






Abstract
背景:
AI在介入性图像分析中的潜在应用仍未被充分挖掘。在实时手术过程中收集的数据进行事后分析存在根本性和实践性的限制,包括伦理考虑、成本、可扩展性、数据完整性以及缺乏真实基准。
工作:
1、展示了一种从人体模型中创建逼真模拟图像的可行方案,作为大规模原位数据收集的替代和补充。
2、 创建X射线图像分析模型迁移范式——称为SyntheX。
贡献:
1、 证明通过在现实合成的数据上训练AI图像分析模型,并结合当代领域泛化技术,能够在真实数据上获得与精确匹配的真实数据训练集相当的表现。
2、 SyntheX甚至能够超越基于真实数据训练的模型,显著加速基于X射线的智能系统的构思、设计和评估提供了机会。
- 真实数据与仿真数据之间的特性差异通常被称为“领域差距”
- AI模型在来自不同领域的数据上表现的能力,即与其训练数据存在领域差距的情况,被称为“领域泛化”。
- 迄今为止尚无研究使用精确匹配的跨领域数据集来孤立领域泛化的影响。
SyntheX框架,该框架旨在开发基于合成数据的通用人工智能算法,用于X射线图像分析,这些合成数据完全由标注的计算机断层扫描(CT)模拟生成。通过从CT中模拟真实的X射线图像生成过程,并利用领域随机化技术训练AI模型,SyntheX创建的AI模型能够在领域转移时保持性能,从而实现对真实世界临床X射线的评估与部署。
Clinical tasks
在三项X射线图像分析下游任务中展示了SyntheX的优势:髋部成像、手术机器人工具检测以及胸部X射线中的COVID-19病灶分割。
Hip imaging——髋骨成像
实现空间对齐的一种有效方法是识别2D X射线图像中的已知结构和标志,然后用于推断姿态。
在髋部成像中,我们定义了六个解剖结构和十四个标志作为最相关的已知结构。它们如图2a所示。
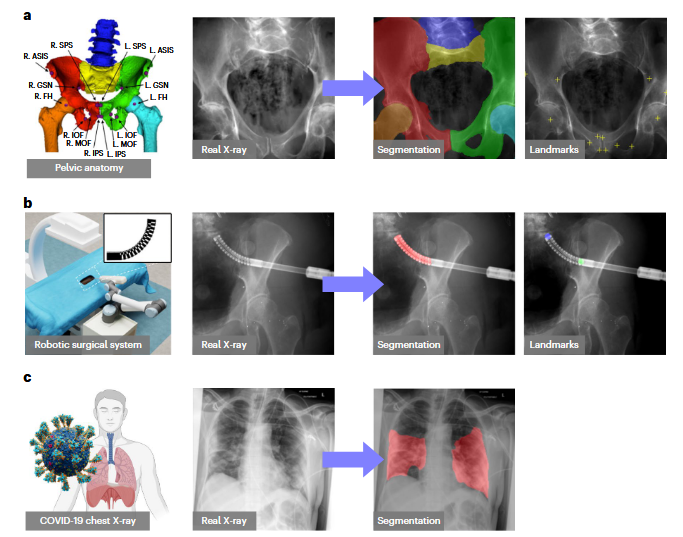
Surgical robotic tool detection——手术机器人工具检测
从术中图像中自动检测手术工具是机器人辅助手术的重要步骤。
由于训练检测模型需要足够且带有真实标签的图像数据,因此只有在手术机器人成熟并投入临床使用后,才能开发此类模型。
我们以连续体机械臂(CM)为目标对象。通过使用SyntheX,我们解决了CM检测问题,包括分割CM主体并在X射线图像中预测特定标志点。语义分割掩码覆盖了27个交替的凹槽,以区分CM与其他手术工具;标志点定义为CM中心线的起点和终点。
COVID-19 lesion segmentation——COVID-19 病变分割
胸部X光(CXR)已成为辅助COVID-19诊断和指导治疗的重要工具。
我们考虑了COVID-19病变分割任务,该任务也可以从CXR中实现以进行比较。我们使用了ImagEng lab发布的开源COVID-19 CT数据集以及电子科技大学(UESTC)发布的CT扫描数据来生成合成CXR图像。
使用自动病变分割方法COPLE-Net为每个CT创建了3D感染掩码。我们遵循了相同的真实X射线合成流程,并使用来自不同几何形状的配对CT扫描和分割掩码生成了合成图像和标签。病变标签按照相同的几何形状进行投影。
Precisely controlled investigations on hip imaging——精准控制的髋关节影像研究
针对一个独特的髋关节影像数据集进行了实验,以分离邻域差距对Sim2Real AI模型迁移的影响。
在髋关节X射线的解剖标志点检测和解剖分割任务中,我们研究了最常用的邻域泛化技术,即域随机化和域适应,并进一步考虑了不同的X射线模拟器、图像分辨率和训练数据集大小。
Precisely matched hip dataset
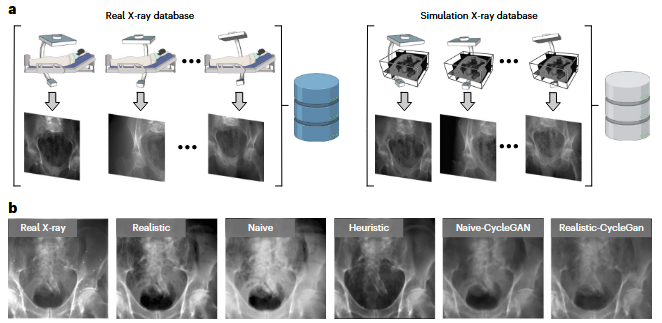
对于每张真实的X光图像,我们使用全面的2D/3D图像配准流程精确估计了X光摄像机的姿态。
随后,我们生成了合成的X光图像(数字重建放射影像,DRR),这些图像精确再现了真实X光图像的空间配置和解剖结构,仅在模拟的真实感上有所不同(图3a)。
我们研究了三种不同的X光图像模拟技术:naive DRR generation, xreg DRR10 and DeepDRR,分别称为基础、启发式和真实感模拟。它们在模拟真实X光成像物理效应方面的考虑有所不同。由于合成图像与真实数据集精确匹配,所有2D和3D标签均同等适用。
图3b展示了不同模拟器生成的图像外观与对应真实X光图像的对比。
Model and evaluation paradigm
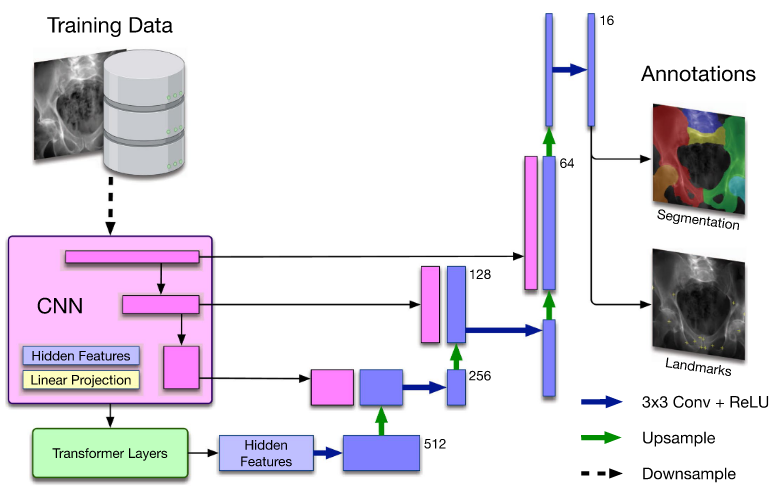
TransUNet是一种最先进的医学图像分割框架,用于所有任务。
所有临床应用的分割网络均经过训练以最小化Dice损失(Lseg),该损失评估预测分割标签与真实分割标签之间的重叠。
对于髋关节图像分析和手术工具检测任务,我们对TransUNet架构进行了调整(如扩展数据图2所示),使其能够同步预测解剖标志点位置。真实的标志点位置被表示为以实际坐标为中心对称的高斯分布(当标志点不可见时值为零)。通过引入均方误差损失函数(Lld),对网络预测的热图与参考标志点热图之间的差异进行约束。
在评估阶段,我们通过预测标志点与真实位置之间的l2距离来衡量定位精度。同时,使用Dice分数定量评估髋关节图像和手术工具的分割质量。
对于所有三项任务,我们均报告了Sim2Real(模拟到现实迁移)和Real2Real(现实到现实迁移)的性能表现。Sim2Real性能通过所有测试集真实X射线数据计算得出。Real2Real实验采用k折交叉验证方法开展,最终性能报告为所有测试折结果的平均值。
采用了一种专门设计的评估曲线图进行结果呈现,该方法能够全面反映算法需具备的两个关键性能指标:(1) 标志点检测的完整性;(2) 检测结果的精确性。网络对每个标志点的直接输出为热图强度图像(I)。为量化预测置信度,我们计算预测热图I与高斯基准热图Igauss的归一化互相关(normalized cross-correlation, ncc),即ncc(I, Igauss)¹²。当ncc值高于置信度阈值φ时(即ncc(I, Igauss) > φ),判定该标志点为有效激活状态。
基于TransUNet的并发分割与关键点检测网络架构,适用于多任务学习,扩展数据图2:
Result
Primary findings
使用SyntheX Sim2Real模型迁移范式训练的模型在真实数据上的表现与直接在真实数据上训练的模型相当,甚至更好。
Hip imaging
Sim2Real预测的稳定性更高,其标准偏差较小。
标志点检测平均误差与在366张西门子真实X射线图像上报告的性能相似。
单个解剖标志点和结构大多数标志点上的检测精度优于或与Real2Real相当,但耻骨联合上缘和下缘除外。
Sim2Real在所有六个结构中的分割性能均优于Real2Real。
Surgical robotic tool detection
Sim2Real误差的标准差明显更小。
在分割Dice得分方面,Sim2Real大幅优于Real2Real。
COVID-19 lesion segmentation
在敏感性和特异性方面,Sim2Real的表现与Real2Real相似,但在其他指标上稍逊一筹。
Sim2Real benchmark findings
基于我们精确控制的髋部成像消融研究,包括对(1)模拟环境、(2)域随机化和域适应效果、(3)图像分辨率的比较,我们观察到,使用强域随机化的真实模拟进行训练的效果与使用真实数据训练的模型或使用域适应的合成数据训练的模型相当,且在训练时无需任何真实数据。
The effect of domain randomization
在所有实验中,我们观察到使用强域随机化训练的神经网络始终比使用常规域随机化训练的网络表现更好。这是预期的,因为强域随机化引入了更剧烈的增强,采样了更广泛的图像外观谱,并促进了发现更具鲁棒性的特征,从而减少了过拟合的风险。
The effect of domain adaptation
无论是realistic-CycleGAN还是naive-CycleGAN,其表现均与Real2Real相当(图4d和4f)。
与仅在各自合成域上训练相比(图4a和4c),性能的提升证实了CycleGAN在域泛化方面的有效性。
与常规域随机化相比,强域随机化的ADDA表现有所下降(图4e和4i)。
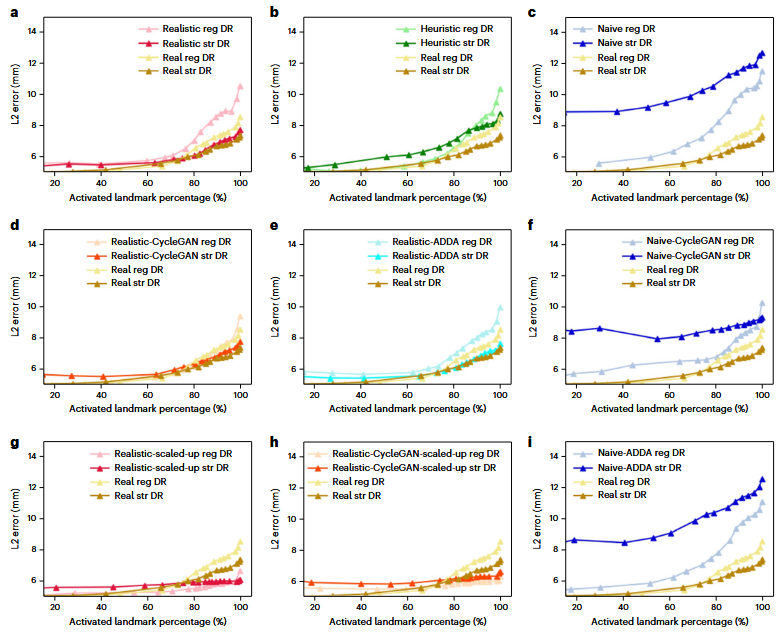
Scaling up the training data
随着训练数据和几何多样性的增加,我们发现所有扩大规模的实验在基准数据集上均优于Real2Real基线(图4g,h)。
图5展示了该合成数据训练模型在应用于真实数据时的检测性能的定性可视化结果。这一结果表明,在大规模真实合成数据上进行强领域随机化和/或适应训练,是替代真实数据训练的一种可行方案。

Discussion
使用SyntheX训练的模型在真实数据上的性能达到或超过了基于真实数据训练的模型。
- 使用DeepDRR框架进行基于物理的真实模拟生成训练数据,相比基于简单或启发式模拟范式训练的模型,能够更好地泛化到真实数据领域。
- 真实模拟与强领域随机化(SyntheX)相结合,在匹配数据集上训练时,表现与最佳领域适应方法(CycleGAN结合领域随机化)和真实数据训练相当。然而,由于SyntheX在训练时不需要任何真实数据,这一范式相比领域适应具有明显优势。
Sim2Real模型迁移在真实数据和相应标注特别难以获取的场景中表现最佳。而在真实数据丰富的场景中,Sim2Real几乎无法与Real2Real的性能相媲美。
Conclusion
本文展示了结合领域泛化或适应技术的人体模型图像生成真实模拟是大规模真实数据收集的可行替代方案。
结合真实合成训练和强领域随机化的方法(我们称之为 SyntheX)尤为有前景。
Methods
Domain randomization
常规域随机化(每轮训练均应用):
- 高斯噪声注入:x + N(0, σ),其中N为标准正态分布,σ从(0.005, 0.1)区间均匀采样后乘以图像强度范围。
- 伽马变换:norm(x)^γ,x经最大-最小值归一化后,γ从(0.7, 1.3)区间均匀采样。
- 随机裁剪:以原图尺寸90%的方形区域随机裁剪x。
强域随机化(每轮训练随机选择至多两种方法组合应用,同时保留基础增强):
- 反色:max(x) − x,将图像像素值取反。
- 脉冲/椒盐噪声注入:随机选择10%的像素替换为脉冲、胡椒或盐噪声。
- 仿射变换:施加包含平移、旋转、剪切和缩放的随机二维仿射形变。
- 对比度调整:采用线性、对数或Sigmoid对比度变换处理图像。
- 模糊化:应用高斯模糊(N(μ=0, σ=3.0))或均值模糊(核尺寸2×2至7×7)。
- 区域噪声破坏:随机添加含强噪声的矩形框区域。
- 像素丢弃:随机将1–10%的像素置零,或以矩形区域丢弃图像2–5%的像素。
- 锐化与浮雕化:锐化通过原图与锐化版本(混合系数α∈[0,1])叠加实现,浮雕化则直接叠加锐化版本。
- 池化操作:随机应用平均池化、最大池化、最小池化或中值池化(核尺寸2×2至4×4)。
- 亮度调整:通过像素值乘以50–150%的系数改变亮度。
- 局部形变:对图像局部施加随机分段仿射变换。
Domain adaptation
本研究选取两种广泛应用的域适应方法进行对比分析:CycleGAN与ADDA。
CycleGAN:在任务网络训练前,使用未配对的合成图像与真实图像训练CycleGAN模型。随后,所有合成图像均通过训练后的CycleGAN生成器进行处理,使其外观与真实数据对齐。为确保数据独立性,我们严格遵循任务模型训练时的数据划分原则,确保测试集图像在CycleGAN训练和任务网络训练中均不参与。
ADDA:该方法通过引入对抗性判别器分支作为附加损失函数,以区分源自合成图像与真实图像的特征差异。我们参考文献的设计思路,针对语义分割任务构建ADDA的判别器结构。
实验设置:两种方法(CycleGAN与ADDA)均在经优化的仿真图像(realistic simulation)与未经优化的基础仿真图像(naive simulation)上进行性能测试,以全面评估其域适应能力。
Clinical tasks experimental details
图像分辨率为1,536 × 1,536像素,各向同性像素间距为0.194毫米/像素,源到探测器距离为1,020毫米,主点位于图像中心。
Hip imaging
仿真中,CT体积的旋转角度在[−45°, 45°]内均匀采样,平移范围分别为左右方向[−50 mm, 50 mm]、上下方向[−20 mm, 20 mm]、前后方向[−100 mm, 100 mm]。共生成18,000张训练图像和2,000张验证图像。
通过投影几何将3D分割掩膜及解剖标志点投影至2D平面作为真值标签。
Robotic surgical tool detection
通过从高斯分布N(μ=0°, σ=2.5°)采样曲率控制点角度,生成100种不同构型的CM(手术工具)体素化模型。
CM基座位姿在左/右前斜位(LAO/RAO)[−30°, 30°]、头/尾位(CRAN/CAUD)[−10°, 10°]范围内均匀采样,源到等中心距离为[600 mm, 900 mm],x/y轴平移服从N(μ=0 mm, σ=10 mm)。
COVID-19 lesion segmentation
CT视角位姿在三个轴向旋转[−5°, 5°]、源到等中心距离[350 mm, 650 mm]内均匀采样,生成18,000张224×224像素训练图像和1,800张验证图像。CT施加[−30°, 30°]随机剪切变换,分割阈值设为0.5。
Benchmark hip-imaging investigation
本研究采用三种DRR(数字重建放射影像)仿真器生成合成数据:
- 基础仿真(Naive DRR)
- 仅进行简单射线投射,未考虑任何成像物理效应。
- 假设条件:单能射线源、单一材质物体、无噪声或散射等图像退化因素。
- 启发式仿真(xreg DRR)
- 在射线投射前,对CT亨氏单位进行线性阈值处理以区分空气与解剖组织材质。
- 虽能提升组织对比度使DRR更逼真,但仍未建模成像物理效应。
- 真实物理仿真(DeepDRR)
- 完整模拟X射线物理过程:考虑X射线源全频谱能量分布,基于机器学习实现材质分解与散射估计。
- 引入信号相关噪声、读出噪声及探测器饱和效应,高度还原真实成像链特性。
Network training details
网络训练采用随机梯度下降法,初始学习率为0.1,Nesterov动量为0.9,权重衰减为0.00001,批量大小为5张图像。训练过程中,学习率每10个epoch以0.5的gamma值衰减。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









