







 本文深入介绍了UVM中的sequence机制,包括sequence的意义、继承关系、运行流程、启动方式、发送与相关宏、virtual_sequence以及sequencer的仲裁。sequence作为激励生成的关键,通过sequencer进行仲裁,driver接收并驱动激励。文章详细阐述了sequence的启动(手动与自动)、transaction的发送过程、sequence的生命周期,以及sequencer的仲裁算法和lock/grab机制。此外,还讨论了virtual_sequence的作用,它是协调和控制不同sequence发送的工具。
本文深入介绍了UVM中的sequence机制,包括sequence的意义、继承关系、运行流程、启动方式、发送与相关宏、virtual_sequence以及sequencer的仲裁。sequence作为激励生成的关键,通过sequencer进行仲裁,driver接收并驱动激励。文章详细阐述了sequence的启动(手动与自动)、transaction的发送过程、sequence的生命周期,以及sequencer的仲裁算法和lock/grab机制。此外,还讨论了virtual_sequence的作用,它是协调和控制不同sequence发送的工具。
目录
1.sequence的意义
对于激励来将,一般可以分为激励的生成和驱动。原本激励的生成是通过单独定义一个generator(激励发生器)或者是driver中生成激励。由于激励生成在整个验证环境中起着至关重要的作用,UVM单独添加了sequence机制。通过sequence发送层次化、随机化的激励,sequencer对sequence进行仲裁,以及driver接受sequencer传递来的sequence(req)并按照时序激励发送到DUT,而后driver等待从端返回信号和状态,再返回sequencer(rsp),sequence的生命周期到此结束,完成一个完整的握手。
2.sequence继承关系

- uvm_transaction 派生自uvm_object。
- uvm_sequence_item派生自uvm_transaction,相比uvm_transaction新增了sequence_id,m_sequencer等变量。
- uvm_sequence派生于uvm_sequence_base,通过body()任务来执行序列的激励。
- 一般基本数据包继承于uvm_sequence_item,总线协议上一些读写类型、数据长度、以及地址定义和一些调试相关的信息在里面定义。而uvm_sequence则是对uvm_sequence_item里面的信息进行选择、约束和随机化来生成验证所需的激励。
示例:
class lvc_ahb_transaction extends uvm_sequence_item;
……
// wdata or rdata from bus
rand bit [`LVC_AHB_MAX_DATA_WIDTH - 1:0] data[]; //定义数据、地址。
rand bit [`LVC_AHB_MAX_ADDR_WIDTH - 1 : 0] addr = 0;
// Represents the burst size of a transaction
rand burst_size_enum burst_size = BURST_SIZE_8BIT;
`uvm_object_utils_begin(lcv_ahb_transaction) //域的自动化 方便后续引用clone等函数
`uvm_field_array_int(data, UVM_ALL_ON)
`uvm_field_int(addr, UVM_ALL_ON)
`uvm_field_enum(burst_size_enum, burst_size, UVM_ALL_ON)
`uvm_object_utils_end
endclass
class lvc_ahb_master_single_trans extends uvm_sequence #(lvc_ahb_transaction); //声明传递数据类型
rand bit [`LVC_AHB_MAX_ADDR_WIDTH-1:0] addr;
rand bit [`LVC_AHB_MAX_DATA_WIDTH-1:0] data;
rand xact_type_enum xact;
rand burst_size_enum bsize; //声明为rand 为随机化激励提供准备
constraint single_trans_cstr {
xact inside {READ, WRITE};
} //约束
`uvm_object_utils(lvc_ahb_master_single_trans)
function new(string name="");
super.new(name);
endfunction : new
virtual task body();
`uvm_do_with(req, {
addr == local::addr;
data.size() == 1;
data[0] == local::data;
burst_size == bsize;
burst_type == SINGLE;
xact_type == xact;
}) // 激励约束和发送
endtask: body
endclass : lvc_ahb_master_single_trans
3.sequence的运行
3.1 sequence的启动
手动启动:通过例化sequence后挂载到sequencer上。
ny_seq seq = ny_seq:type_id::create("seq");
seq.start(sequencer);自动启动:通过default_sequence启动,通过调用config_db。
uvm_config_db#(uvm_object_wrapper)::set(this,"env.i_agt.sqr.main_phase","default_sequence",case_sequnce::type_id::get())前两个参数确定哪个phase执行,其余参数均为uvm的规定。
设置完default_sequence后,在对应sequence中提起和撤销objection:
class ny_seq extends uvm_sequence#(ny_transaction);
ny_transaction n_trans;
`uvm_object_utils(ny_seq)
virtual task body()
if(starting_phase ! = null)
starting_phase.raise_objection(this);
/* uvm_sequence的变量 starting_phase 在sequencer 自动获得句柄并挂载
seq.starting_phase = phase;
seq.start(this);
…… */
`uvm_do(n_trans)
if(starting_phase ! = null)
starting_phase.drop_objection(this);
endtask
endclass第二种自动启动:先实例化seq,再通过default_sequence启动。
function void my_case::bulid_phase(uvm_phase phase);
case0_sequence seq;
super.build_phase(phase);
seq = new("seq");
uvm_config_db(uvm_sequence_base)::set(this,"env.i_agt.sqr.main_phase","default_sequence",seq);
endfunctionsequence启动后会自动执行自己的pre_body() body() 和post_body()任务。
3.2 sequence发送与相关宏
item发送的过程:
//--------------------------------------------------
//| task uvm_execute(item, ...);
//| // can use the `uvm_do macros as well
//| start_item(item);
//| item.randomize();
//| finish_item(item);
//| item.end_event.wait_on();
//| // get_response(rsp, item.get_transaction_id()); //if needed
//| endtask
//|transaction发送过程:
实例化item →start_item →对item随机化→结束finish_item→如果需要rsp ,等到rsp返回后结束流程。
`uvm_do 宏等于对上述过程的封装。
封装过多会造成灵活性变差,因此UVM又添加了pre_do 、mid_do 和post_do 三个接口用于提升灵活性。
// The following methods are called, in order
//
//|
//| sequencer.wait_for_grant(prior) (task) \ start_item \
//| parent_seq.pre_do(1) (task) / \
//| `uvm_do* macros
//| parent_seq.mid_do(item) (func) \ /
//| sequencer.send_request(item) (func) \finish_item /
//| sequencer.wait_for_item_done() (task) /
//| parent_seq.post_do(item) (func) /
// pre_do 在start_item返回执行最后一行代码之前,执行完毕后才进行随机化。
mid_do位于finish_item的开始,post_do位于finish_item的最后。
下面为sequence_item和sequence发送的完整过程:
// For a sequence item, the following are called, in order
//
//|
//| `uvm_create(item)
//| sequencer.wait_for_grant(prior) (task)
//| this.pre_do(1) (task)
//| item.randomize()
//| this.mid_do(item) (func)
//| sequencer.send_request(item) (func)
//| sequencer.wait_for_item_done() (task)
//| this.post_do(item) (func)
//|
//
// For a sequence, the following are called, in order
//
//|
//| `uvm_create(sub_seq)
//| sub_seq.randomize()
//| sub_seq.pre_start() (task)
//| this.pre_do(0) (task)
//| this.mid_do(sub_seq) (func)
//| sub_seq.body() (task)
//| this.post_do(sub_seq) (func)
//| sub_seq.post_start() (task)
// The following methods are called, in order
//
//|
//| sub_seq.pre_start() (task)
//| sub_seq.pre_body() (task) if call_pre_post==1
//| parent_seq.pre_do(0) (task) if parent_sequence!=null
//| parent_seq.mid_do(this) (func) if parent_sequence!=null
//| sub_seq.body (task) YOUR STIMULUS CODE
//| parent_seq.post_do(this) (func) if parent_sequence!=null
//| sub_seq.post_body() (task) if call_pre_post==1
//| sub_seq.post_start() (task)
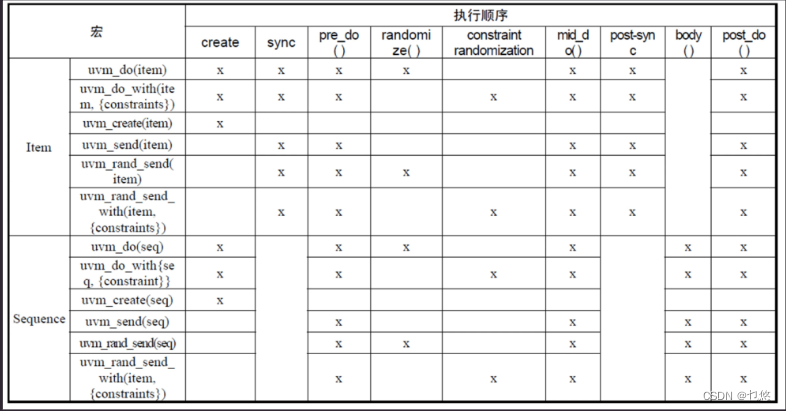
常用的uvm宏如下:
3.3 virtual_sequence
virtual_sequnece的出现主要是为了同步和控制不同的sequence的发送,virtual_sequence本身不发送transaction,它只是控制其他的sequence,起着统一调度的作用。
4.sequencer
sequencer是沟通sequence和driver之间的桥梁,通过仲裁机制对挂载到sequencer上的sequence进行筛选,并将sequence发往driver。driver通过get模式向sequencer索要sequence,主要包括以下三种情况:
1.仲裁队列有发送请求,但driver并没有申请要transaction,sequencer会处于等待状态,等driver发送请求后,把transaction交给driver。
2.仲裁队列没有发送请求,但driver申请新的transaction,sequencer会处于等待sequence状态,一旦sequence发送并立即将transaction发送给driver。
3.仲裁队列有发送请求,同时driver申请transaction,sequencer就会接受并发送transaction。
4.1 sequencer的仲裁
sequencer按照一定的算法,来决定transaction的接收顺序。
4.1.1 仲裁算法与相关宏
sequencr的仲裁算法主要包括:
- SEQ_ARB_FIFO(默认模式):先进先出
- SEQ_ARB_WEIGHTED: 加权仲裁
- SEQ_ARB_RANDOM: 完全随机选择
- SEQ_ARB_STRICT_FIFO: 严格按照优先级
- SEQ_ARB_STRICT_RANDOM: 严格按照优先级,当有多个同一优先级的sequence时,随机从最高优先级选。
- SEQ_ARB_USER:自定义仲裁算法
优先级相关宏:
- `uvm_do_pri()
- `uvm_do_on_pri()
- `uvm_do_on_pri_with()
`define uvm_do(SEQ_OR_ITEM) \
`uvm_do_on_pri_with(SEQ_OR_ITEM,m_sequencer,-1,{})`uvm_do其他宏都是`uvm_do_on_pri_with()来实现的。
示例:
class seq_0 extends uvm_sequence#(my_transaction);
……
virtual task body();
repeat (3) begin
`uvm_do_pri(m_trans,100) //通过宏设定优先级
end
endtask
endclass
class seq_1 extends uvm_sequence#(my_transaction);
……
virtual task body();
repeat (3) begin
`uvm_do_pri_with(m_trans,200,{m.trans.size < 100;}) //通过宏设定优先级
end
endtask
endclass
task my_case::main_phase(uvm_phase phase);
……
env.i_agt.sqr.set_arbitration(UVM_ARB_STRICT_FIFO) //在main_phase设置sqr的仲裁机制 默认仲裁机制为FIFO,优先级并不起作用。
fork
seq_0.start(env.i_agt.sqr);
seq_1.start(env.i_agt.sqr);
join
endtask
//运行结果seq_1发送完才发送seq_0sequence也可以设置其优先级,本质上是设置sequence里的transaction的优先级
示例:
seq.start(env.i_agt.sqr,null,100) //第一个参数为sequencer,第二个参数为parent sequence 第三个为优先级4.1.2 lock and grab
如果一个sequence想持续占有sequencer,直到这个sequence发送完transaction,再发送其他sequence的transaction,就需要使用lock和grab。
- lock和grab的区别在于:lock是等待仲裁序列的,等轮到后才lock。grab不等待仲裁序列,同一时间有多个sequence要挂载到sequencer上,grab第一时间拿到sequencer的占有权(放入仲裁队列最前面)。
- 两个sequence同时lock和grab,会等先lock或grab住结束后在把所有权给另一个sequence。
- grab不能打断已经lock住的sequence。
示例:
class normol_seq extends uvm_sequence#(my_transaction);
……
virtual task body();
repeat (9) begin
`uvm_do_with(m_trans,{m.trans.size < 100;})
`uvm_info("normol_seq","send one transaction",UVM_LOW)
end
endtask
endclass
class lock_seq extends uvm_sequence#(my_transaction);
……
virtual task body();
repeat (3) begin
`uvm_do_with(m_trans,{m.trans.size < 100;})
`uvm_info("lock_seq","send one transaction",UVM_LOW)
end
endtask
lock();
`uvm_info("sequence1","locked the sequencer",UVM_LOW)
repeat (3) begin
`uvm_do_with(m_trans,{m.trans.size < 200;})
`uvm_info("lock_seq","send one transaction",UVM_LOW)
end
unlock();
`uvm_info("sequence1","unlocked the sequencer",UVM_LOW)
repeat (3) begin
`uvm_do_with(m_trans,{m.trans.size < 300;})
`uvm_info("lock_seq","send one transaction",UVM_LOW)
end
endclass
class top_seq extends uvm_sequence#(my_transaction);
……
lock_seq l_seq;
normal_seq n_seq;
virtual task body();
fork
`uvm_do(l_seq)
`uvm_do(n_seq)
end
join
end
endclass
//开始交替发送transaction,在lock住后只发送lock_seq,unlock后再交替发送。
4.2 p_sequencer和m_sequencer
m_sequencer是uvm_sequencer_base类型的,是属于每个sequence的成员变量,但当需要引用sequencer中的变量时,直接引用会出错,需要进行类型转化。p_sequencer通过`uvm_declare_p_sequencer(SEQUENCER)宏,帮助完成了类型转化。
示例:
class my_sequencer extends uvm_sequencer#(my_transaction);
bit [47:0] dmac;
bit [47:0] smac;
……
enclass
class p_sqr_seq_wrong extends uvm_sequence#(my_transaction);
……
virtual task body();
`uvm_do_with(m_trans,{dmac == m_sequencer.dmac}) //类型错误
endtask
endclass
class p_sqr_seq_right extends uvm_sequence#(my_transaction);
……
virtual task body();
my_sequencer x_sequencer; //类型转换
$cast(x_sequencer,m_sequencer);
`uvm_do_with(m_trans,{dmac == x_sequencer.dmac})
endtask
endclass
class p_sqr_seq extends uvm_sequence#(my_transaction);
……
`uvm_declare_p_sequencer(my_sequencer) //声明p_sequencer ,自动上述完成类型转换
virtual task body();
`uvm_do_with(m_trans,{dmac == p_sequencer.dmac})
endtask
endclass4.3 virtual_sequencer
virtual_sequencer 一般与virtual_sequence配合使用,virtual_sequencer本身不参与仲裁,只是其路由器的作用,通过将不同sequencer的句柄与virtual_sequencer相连,通过在virtual_sequence中声明p_sequencer为virtual_sequencer来控制激励。
示例:
class rkv_gpio_base_virtual_sequence extends uvm_sequence;
……
`uvm_declare_p_sequencer(rkv_gpio_virtual_sequencer) //在顶层virtual_sequence中声明p_sequencer
……
endclass
class rkv_gpio_env extends uvm_env;
……
rkv_gpio_virtual_sequencer virt_sqr;
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
virt_sqr.ahb_mst_sqr = ahb_mst.sequencer; //将sequencer句柄和virt_sqr相连
endfunction
……
endclass
class rkv_gpio_portout_set_test extends rkv_gpio_base_test;
……
task run_phase(uvm_phase phase);
rkv_gpio_portout_set_virt_seq seq = rkv_gpio_portout_set_virt_seq::type_id::create("this");
super.run_phase(phase);
phase.raise_objection(this);
seq.start(env.virt_sqr); //seq 挂载到virt_sqr上
phase.drop_objection(this);
endtask
endclass
5.完整的数据流


















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









