




问题
前段时间一直被困扰,为何beam类的结果这么差,还以为代码出了问题:
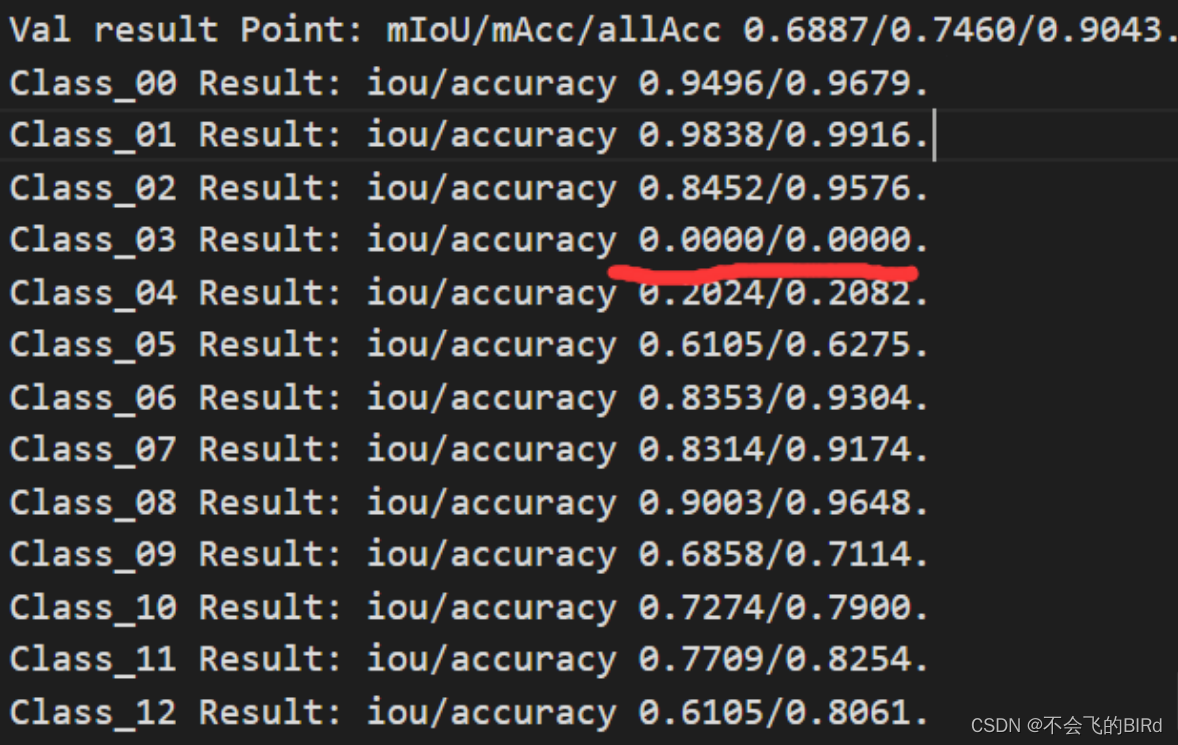
发现
后来在CBL论文里也发现了这个问题:
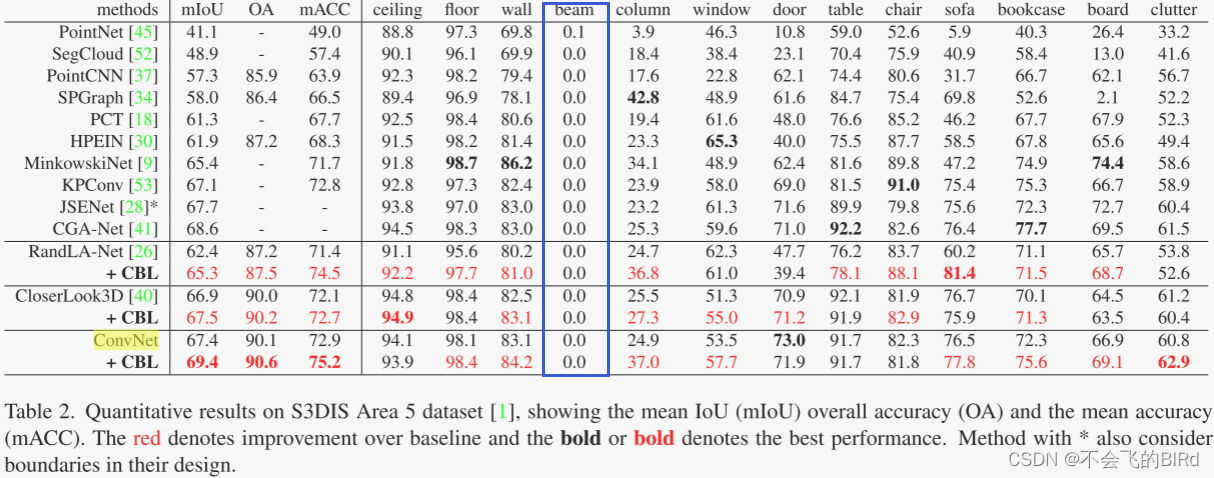
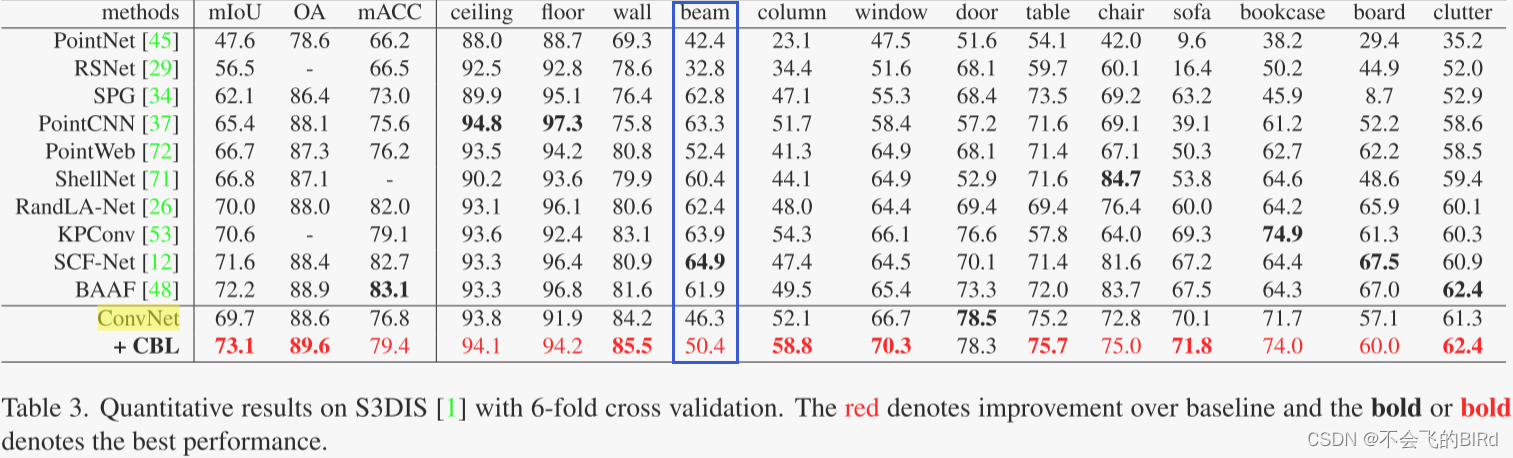
解谜
感觉应该是Area5 中beam的样本太少了,于是就去Area5 里查了一下,结果就是这样子:
首先看了正常样本(table为例):
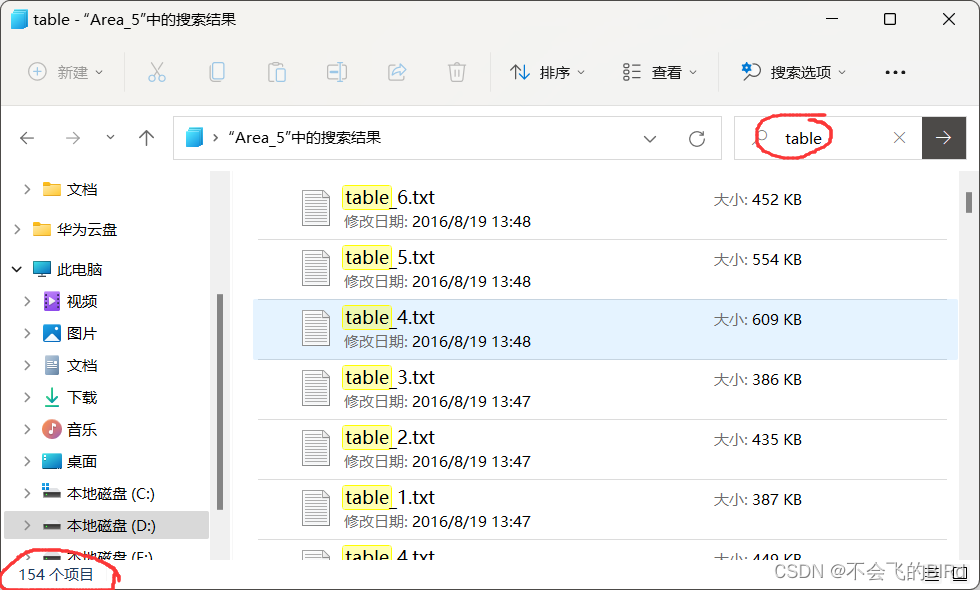
发现有154个文件用来标注,每个文件里有3000~46000个语义为桌子的点。
接下来再看看beam:
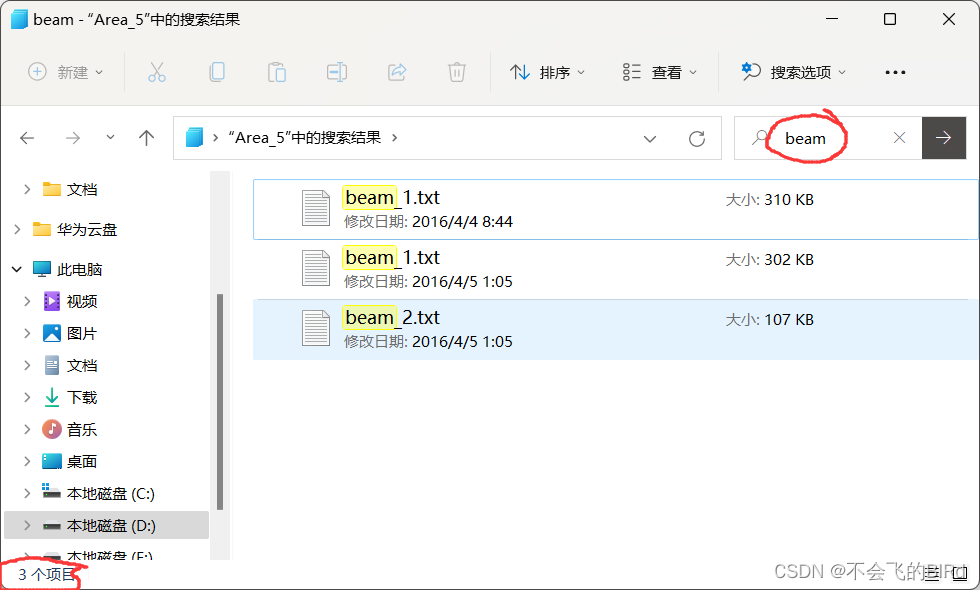
发现一共只有3个文件,总计加起来只有9497+9520+3410 = 22472个类别为beam的点。
后来在CBL论文里也发现了这个问题:
感觉应该是Area5 中beam的样本太少了,于是就去Area5 里查了一下,结果就是这样子:
首先看了正常样本(table为例):
发现有154个文件用来标注,每个文件里有3000~46000个语义为桌子的点。
接下来再看看beam:
发现一共只有3个文件,总计加起来只有9497+9520+3410 = 22472个类别为beam的点。
 3242
9169
1885
3242
9169
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
























