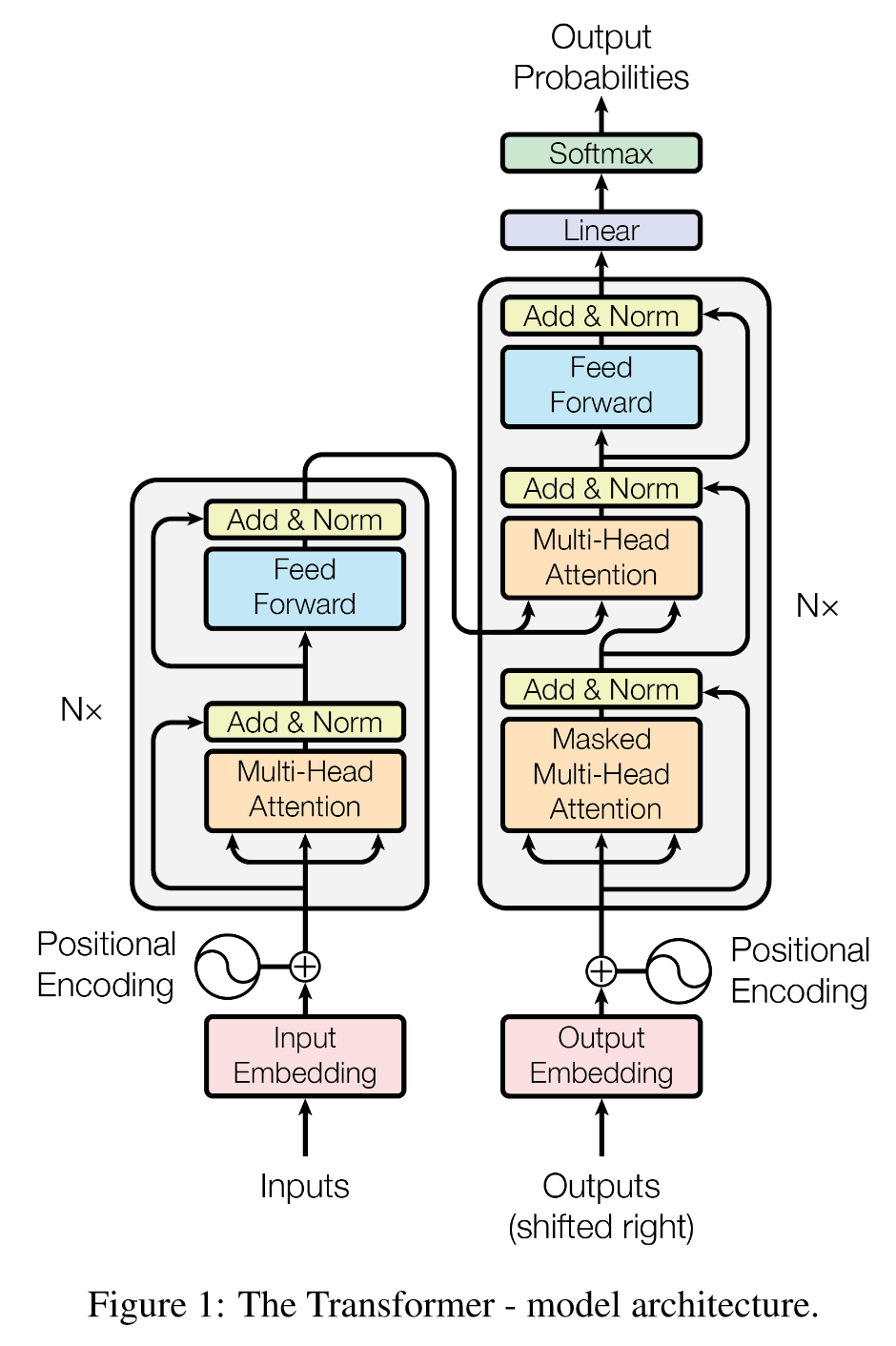
3.1 Encoder and Decoder Stacks
编码器:
N=6,每个两层。
第一层,多头自注意力机制;
第二层,逐位置全连接前馈网络。
残差连接,层归一化,即:LayerNorm(x + Sublayer(x))。
维度dmodel=512d_{model} = 512dmodel=512。
解码器:
N=6,每个三层。
二三层同上。
第一层,掩码多头自注意力机制。
这种掩码机制结合输出嵌入偏移一个位置,确保位置 i 的预测只能依赖于位置 i 之前已知的输出。
3.2 Attention
注意力函数可以描述为将查询(query)和一组键-值对(key-value pairs)映射到一个输出,其中查询、键、值和输出都是向量。
输出是根据值(value)的 加权和 计算得到的,权重是通过查询(query)与相应键(key)之间的兼容性函数计算得出的。
3.2.1 Scaled Dot-Product Attention——缩放点积注意力
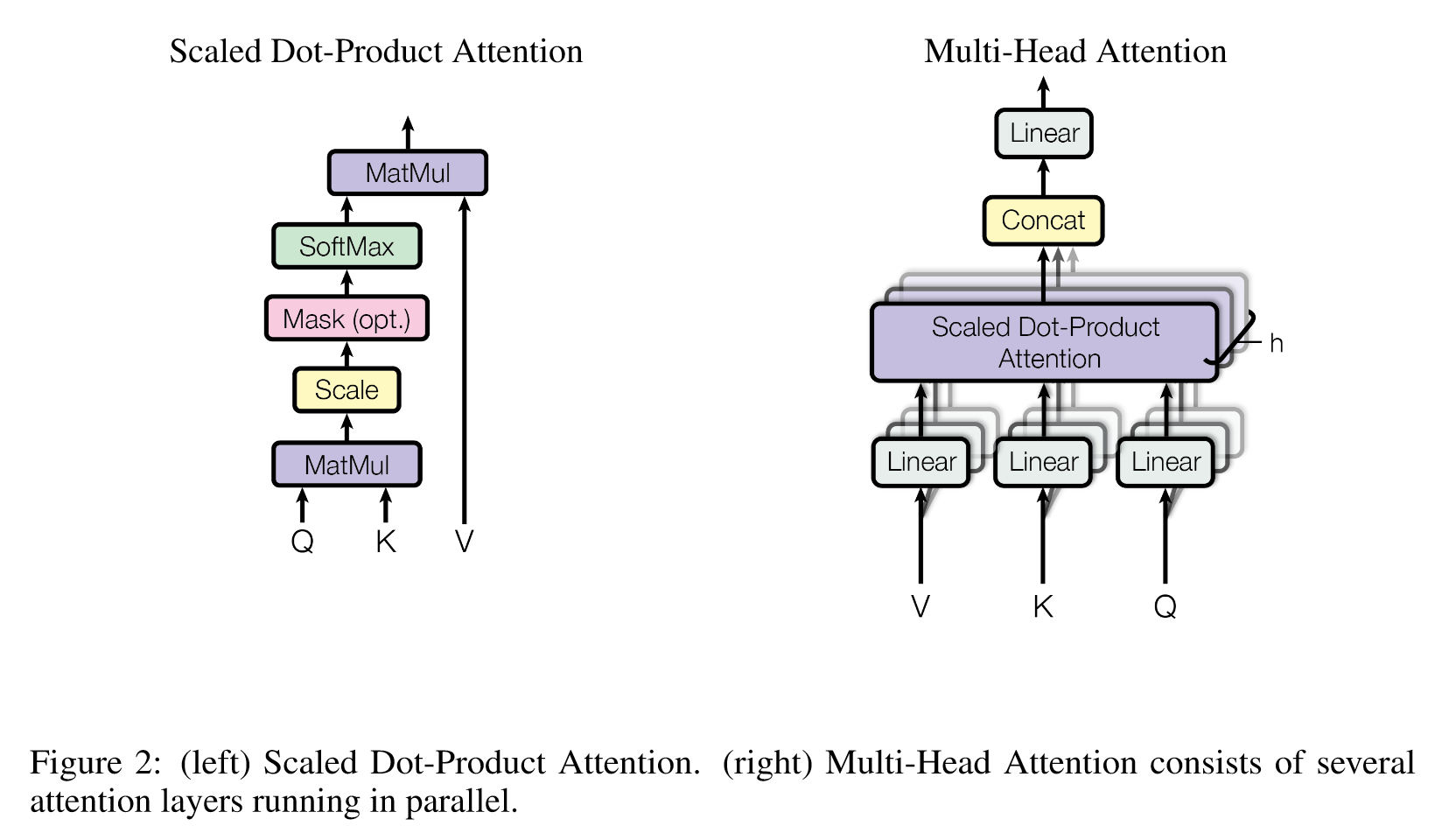
输入由维度为 dk 的查询和键以及维度为 dv 的值组成,计算查询与所有键的点积,将每个点积除以 dk\sqrt{d_k}dk,并应用 softmax 函数以获得值的权重。
在实际应用中,会同时对一组查询计算注意力函数,使用矩阵计算。
输出矩阵:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
- 加性注意力
- 点积注意力
对于较大的 dk 值,如果没有缩放,点积的数值可能会变得很大,从而将 softmax 函数推入梯度极小的区域,所以缩放dk\sqrt{d_k}dk 。
为什么选择 dk\sqrt{d_k}d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 346
346



 到【灌水乐园】发言
到【灌水乐园】发言








