




【最近课堂上Transformer之前的DL基础知识储备差不多了,但学校里一般讲到Transformer课程也接近了尾声;之前参与的一些科研打杂训练了我阅读论文的能力和阅读源码的能力,也让我有能力有兴趣对最最源头的论文一探究竟;我最近也想按照论文梳理一下LLM是如何一路发展而来的,所以决定阅读经典论文。本文是这个系列的第一篇。】
Attention is all you need 这篇文章提出了一个新的“简单的”架构、LLM的基石——Transformer,主要是针对机器翻译任务,当然后来就出圈了。在这篇文章之前,机器翻译的做法是Encoder+Decoder(端到端),其中Encoder和Decoder都是循环神经网络+Attention。这篇文章所做的是把循环神经网络去掉,整个端到端是纯Attention的。
图解整体架构
论文中的这张图就可以说明Transformer的架构。左下方的inputs是传入的单词组成的句子,所以要经过一个embedding层,这是常规操作;然后通过N个编码块(论文中叫‘层’),每个编码块包括Multi-Head Attention(positional Encoding后面讲),归一化,前馈网络和残差连接(需要有resnet基础);编码器的输出给到解码器,但是是拦腰给进去的,不是在outouts的位置;解码器是"shifted right"的,意思是逐字生成的;解码块比编码块就多了一个Masked Multi-Head(后面讲),别的都和编码器一样。最后编码器通过一个softmax,就得到一个概率分布(即对字典里的每一个字都输出一个概率,一般概率最高的字作为这一步输出的字)。
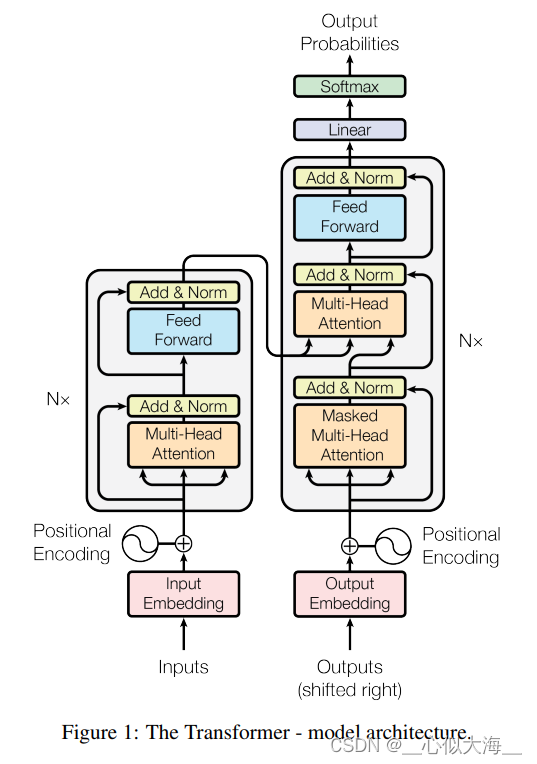
接下来逐个详解模型中的每一个部分:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1498
1498



 到【灌水乐园】发言
到【灌水乐园】发言










