 MinerU 接入 ModelWhale 加速科研进程
MinerU 接入 ModelWhale 加速科研进程




近日,和鲸 ModelWhale 大模型应用平台全新升级发布会成功举办,并宣布与智能数据提取工具 MinerU 达成合作!会上特邀 OpenDataLab 负责人魏利群,为与会观众详细阐述 OpenDataLab 及 MinerU 应用实践。此次合作将 MinerU 强大的文档解析能力深度集成至 ModelWhale 智能工具中,为科研工作提供坚实数据支持。

拥抱大模型时代的 ModelWhale,助力企业级团队科研
和鲸科技旗下的数据科学协同平台 ModelWhale 基于 ModelOps 理念,深度融合计算基础设施、模型开发环境与团队协同管理,打通数据、算力、模型、成果应用全流程,为数据驱动型组织提供一站式数据分析与 AI 开发服务,推动领域大模型的构建与应用落地。
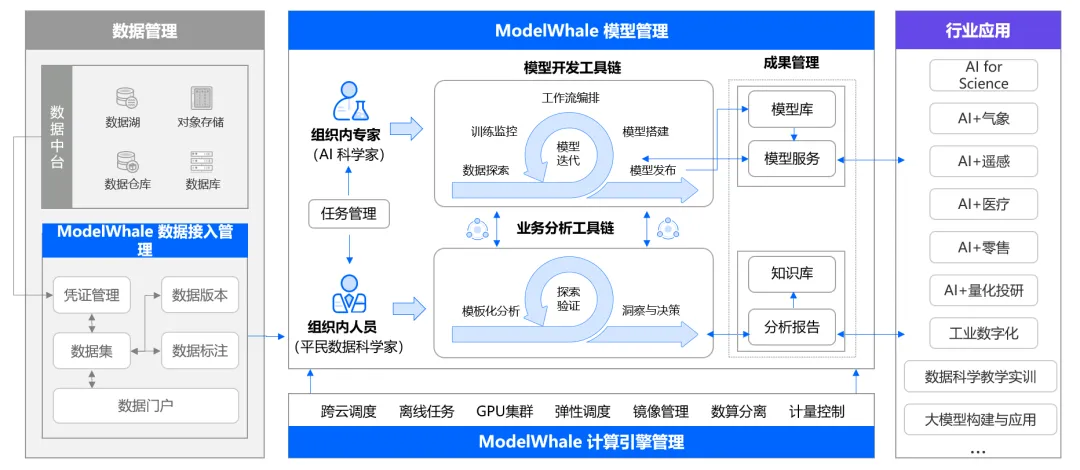
大模型浪潮既带来机遇,也伴生挑战。ModelWhale 深知:唯有掌握与大模型/智能体的高效协同,方能解锁科研创新的巨大潜能,释放人类创造力。基于此,ModelWhale 在 RAG 知识库构建、大小模型协同调度、可视化 AI 工作流编排、应用中心实现关键突破,全面升级为大模型应用平台,以更强大的功能和更灵活的适应性,拥抱大模型时代,助力企业级 LLMOps 和智能体开发场景。
RAG 知识库
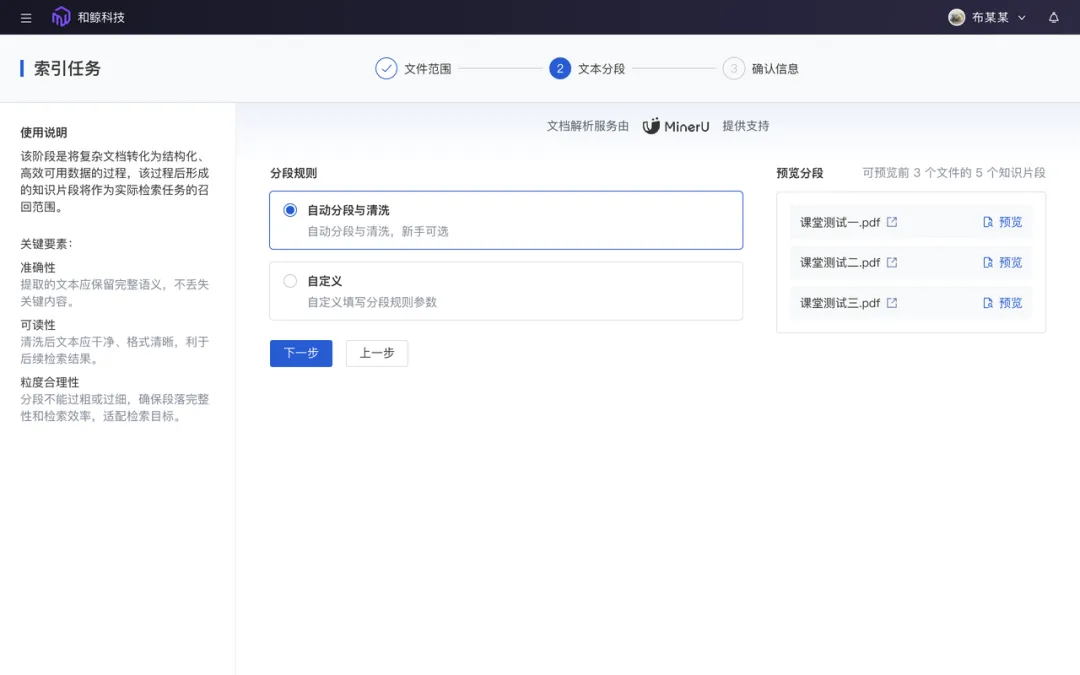
支持 RAG 知识库将团队现有的文献报告、课件等统一管理;同时,针对 RAG 工作流,设计了完善的全流程功能支持,包括知识片段导入、增删改查管理,新文件自动按需求分段清洗等,既方便团队成员使用,也便于对接智能体进行解读。
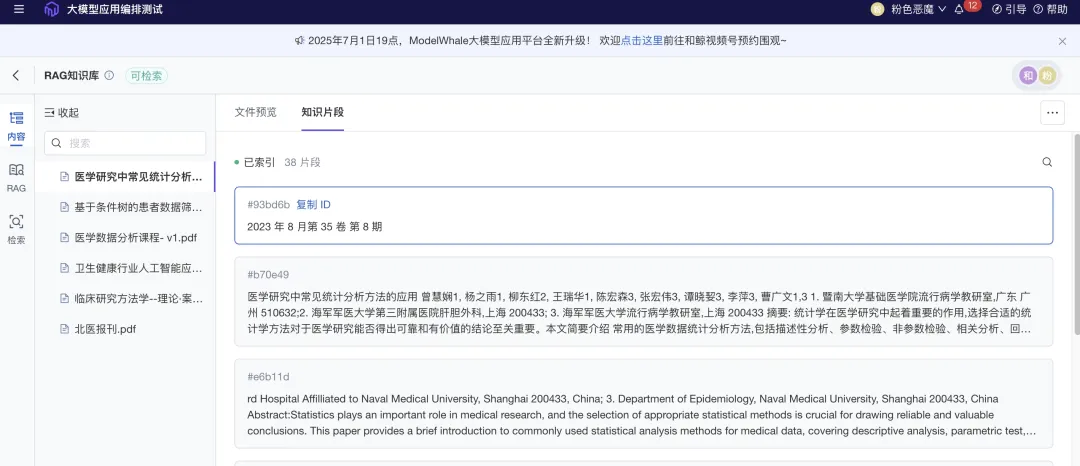
大小模型协同设施
基于 Git 的大小模型管理方案,一行代码即可推/拉超大模型,一键部署为云端服务,与团队共享。
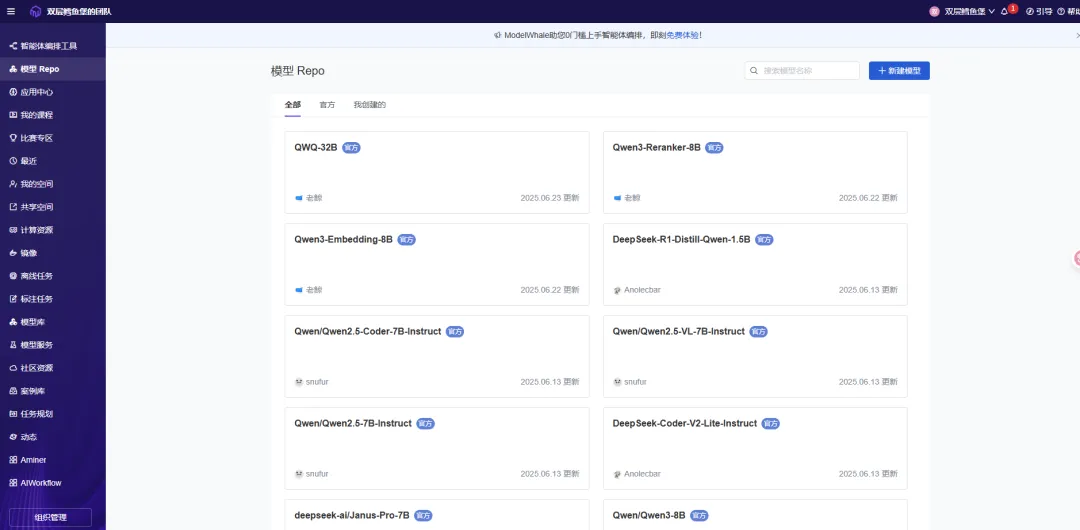
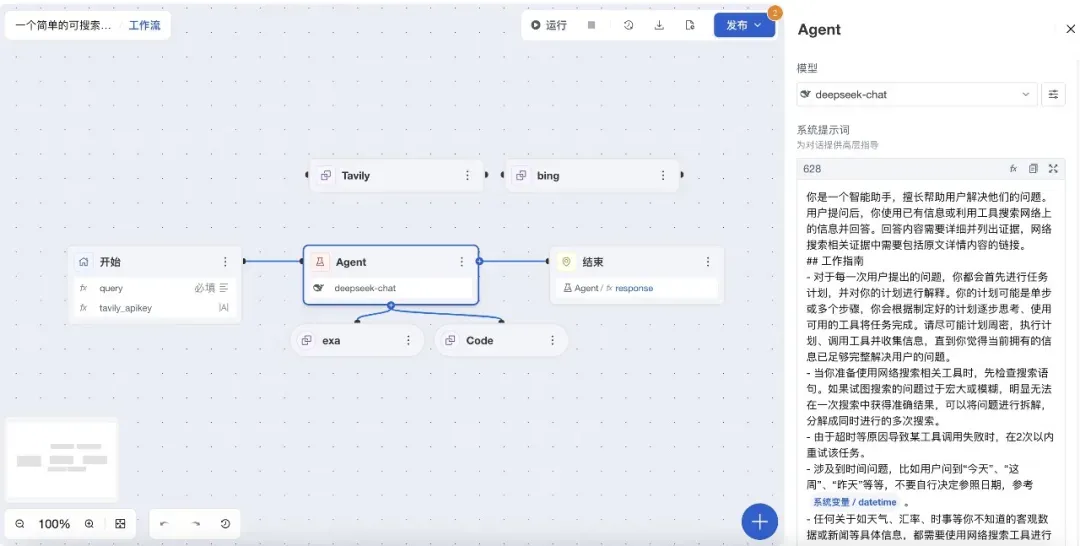
可视化 AI 工作流编排
灵活的 Agent + Workflow 编排工具,一键连通平台所有知识和模型资产,丝滑对接外部 LLM 与 MCP 服务,像搭乐高一样造智能应用。
应用中心
聚焦成果化数据资产共享,应用中心支持将编排工具中设计的智能体直接发布至应用中心,实现团队内共享;也可通过链接添加第三方的优质应用,整合领域内常用工具。
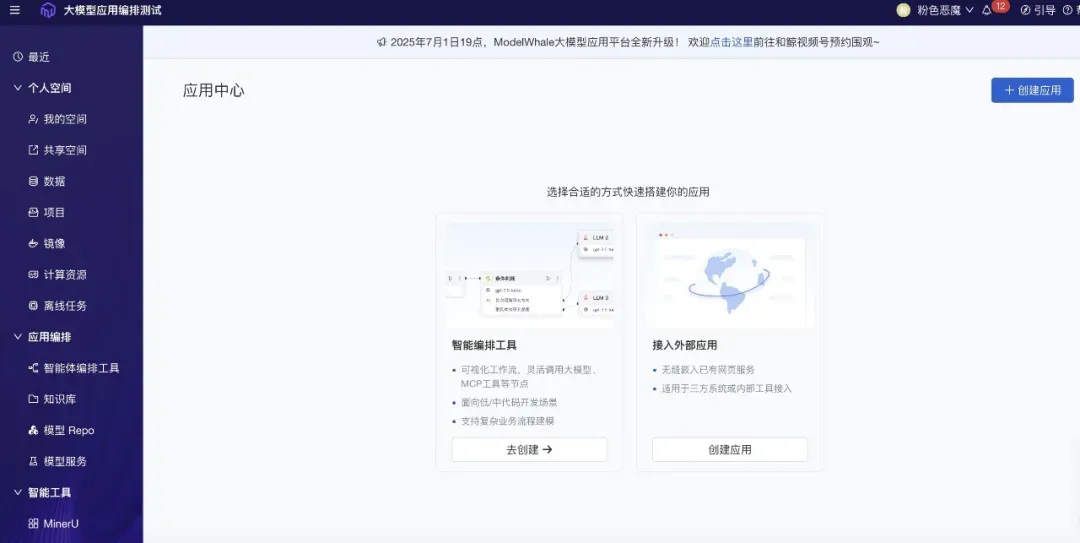
如何在 ModelWhale 中启用 MinerU
用户在 ModelWhale 创建新试用组织后,即可通过平台侧边栏,在 Notebook 项目和应用编排中快速下载并运行 MinerU 项目,操作路径清晰便捷,充分覆盖日常使用及业务高峰场景。
-
领先解析,奠定数据基石: 当您需要处理科研文献、报告等 PDF、Word 文档时,可直接在 ModelWhale 平台便捷上传。依托 MinerU 行业领先的解析能力,平台将快速输出高精度的文本、表格等结构化数据,为后续深入分析提供坚实可靠的数据基础。
-
知识库核心能力升级: ModelWhale 平台的 RAG 知识库在解析 PDF 和 Word 文档的关键环节,现已全面升级,由 MinerU 提供底层技术支持。用户在知识库上传文档时,后台将自动调用 MinerU 成熟高效的解析流程,显著提升知识入库的准确性、效率与可靠性,为构建高质量知识中枢提供强大引擎。
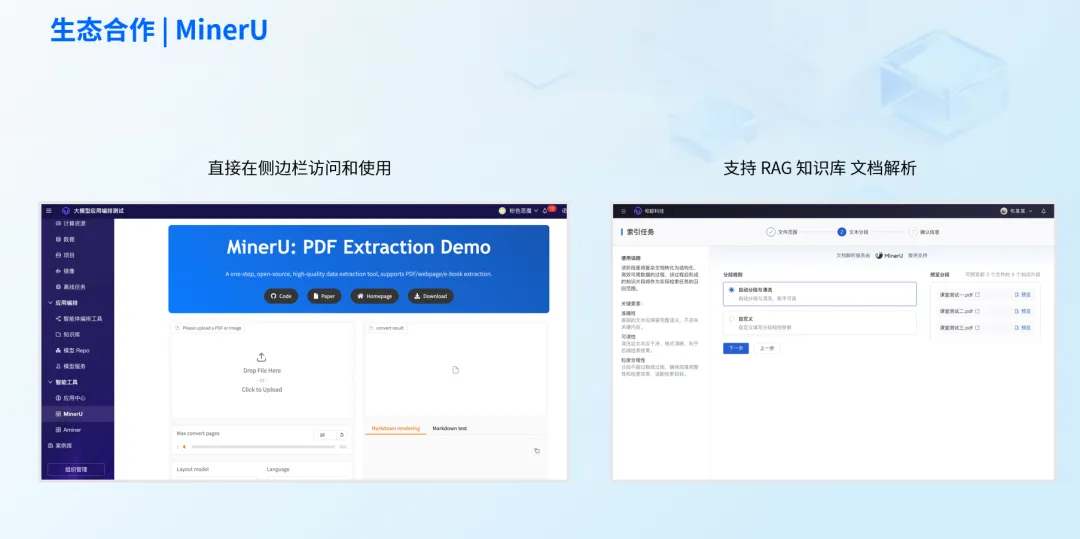
此次 MinerU 与 ModelWhale 的官方合作,旨在让更多数据爱好者与应用团队批量、快速、准确地解析 AI 语料,标志着 ModelWhale 在文档智能化处理的一大跃升。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









