







目录
InnoDB 内存结构
1. InnoDB存储引擎中内存结构的主要组成部分有哪些?
分析过程:
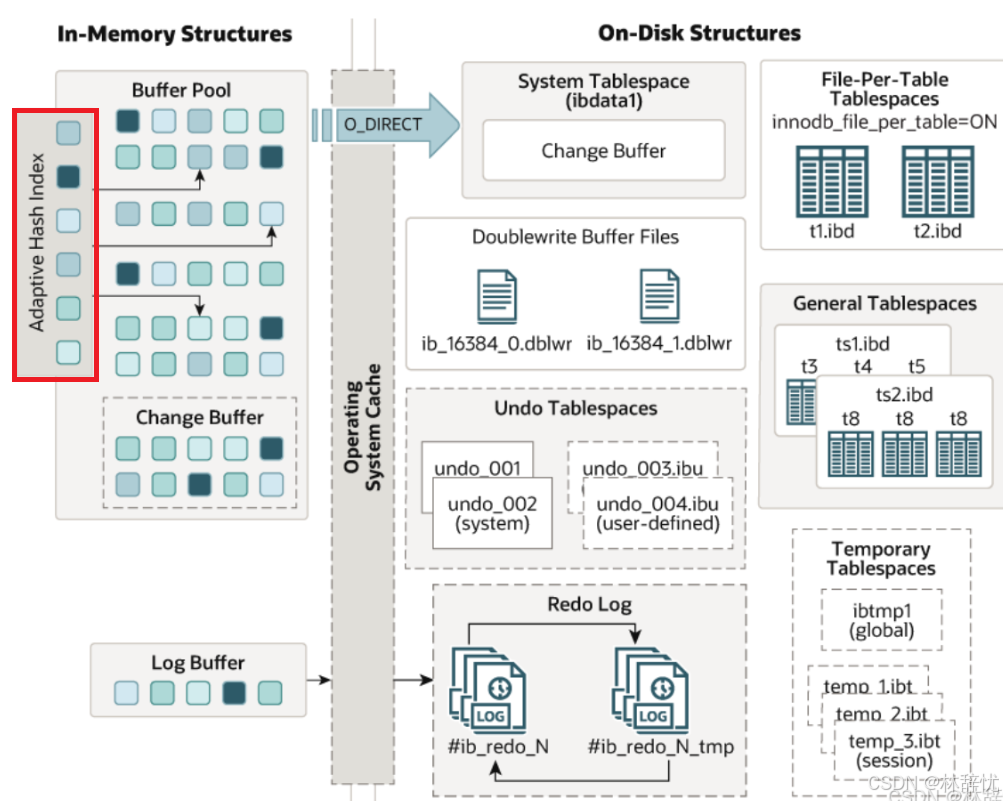
可以从官网中找到InnoDB架构图
解答问题:InnoDB存储引擎中内存结构主要分为:Buffer Pool 缓冲池,
Change Buffer 变更缓冲区,
adaptive_hash_index ⾃适应哈希索引Log Buffer ⽇志缓冲区
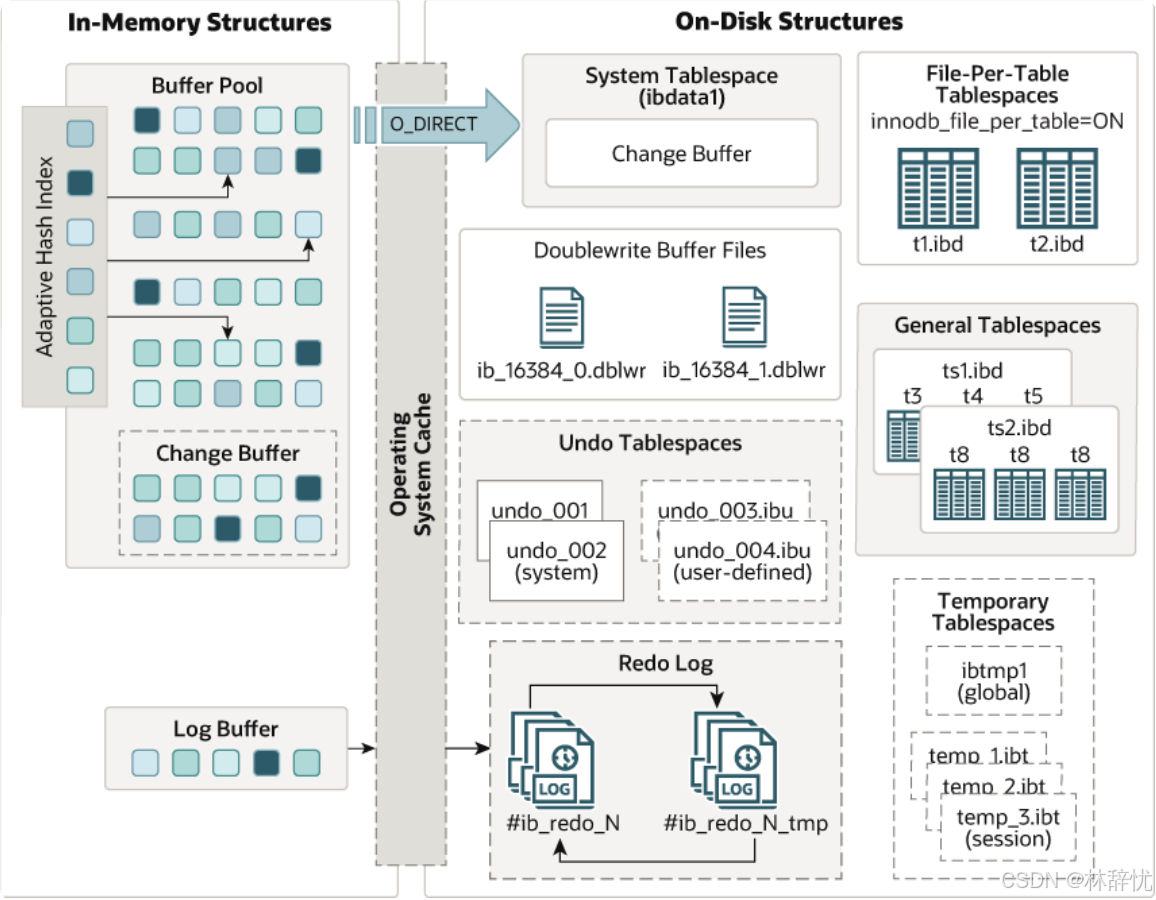 2.为什么需要内存结构?
2.为什么需要内存结构?
解答问题:(1)从MySQL实现的⻆度来思考这个问题,数据库的作⽤就是保存数据,⽤⼾的真实数据最终都会保存在磁盘上,在查询数据的过程中,如果每次都从磁盘上读取会严重影响效率,为了提⾼数据的访问效率,InnoDB会把查询到的数据缓存到内存中,当再次查询时,如果⽬标数据已经存在于内存中,就可以从内存中直接读取,从⽽⼤幅提升效率。(2)也就是说磁盘结构中的⽂件是⽤来保存数据实现数据持久化的,内存结构是⽤来缓存数据提升效率的。
缓冲池 - Buffer Pool
1.缓冲池的作⽤?
前置知识:缓冲池在内存结构中的位置,如下图所⽰:
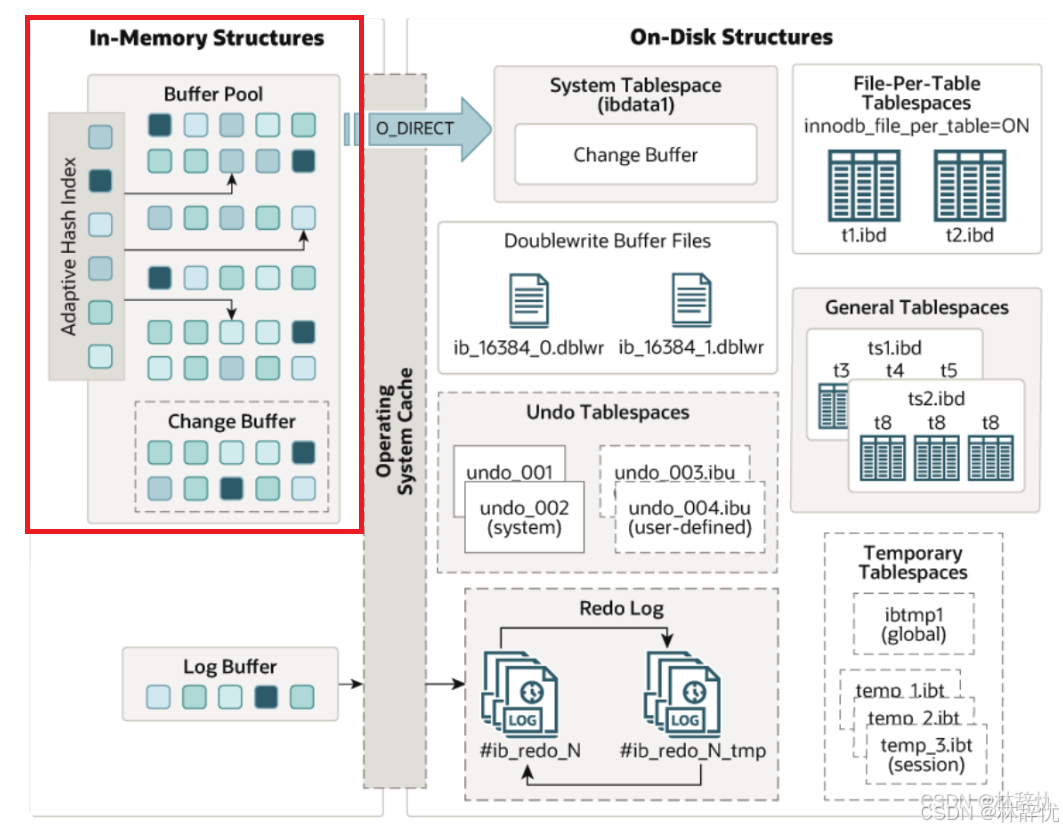
解答问题:
(1)缓冲池主要⽤来缓存被访问的InnoDB表和索引数据⻚,是主内存中的⼀⽚区域,允许直接从内存访问频繁使⽤的数据从⽽提⾼效率。在专⽤数据库服务器上,通常会将多达80%的物理内存分配给缓冲池。(2)其次缓冲池不仅缓存了磁盘的数据⻚,也存储了锁信息、Change Buffer信息、Adaptive hash index、Double write buffer等信息。
2.缓冲池是如何组织数据的?
前置知识:
(1)缓冲池组织数据的⽅式也可以说是缓冲池⽤到的数据结构,在这之前回顾⼀下InnoDB表空间的存储结构。(2)每个InnoDB表空间在磁盘上对应⼀个 .ibd ⽂件,其中包含了叶⼦节点段和⾮叶⼦节点段等逻辑段,段中包含了区组,区组中管理着区,区别包含数据⻚,数据⻚中包含数据⾏,每分别对着不同的数据结构⽬的就是便于数据的管理与⾼效访问
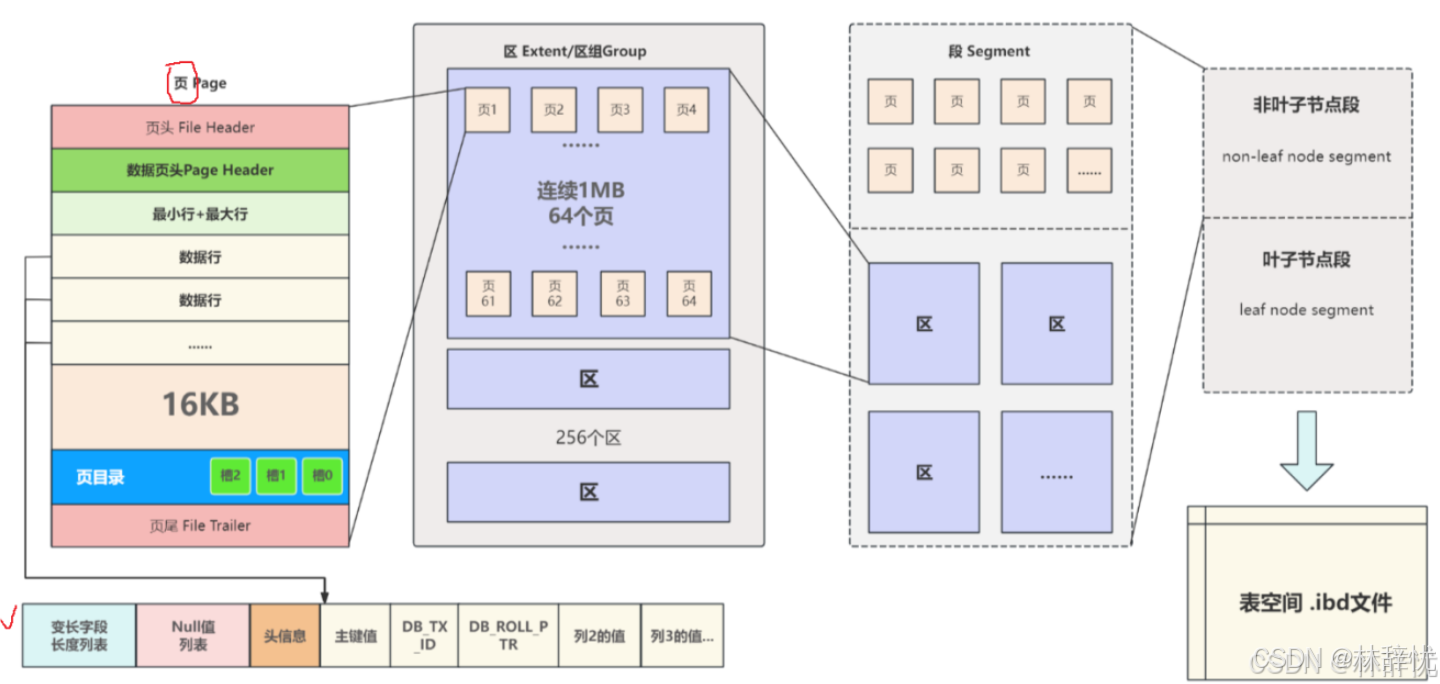
分析过程:一: 缓冲池的结构是怎样的?从缓冲池的概念了解到它是主内存中的⼀⽚区域,在专⽤服务器上会将多达80%的物理内存分配给缓冲池,在这么⼤的内存空间中如何保证效率就是要解决的问题2.缓冲池也采⽤与表空间类似的⽅式对数据进⾏组织,如下图所⽰:(1) 缓冲池中包含⾄少⼀个 Instances 实例, Instances 是真正的缓冲池的实例对象,内存操 作都是在 Instances 中进⾏的;(2) 每个 Instances 中包含⾄少⼀个 Chunk 块, Chunk 是在服务器运⾏状态下动态调缓冲池 进⾏⼤⼩时操作的块⼤⼩;(3)每个块中包含和管理若⼲个从磁盘加载到内存的 Page 数据⻚
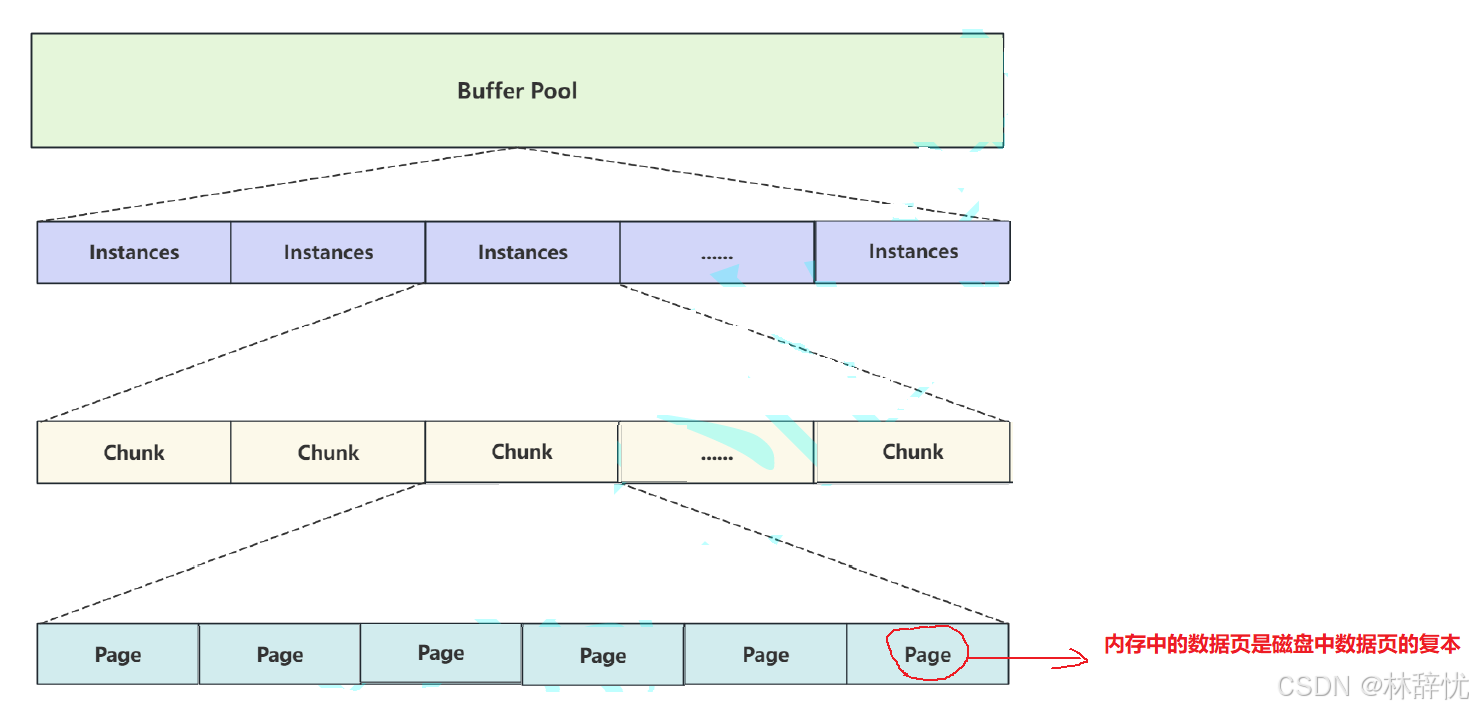
3.可以看出缓冲池通过定义不同的数据结构,但最终管理的是每个数据⻚,这些数据⻚是从磁盘中加载到内存的,也就是说磁盘中的数据⻚加载到内存中之后,对应的就是内存中的数据⻚,并且⻚与⻚之间⽤链表连接
4.那么这时就有⼀个问题,我们知道磁盘中的数据⻚⼤⼩默认是16KB,并且通过头信息中的
next_record 记录下⼀⾏地址偏移量,在⻚的结构定义中并没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,那么在内存中如何为每个⻚建⽴连接呢?

二:缓冲池中⻚与⻚之间是如何建⽴连接的?(控制块与数据页在内存中是一一对应的)
1.由于数据⻚中没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,为了每个数据⻚在内存中实现链表连接,InnoDB定义了⼀个叫"控制块"的数据结构,"控制块"中有三个重要的信息分是:(1)指向数据⻚的内存地址(2) 前⼀个控制块的内存地址(3)后⼀下控制块的内存地址2.然后 ⽤⼀个双向链表管理每个控制块,如下图所⽰:
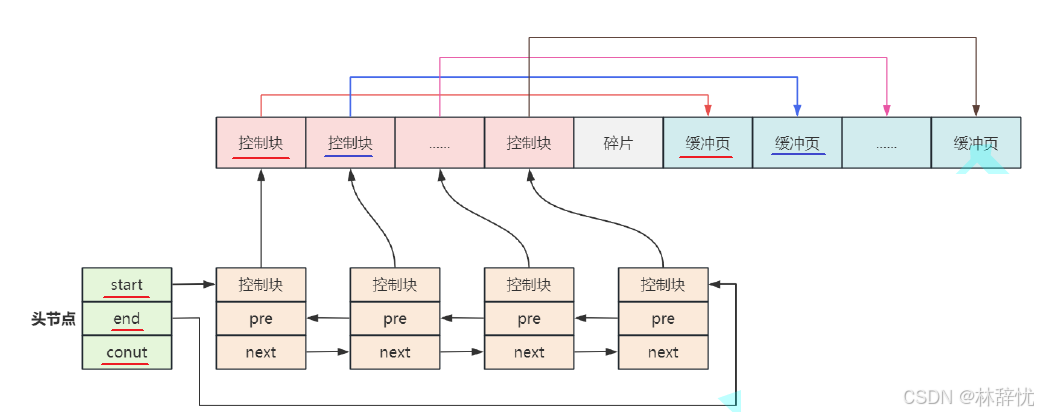
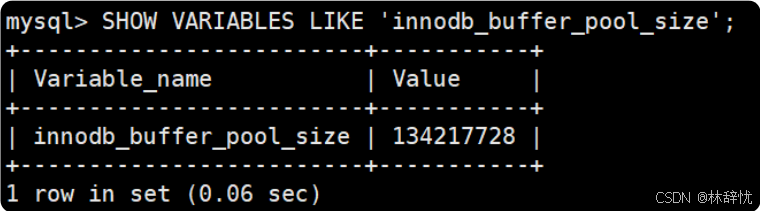
为了确定控制块链表的超始位置,专⻔定义了⼀个头节点,头节点中包含了三个主要的信息,如上图所⽰:(1)第⼀个控制块的内存地址(2)最后⼀个控制块的内存地址(3)链表中控制块的数量3.通过遍历控制块链表就可以遍历内存中的数据⻚解答问题:缓冲池中主要缓存的是磁盘中的数据⻚,由于数据⻚中没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,InnoDB定义了"控制块"的数据结构,控制块中有⼀个指向数据⻚内存地址的指针,实现"控制块"与数据⻚的⼀⼀对应,并且把每个控制块连接成⼀个双向链表,⽤⼀个单独的头节点记录链表的第⼀个和最后⼀个节点,这样通过遍历控制块链表就可以遍历内存中的数据⻚。衍生问题:1. 内存中的数据⻚与磁盘上的数据⻚是什么关系?(一一对应的)磁盘上的数据⻚加载到内存中后,在缓冲池中都有⼀个内存⻚与它对应,只不过内存中管理的是控制块组成的链表,控制块有⼀个指针指向了内存中真实的数据⻚2.Buffer Pool的⼤⼩可以设置吗?(1) 可以通过系统变量 innodb_buffer_pool_size 进⾏设置,设置时以字节为单位:默认值为134217728 字节,即 128MB ;最⼤值取决于CPU架构和操作系统,在 32 位系统上最⼤值为 4294967295 (2^32 -1),在 64 位系统上最⼤值为 18446744073709551615 (2^64 -1)(2) 这⾥需要注意的是, InnoDB 为"控制块"分配额外的内存空间,也就是说"控制块"并不会占⽤ Buffer Pool的内存空间,所以实际分配的内存总空间⽐指定的缓冲池⼤⼩⼤ 10%左右(说明在设置Buffer Pool 的大小时需要预留10%的空间)(3) 缓冲池设置的值越⼤,在多次访问相同表数据时,磁盘I/O就会越少,因为数据都已经缓存在内存 中,所以效率也就越⾼,但是服务器启动时初始化时间会⽐较⻓。(4)查看缓冲池⼤⼩: SHOW VARIABLES LIKE 'innodb_buffer_pool_size' ;
3.Buffer Pool中Instances的数量如何确定?
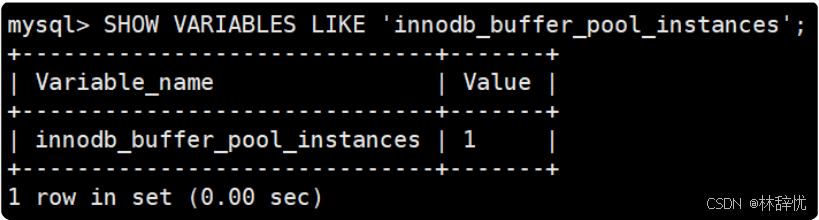
(1)通过系统变量 innodb_buffer_pool_instances 可以设置缓冲池实例的个数,默认是 1 ,最⼤值 64 ;(2)当缓冲池的⼤⼩⼩于 1GB 时,⽆论指定 innodb_buffer_pool_instances 数是多少都会⾃动调整为 1 ;(3)当缓冲池的⼤⼩⼤于 1GB 时, innodb_buffer_pool_instances 默认值为 8 ,也可以指定⼤于 1 的值来设置 Instances 的数量,多个 Instances 可以提升服务器的并发性;(4)为了获得最佳的效率,通过指定 innodb_buffer_pool_instances 和innodb_buffer_pool_size 为每个缓冲池实例设置⾄少为 1GB 的空间;(5)查看Instances的数量: SHOW VARIABLES LIKE 'innodb_buffer_pool_instances' ;
4.Chunk的作⽤是什么?
在这里先回顾下前面介绍的缓冲区的结构,当数据行连同结构复制到内存中,在内存中没有办法通过数据页本身进行关联关系的组织,于是通过一个控制块的数据结构,为了在内存中方便组织数据,还使用了一些数据结构进行管理
Buffer Pool是内存中的主要工作区域,内部管理了若干个instances实例,每个instances实例管理了多个chunk,每个chunk管理了若干个page
那么instances能直接管理page的嘛,chunk的作用在哪
chunk的作用主要体现在对instance空间进行扩容/缩容,若instance直接管理page的话,那么当instance从4GB扩容到8GB时,在扩容时就会重新申请一个8GB的内存空间,对于这个内存也是需要分配并管理一些数据页的,还需要把之前instance中缓存的数据整体拷贝到新空间中,此时会很消耗资源
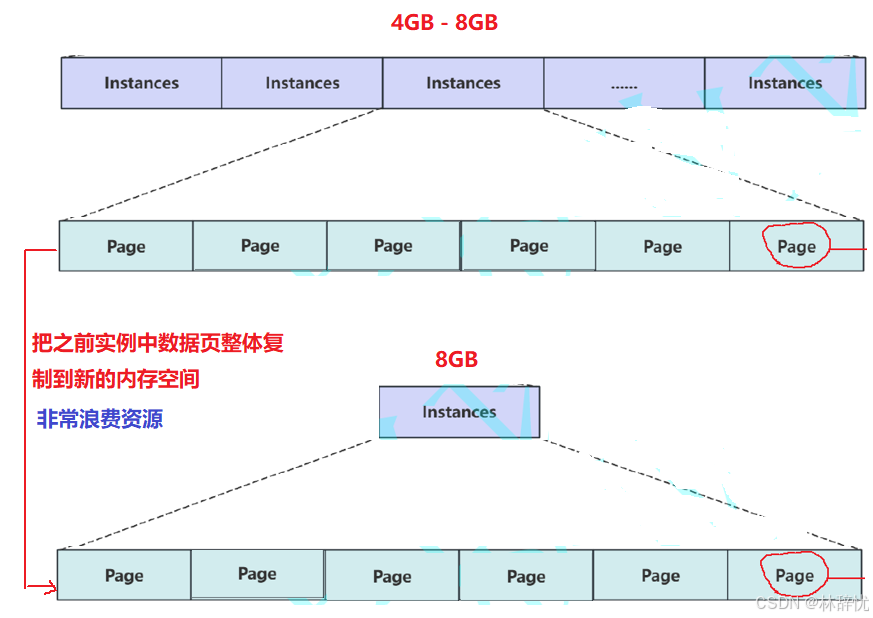
因此为了解决此问题,就引入chunk来进行管理
(1)Chunk 是在服务器运⾏状态下动态调缓冲池进⾏⼤⼩时操作的块⼤⼩,为避免在调整⼤⼩操作期间复制所有缓冲池中的数据⻚,调整操作以 "块"为基本单位执⾏;这样在增容/缩容时只需增减chunk即可
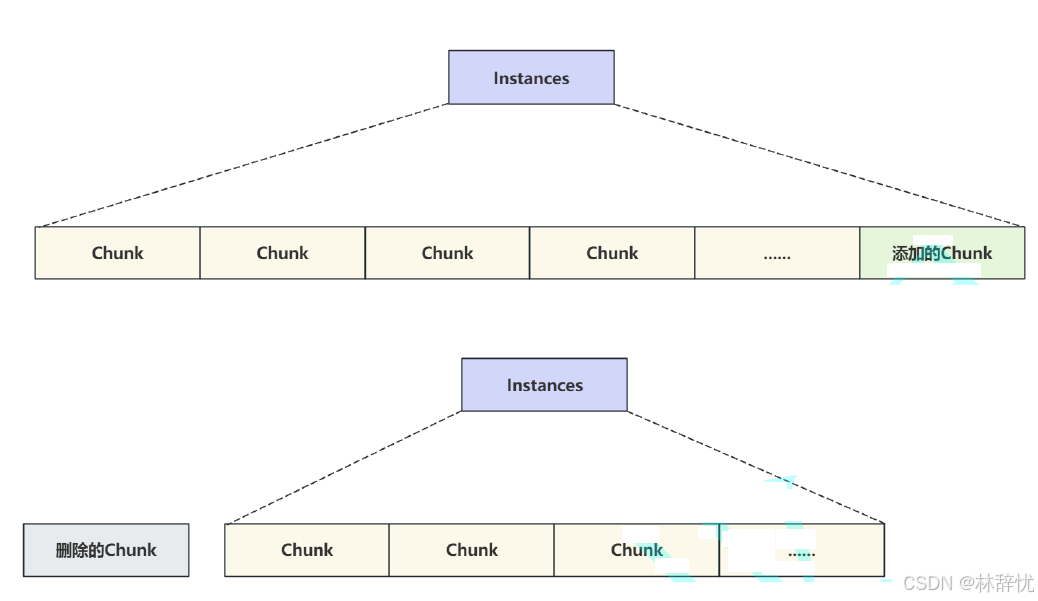
(2)在服务器运⾏时调整缓冲池的⼤⼩:
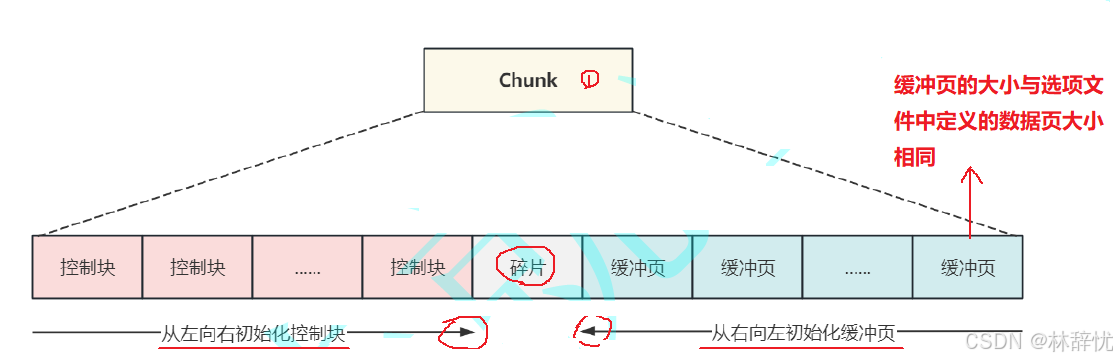
# 把缓冲池⼤⼩设置为 1GBmysql> SET GLOBAL innodb_buffer_pool_size= 1073741824 ;(3) 启动调整⼤⼩操作时,在所有活动事务完成后操作才会开始。⼀旦调整⼤⼩操作开始,新的 事务和操作必须等到调整⼤⼩操作完成才可以访问缓冲池5.Instances中Chunk的数量如何确定?(1) Chunk ⼤⼩可以通过系统变量 innodb_buffer_pool_chunk_size 进⾏设置,默认为134217728 字节即 128MB ;在设置⼤⼩时可以以 1048576 字节即 1MB 为单位增加或减少;块中包含的数据⻚数取决于 innodb_page_size (4~64KB) ;(2)更改 innodb_buffer_pool_chunk_size 的值时注意以下条件 :1.如果 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances ⼤于当前缓冲池⼤⼩, innodb_buffer_pool_chunk_size 将被截断为innodb_buffer_pool_size / innodb_buffer_pool_instances 。2. 缓冲池⼤⼩必须始终等于或倍数于 innodb_buffer_pool_chunk_size *innodb_buffer_pool_instances 。如果修改了innodb_buffer_pool_chunk_size 的值,导致不符合这个规则,那么在缓冲池初始化时innodb_buffer_pool_size 会⾃动四舍五⼊为等于或者倍数于innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances 的值。3. innodb_buffer_pool_chunk_size 的设置可能会影响到缓冲池⼤⼩ innodb_buffer_pool_size 的值,所以要调整 innodb_buffer_pool_chunk_size 的值之前⼀定要计算好6. 控制块与Page是如何初始化的?(1)Chunk 中管理的是具体的数据⻚,当缓冲池初始化完成时会把每个数据⻚所占⽤的内存空间和对应的控制块分配好,只不过没有从磁盘加载数据,内存中的数据⻚是空的⽽已(2)当缓冲池初始化的过程中,会为 Chunk 分配置内存空间,此时"控制块"会从 Chunk 的内存空间从左向右进⾏初始化,数据⻚所占的内存会从 Chunk 的内存空间从右向左进⾏初始化,当所剩的内存空间不够⼀组"控制块" + 数据⻚所占的空间时,就会产⽣碎⽚空间,如果适好够⽤则不会出现碎⽚空间,如下图所⽰:
(3)内存初始化完成之后,建⽴控制块与内存中缓冲数据⻚之间的关系,从左开始第⼀个控制块指向第⼀个缓冲数据⻚的内存地址
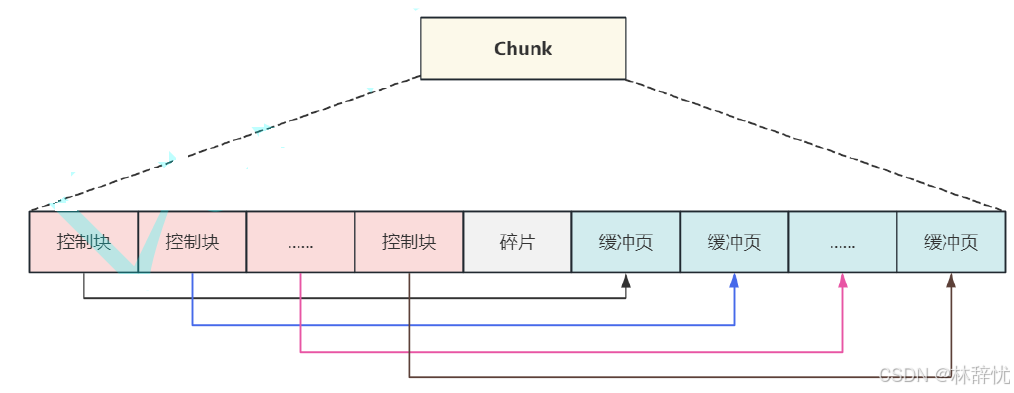
(4)当前从磁盘中加载数据⻚时,就可以在把数据缓存在内存中的空闭数据⻚中
7.可以通过缓冲池配置来提升性能吗?
通过配置以下关于缓冲池的系统变量来提⾼性能,其中包括:配置缓冲池⼤⼩配置多个缓冲池实例防⽌缓冲池扫描配置缓冲池预取(预读)配置缓冲池刷新策略保存和恢复缓冲池状态从核⼼⽂件中排除缓冲池⻚查看以上变量: SHOW VARIABLES LIKE 'innodb_buffer_pool%' ;
3.缓冲池中的⻚是如何进⾏管理的?
这里管理的是内存中数据页的状态
前置知识:数据页的状态主要分为三种:
1.空闲状态:内存中的数据页没有数据
2.已使用:从磁盘中把数据加载到内存中
3.需要落盘:对内存中的数据页进行了修改操作
分析过程:
1.当缓冲池初始化完成后,缓冲池中的数据⻚只是被分配了内存空间,并没有真实的数据,当⽤⼾进⾏数据查询时真实的数据从磁盘加载到内存中并分配⼀个内存中的数据⻚,这时内存中数据⻚的状态从空的变成了有实际的数据;当⽤⼾修改数据时,并不是直接修改磁盘中的数据⻚,⽽是修改内存中数据⻚中的数据⻚,这时内存中数据⻚的状态从有实际数据变成了被修改。
2.在缓冲池中采⽤三个链表维护内存⻚,这三个链表也对应着内存中⻚的三种状态,分别是:
(1)Free 未使⽤的⻚,也可以称做空闲⻚;(2)Clean 已使⽤但未修改的⻚,也可以称做⼲净⻚;(3)Dirty 已修改的⻚,也可以称做脏⻚。3. 对应的三个链表分别是 Free List 、 LRU List 和 Flush List :(1)Free List :只管理Free ⻚(2)LRU List :管理 Clean⻚和Dirty⻚(3)Flush List :只管理Dirty⻚
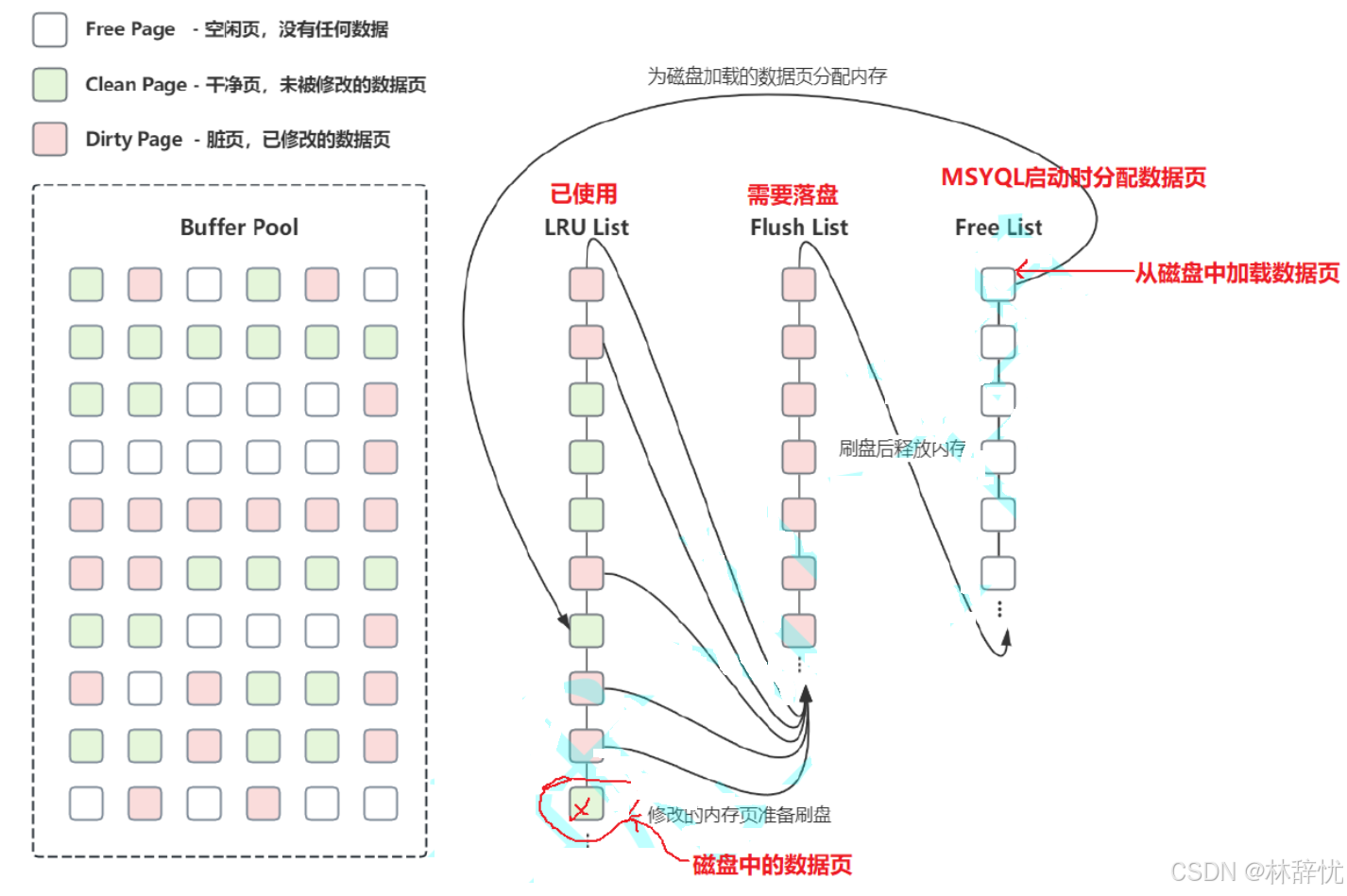
4.Free List :当服务器启动时分配数据页,每个数据页占用一个内存空间,此时数据页没有数据,就会放到Free List中,即Free List 中管理着空闲的也就是没有被使⽤的内存⻚,当执⾏查询操作时,如果对应的⻚已经在 buffer pool 中则直接返回数据,如果没有且 Free List 不为空,则从磁盘中查询对应的数据并存到 Free List 的某⼀⻚中,然后把这个⻚从 Free List 中移除并放⼊ LRU List 中。5.LRU List :管理所有从磁盘中读取的数据⻚,包括未被修改的和已被修改的数据⻚,并根据 LRU算法对链表中的⻚节点进⾏维护与淘汰。当数据库刚启动时 LRU List 是空的,这时从内存中申请到的⻚都存放在 Free List 中,当数据从磁盘读取到缓冲池时,⾸先从 Free List 中 查找是否有可⽤的空闲⻚,如果有则把该⻚从 Free List 中删除并加⼊到 LRU List ;如果没有,则根据 LRU 算法淘汰 LRU List 末尾的⻚,并将该内存空间分配给新数据⻚;6.Flush List :当 LRU List 中的⻚被修改后会被标识为脏⻚(Dirty page),并把脏⻚加⼊到Flush List 中,在这种情况下,数据库会通过刷盘机制把 Flush List 中的脏⻚刷回磁盘; Flush List 是⼀个专⻔⽤来管理脏⻚的列表。脏⻚既存在于 LRU List 中,也存在于 Flush List 中, LRU List ⽤来管理缓冲池中⻚的可⽤性, Flush List ⽤来管理要被刷回磁盘的⻚,⼆者互不影响。 Flush List 中的脏⻚在执⾏了刷盘操作后会将空间还给 Free List 。解答问题:每个缓冲池都采⽤三个链表维护内存⻚,这三个链表也对应着内存中⻚的三种状态,分别是:(1)Free 未使⽤的⻚,也可以称做空闲⻚;(2)Clean 已使⽤但未修改的⻚,也可以称做⼲净⻚;(3)Dirty 已修改的⻚,也可以称做脏⻚;衍生问题:1. 内存中有这么多数据⻚如何快速找到⽬标⻚?⾸先第⼀种办法是通过遍历,这种做法显⽰不能满⾜性能要求InnoDB采⽤的是 Page Hash 的⽅式,也就是每当把磁盘中数据⻚加载到内存时,⽤数据⻚的表空间Id和⻚号做为Key,当前⻚在内存中的地址做为Value保存起来,每次查询时就可以通过Key快速定位到⽬标⻚,如果内存中没有⽬标⻚,则从磁盘中获取2.缓冲池中的数据放不下了怎么办?InnoDB根据根据⾃⾝的实际场景,使⽤淘汰策略来淘汰相应的数据⻚,从⽽释放出内存空间,以便新的数据⻚加载到内存中
4.缓冲池采⽤哪种淘汰策略?是如何实现的?
前置知识:
随着mysql不断运行,Buffer Pool 当中的空闲页可能会被用尽,即Free 链表为空,如果继续从磁盘访问数据页时,内存中就需要有足够的空间来保存新加载的数据页,这时就需要把LRU List 中不经常访问的页淘汰掉,将内存空间释放出来,供新加载的数据页使用
分析过程:(1)缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法(在原来LRU算法的基础做了修改),以下出现的LRU算法指的是LRU变形算法。(2)缓冲池使⽤ LRU算法管理链表,当有新⻚⾯添加到缓冲池时,最近最少使⽤的⻚将被淘汰,并将新⻚添加到列表的中间,这种中点插⼊策略将列表视为两个⼦列表:1.链表头部,是存放最近访问的新⻚(年轻⻚)⼦列表;2.链表尾部,是存放最近较少访问的旧⻚⼦列表。
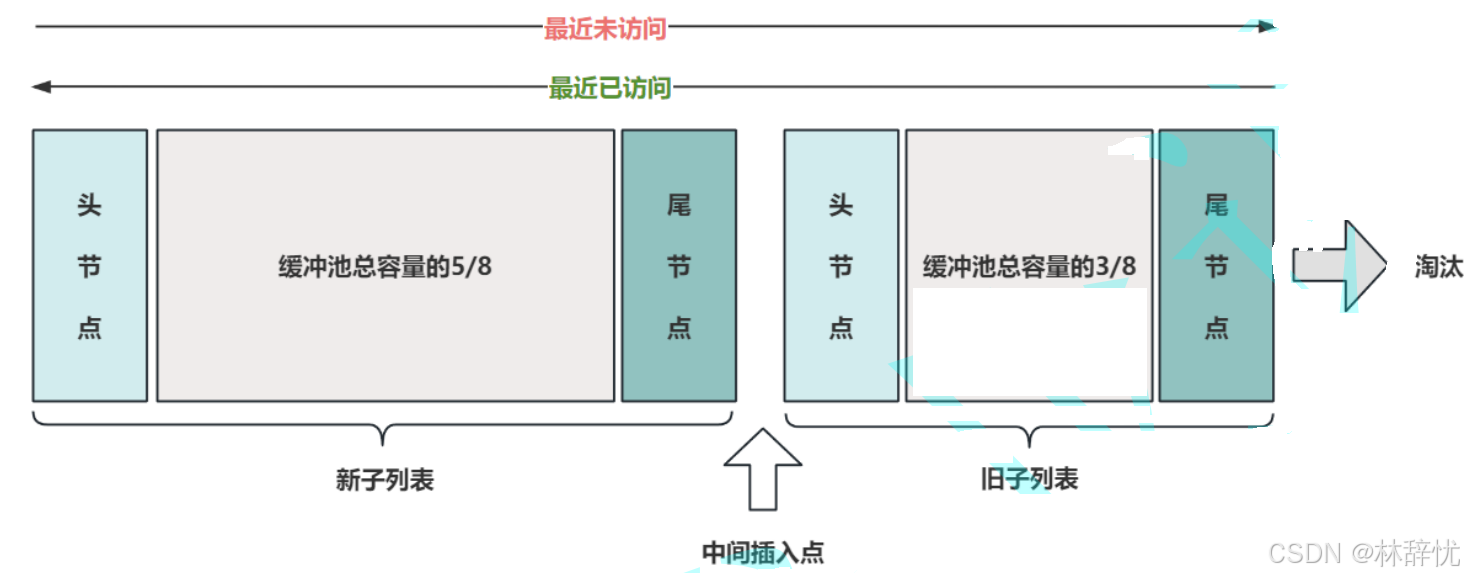
(3)经常使⽤的⻚保存在新⼦列表中,较少使⽤的⻚保存在旧⼦列表中,随着时间的推移,旧⼦列表中的⻚将会逐渐被淘汰。默认情况下,算法的执⾏过程如下:1.缓冲池总容量的 5/8 ⽤于新⼦列表,3/8⽤于旧⼦列表;2.列表的中间插⼊点是新⼦列表的尾部与旧⼦列表头部的交界;3.当⼀个⻚被读⼊缓冲池时,⾸先插⼊到中点做为旧⼦列表的头节点;4.当访问的⻚在旧⼦列表中时,把被访问的⻚移动到新⼦列表的头部,使其成为 "新" ⻚;5.数据库运⾏的过程中,缓冲池中被访问⻚⾯的位置不断更新,未访问的⻚⾯向列表的尾部移动,从⽽逐渐"变⽼" ,最终超出缓冲池容量的⻚从旧⼦列表的尾部被淘汰。解答问题:缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法衍⽣问题:1.为什么要把⻚插⼊到中间⽽不是直接插⼊到新⼦列表的头部?因为InnoDB在读取⻚时,可能会发⽣"预读",预读的意思是InnoDB根据当前访问的记录⾃动推断后⾯可能会访问哪个⻚,并把他们提前加载到内存中,减少一次磁盘的IO,从⽽提⾼以后查询的效率,预读的⻚以并不⼀定会被真正的读取,从中间点插⼊可以使其尽快被淘汰。
5.怎么查看当前缓冲池的信息?
解答问题
通过使⽤ SHOW ENGINE InnoDB STATUS 访问 InnoDB 标准监视器输出中 BUFFER POOL AND MEMORY 部分查看有关缓冲池的指标。缓冲池指标位于InnoDB标准监视器输出的缓冲池和内存部分:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
... # 省略
----------------------
BUFFER POOL AND MEMORY # 缓冲池和内存
----------------------
Total large memory allocated 2198863872 # 为缓冲池分配的总内存,以字节为单位
Dictionary memory allocated 776332 # 为InnoDB数据字典分配的总内存,以字节为单
位
Buffer pool size 131072 # 分配给缓冲池的总⻚⼤⼩
Free buffers 124908 # 缓冲池空闲列表的总⻚⼤⼩
Database pages 5720 # 缓冲池LRU列表的总分⻚⼤⼩
Old database pages 2071 # 缓冲池旧⼦列表的总⻚⼤⼩
Modified db pages 910 # 缓冲池中当前修改的⻚数(脏⻚)
Pending reads 0 # 等待读⼊缓冲池的⻚数
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not
0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read
ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]⼩结
1.缓冲池是⽤来缓存各种数据,最主要的就是缓存从磁盘中加载的数据⻚,从⽽提升效率2.缓冲池为了⽅便数据组织定义了不同的数据结构,包括 Instances 实例, Chunk块,其中 Buffer Pool 中包含⾄少⼀个 Instances , Instances 包含⾄少⼀个Chunk 块, Chunk 管理若⼲个从磁盘加载到内存的 Page 数据⻚3.缓冲池通过三个链表管理内存中的数据⻚,分别是 Free List 、 LRU List 和 Flush List4.缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法
变更缓冲区 - Change Buffer
变量缓冲区在内存中的位置:
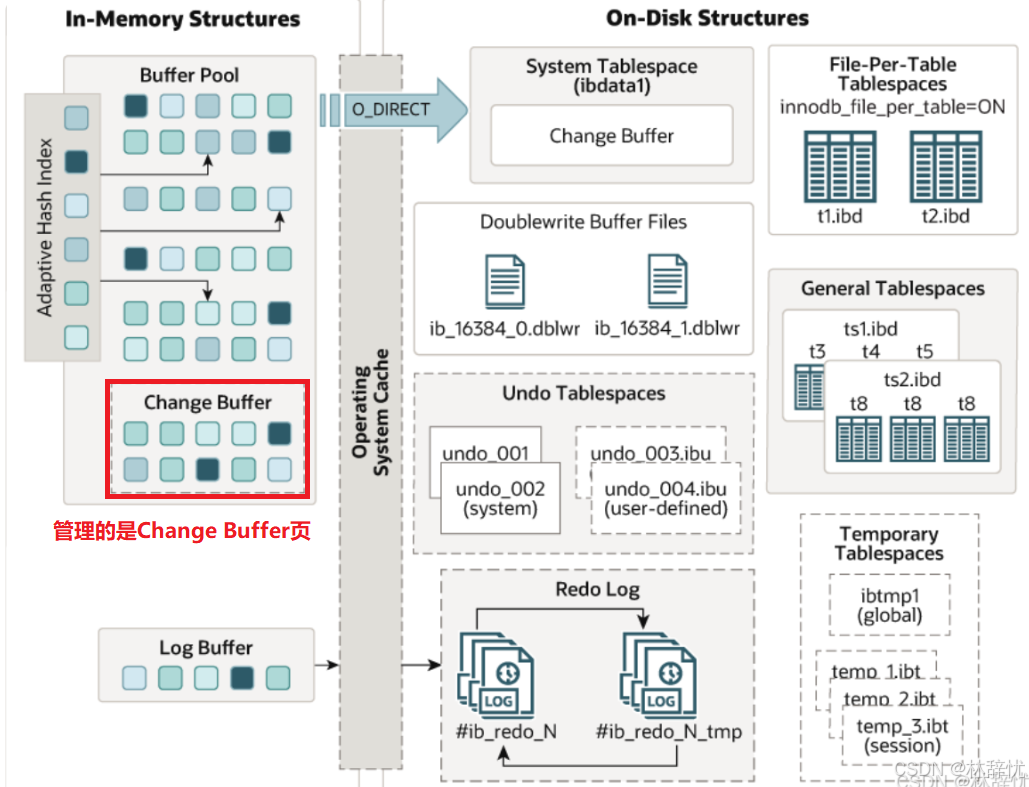
1.变更缓冲区的作⽤?--提升修改数据时的效率
前置知识:
场景:当要修改一条数据时,内存与磁盘之间的交互过程

那么一次磁盘IO能不能完成对数据的修改?,接下来将介绍
分析过程:1.变更缓冲区占⽤Buffer Pool的⼀部分空间,具体如图所⽰:
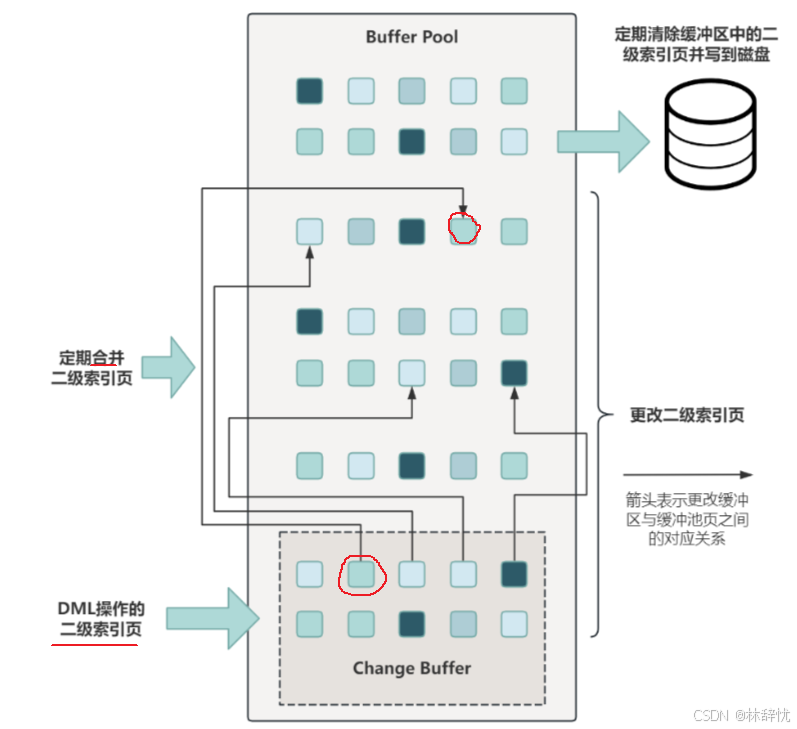
2.变更缓冲区⽤来缓存对⼆级索引数据的修改,是⼀个特殊的数据结构,当使⽤ INSERT 、
UPDATE 或 DELETE 语句修改⼆级索引对应的数据时,如果对应的数据⻚在缓冲池中则直接更新,如果不在缓冲池中,那么就把修改操作缓存到变更缓冲区,这样就不⽤⽴即从磁盘读取对应的数据⻚了,当之后的读操作将对应的数据⻚从磁盘加载到缓冲池中时,变更缓冲区中缓存的修改操作再批量合并到缓冲池,从⽽达到减少磁盘I/O的⽬的。执⾏流程如图⽰:
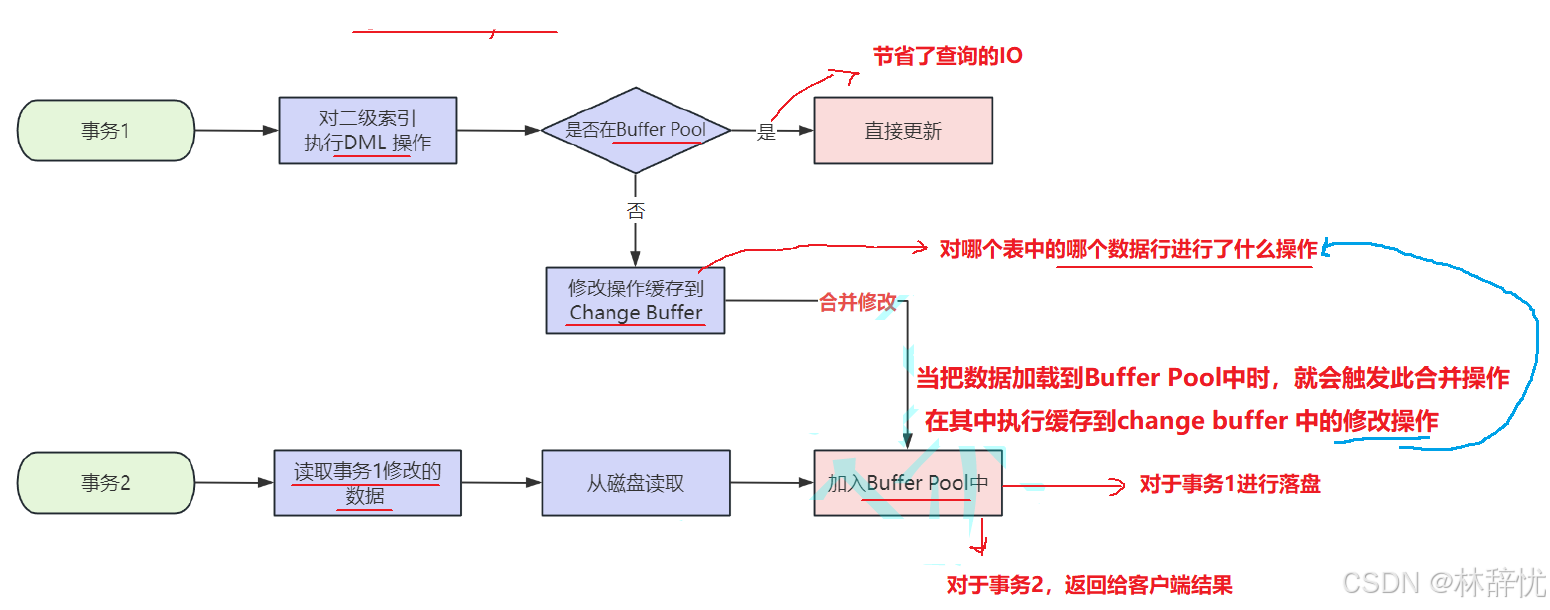
解答问题 :变更缓冲区⽤来缓存对⼆级索引数据的修改,当数据⻚没有被回载到内存中时先把修改缓存起来,等到其他查询操作发⽣时数据⻚被加载到内存后,再直接修改内存中的数据⻚,从⽽达到减少磁盘I/O的⽬的衍⽣问题:
1.为什么是⼆级索引?
(1)索引分为聚集索引(主键)和⼆级索引(⾃定义的为频繁使用的列所创建的索引)
(2)由于聚集索引具有唯⼀性,我们分析⼀下聚集索引为什么不能被放⼊变更缓存,假设表中有⼀个主键( ID ),现在有两条 INSER 语句,都在插⼊数据时ID的值相同 (id=1) ,那么在变更缓冲区中就存在两个修改操作,如果以后要合并到缓冲池中,这时就会出现重复的主键值,所以聚集索引的修改不能被加⼊到变更缓冲区;还有下图的一种情况可以说明
(3)与聚集索引不同,⼆级索引通常是不唯⼀的,并且向⼆级索引中插⼊数据时由于数据列不同,所以位置相对随机,同样对于删除和更新操作可能会影响不相邻的⼆级索引⻚,如果每次都从磁盘读取数据就会发⽣⼤量的随机I/O,以变更缓冲区的⽅式先将修改缓存起来,当真正的读取数据时再把修改合并到缓冲池中可以提升效率。

2.Merge的触发时机有哪些?
(1)读取对应的数据⻚时;(2)当系统空闲或者 Slow Shutdown 时,主线程发起 merge ;(3)Change buffer 的内存空间即将耗尽时;
(4)Redo Log 写满时。
2.变更缓冲区的主要配置项都有哪些?
分析过程:
主要的配置项有缓冲类型和更改缓冲区的最⼤⼤⼩
1.缓冲类型
(1)在修改⼆级索引数据时变更缓冲区可以减少磁盘I/O从⽽提⾼效率,但是变更缓冲区占⽤了缓冲池的⼀部分空间,从⽽减少了可⽤于缓存数据⻚的内存,如果业务场景读多写少,或者表中的⼆级索引相对较少,那么可以考虑禁⽤更改缓冲从⽽提⾼缓冲池空间。(2) 可以通过选项⽂件或 SET GLOBAL 语句对系统变量 innodb_change_buffering 进⾏设置,来控制变更缓冲区对于插⼊、删除操作(索引记录被标记为删除)和清除操作(当索引记录被物理删除时)的开启或禁⽤:删除操作:索引记录被标记为删除清除操作:索引记录被物理删除时更新操作:是插⼊和删除操作的组合
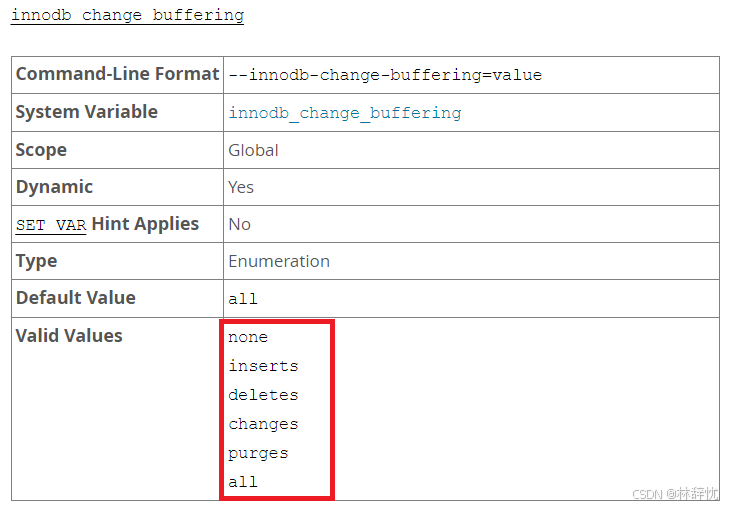
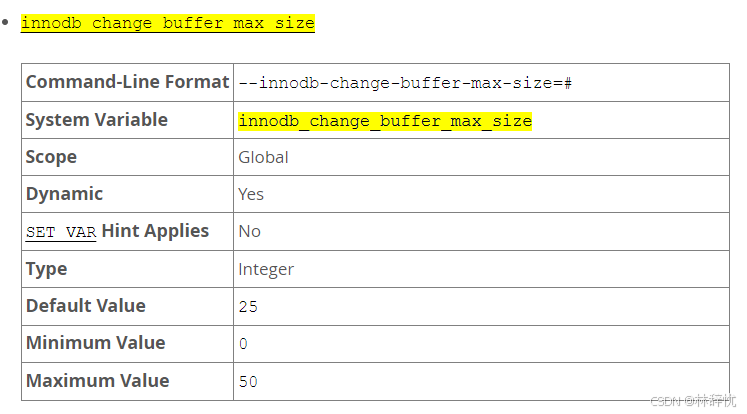
all : 默认值,缓存插⼊、删除标记操作和清除none :不缓存任何操作inserts :只缓存插⼊操作deletes :只缓存删除标记操作changes :缓存插⼊和删除标记操作purges :缓存发⽣在后台的物理删除操作2. 更改缓冲区的最⼤⼤⼩(1)通过 innodb_change_buffer_max_size 系统变量可以设置更改缓冲区的最⼤⼤⼩,默认为25,最⼤为50,表⽰更改缓冲区占缓冲池内存总⼤⼩的百分⽐。(2)在有⼤量插⼊、更新和删除的业务场景中,可以考虑增加 innodb_change_buffer_max_size 的值,在⼤部分是读多写少,⽐如⽤于报表的静态数据场景中考虑减⼩ innodb_change_buffer_max_size 的值(3)需要注意的是,如果更改缓冲区占了缓冲池太多的内存空间,会导致缓冲池中的数据⻚更快地淘汰。
解答问题主要的配置项有缓冲类型和更改缓冲区的最⼤⼤⼩衍⽣问题1. 怎么查看当前变更缓冲区的信息?通过使⽤ SHOW ENGINE InnoDB STATUS 访问 InnoDB 标准监视器输出中 INSERTBUFFER AND ADAPTIVE HASH INDEX 部分查看有关更改缓冲区状态的信息。
⾃适应哈希索引
⾃适应哈希索引在内存中的位置
1.⾃适应哈希索引的作⽤?
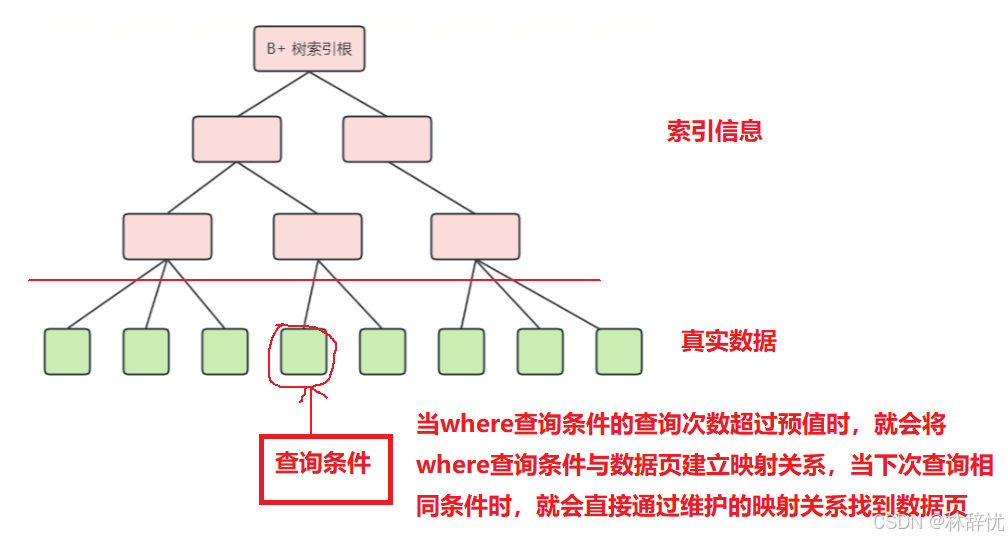
分析过程:1. ⾃适应哈希索引可以使InnoDB存储引擎在不牺牲事务特性和可靠性以及缓冲池空间⾜够的前提下 提升效率,使⽤起来更像是⼀个内存数据库,哈希索引根据经常访问的索引⻚⾃动构建;2. 根据InnoDB内部的监控机制,如果监控到某些查询通过建⽴哈希索引可以提⾼性能,则⾃动对这 个⻚创建哈希索引,这个过程称为⾃适应,所以叫⾃适应哈希索引;3.如果表完全放在内存中,则哈希索引可以通过直接查找任何元素来加快查询速度解答问题⾃适应哈希索引的主要作⽤就是提升查询效率衍⽣问题1. 为什么要创建⾃适应哈希索引?--在内存级别进一步提升查询效率(1)InnoDB存储引擎的数据存储于B+树中,B+树通常只有3到5层,但从根节点到叶节点的寻路涉及到多层⻚⾯内记录的⽐较,即使所有路径上的⻚⾯都在内存中,也⾮常消耗CPU的资源(2)InnoDB对寻路的开销进⾏了优化,⽐如寻路结束后将cursor缓存起来⽅便下次查询复⽤;尽可能的避免单次寻路开销,Adaptive hash index(AHI)便是为此⽽设计,可以理解为B+树的索引(3)本质上是通过缩短寻路路径(Search Path)从⽽提升MySQL查询性能的⼀种⽅式
2.⾃适应哈希索引的Key - Value如何设置?
以查询条件为key,B+树⻚的地址为value的Hash Index3. ⾃适应哈希索引在保存在哪⾥?⾃适应哈希索引会占⽤缓冲池⼀部分内存区域,在缓冲池初始化后被初始化,为了避免AHI的锁竞 争压⼒,AHI⽀持分区,可以使⽤ innodb_adaptive_hash_index_parts 参数配置分区个数,默认为 8 。注意:⾃适应哈希索引是InnoDB内部的优化⽅式,外部不能⼲预
2.关于⾃适应哈希索引有哪些配置项?
解答问题
1.通过设置系统变量 innodb_adaptive_hash_index 开启或关闭⾃适应哈希索引
(1)在选项⽂件中设置系统变量 innodb_adaptive_hash_index=[1|0] 实现开启与关闭(2)通过命令⾏选项 --skip-innodb-adaptive-hash-index 也可以关闭⾃适应哈希索引2. 每个⾃适应散列索引被绑定到不同的分区中,每个分区有不同的锁保护,分区数量由系统变量innodb_adaptive_hash_index_parts 控制,默认置为 8 ,最⼤值为 512衍⽣问题1.怎么查看⾃适应哈希索引的信息?通过使⽤ SHOW ENGINE InnoDB STATUS 访问 InnoDB 标准监视器输出中 INSERT BUFFER AND ADAPTIVE HASH INDEX 部分查看⾃适应哈希索引使⽤信息,如果锁争抢过多,可以考虑增加⾃适应哈希索引分区数量或禁⽤⾃适应哈希索引
⽇志缓冲区
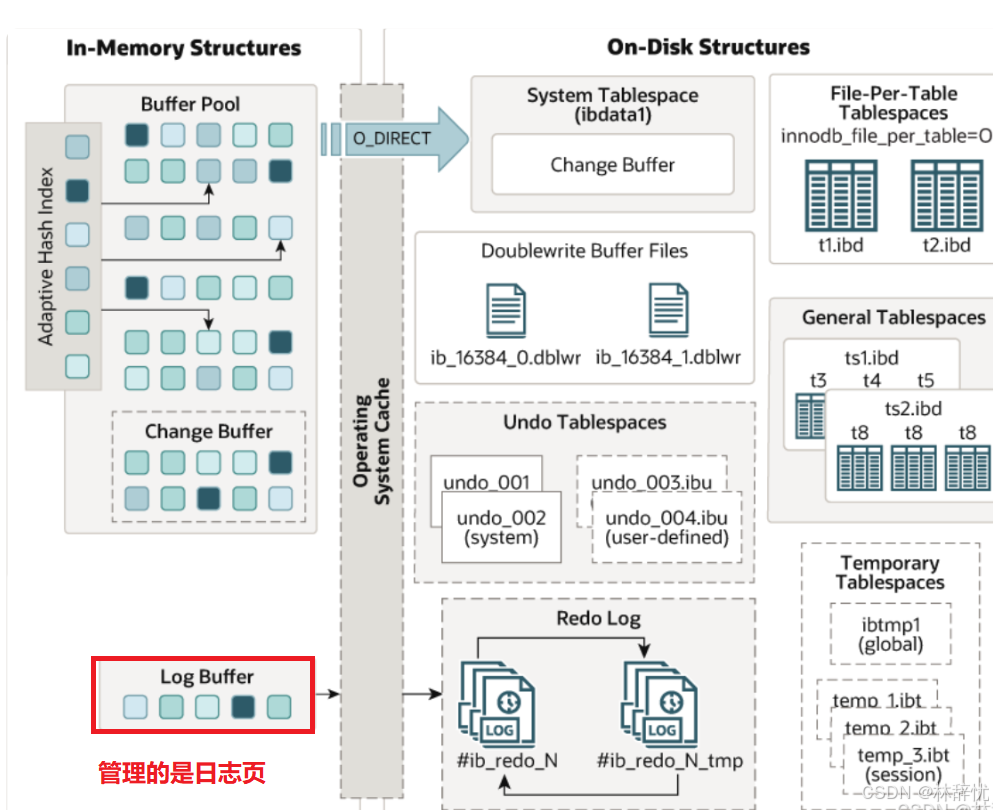
解答问题1.⽇志缓冲区是服务器启动时向操作系统申请的⼀⽚连续的内存区域,存储即将要写⼊磁盘⽇志⽂件的数据(日志)。2.在对数据库进⾏DML操作时,InnoDB会记录对应操作的⽇志,⽐如为保证数据完整性实现数据库崩溃恢复的Redo Log,这些⽇志会⾸先写⼊Log Buffer中,从⽽解决同步写磁盘导致的性能问题,然后根据不同落盘策略最终写⼊磁盘衍⽣问题1.⽇志不通过Log Buffer直接写⼊磁盘不⾏吗?如果⽇志不通过Log Buffer直接写⼊磁盘,那么每次进⾏DML操作都会进⾏⼀次磁盘I/O,这样会严重影响效率,所以把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,可以实现⼀次磁盘I/O写⼊多条⽇志,从⽽提升效率
内存结构的小结
1.InnoDB内存结构主要分为:(1)Buffer Pool 缓冲池、(2)Change Buffer 变更缓冲区(3)adaptive_hash_index ⾃适应哈希索引(4)Log Buffer ⽇志缓冲区2.缓冲池(1)内存中的主要⼯作区域
(2)缓冲池中包含⾄少⼀个 Instances ,每个 Instances 中包含⾄少⼀个 Chunk , Chunk 管理着多个数据⻚(3)缓冲池中使⽤控制块与数据⻚建⽴对应关系,通过双向链表连接每个控制块,从⽽管理数据⻚(4)缓冲池中有三个链表分别是 Free List 、 LRU List 和 Flush List :Free List :只管理Free ⻚LRU List :管理 Clean⻚和Dirty⻚Flush List :只管理Dirty⻚(5)缓冲池淘汰策略采⽤变形的最近最少使⽤算法LRU3.变更缓冲区⽤来缓存对⼆级索引数据的修改,从⽽减少磁盘的IO次数以提升效率4.⾃适应哈希索引为频繁使⽤的查询条件和对应的数据⻚建⽴映射关系,从⽽提升内存级别的查询效率5.⽇志缓冲区把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,从⽽减少磁盘的IO次数以提升效率


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









