



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥第一部分——内容介绍

Picard迭代在非线性常微分方程参数估计中的应用研究
摘要:本文聚焦于利用实验时间序列数据对非线性常微分方程进行参数估计这一复杂问题,着重应对数据含噪、稀疏、非均匀采样、包含多组实验且无法直接测量系统状态或其时间导数等低质量数据所带来的挑战。提出了一种基于梯度的参数估计框架,借助Picard算子将原问题重构为含无限维变量与约束的约束优化问题。利用Picard算子的收缩性质设计了“梯度 - 收缩”算法,并给出算法收敛到局部最优的充分条件。通过在多种模型与数据集上的系统测试,验证了该算法的鲁棒性,且证明其相较于现有方法具有显著改进。
关键词:非线性常微分方程;参数估计;Picard迭代;低质量数据;梯度 - 收缩算法
一、引言
非线性常微分方程在众多科学和工程领域,如生物医学、化学反应动力学、物理学等,有着广泛的应用,用于描述复杂的动态系统行为。然而,这些方程中的参数往往难以直接确定,需要通过实验数据来估计。但在实际实验中,所获取的数据质量通常较低,存在含噪、稀疏、非均匀采样等问题,并且可能无法直接测量系统状态或其时间导数,同时数据可能来自多组实验,这些因素都给参数估计带来了极大的困难。
现有的参数估计方法在处理这些低质量数据时存在诸多局限性。一些方法对数据质量要求较高,在面对含噪或稀疏数据时估计结果不准确;另一些方法在处理多组实验数据时,难以有效整合信息,导致估计效率低下。因此,迫切需要一种能够适应低质量数据、具有良好鲁棒性的参数估计方法。
Picard迭代作为一种经典的迭代方法,在求解常微分方程的数值解方面有着悠久的历史和广泛的应用。其基本思想是通过不断迭代来逼近方程的解,具有收敛性良好等优点。本文将Picard迭代的思想引入到非线性常微分方程的参数估计中,提出一种新的基于梯度的参数估计框架,以解决上述低质量数据下的参数估计难题。
二、问题描述与数学模型
2.1 非线性常微分方程的一般形式
考虑一般的非线性常微分方程系统:

2.2 低质量数据的特点
在实际实验中,我们获取的数据通常具有以下特点:
- 含噪:测量数据中包含随机噪声,即观测到的数据 y(ti)=x(ti)+ϵi,其中 ϵi是噪声向量。
- 稀疏:数据采样点较少,时间间隔可能较大,导致信息不完整。
- 非均匀采样:采样时间点 ti不是均匀分布的,可能根据实验条件随机变化。
- 无法直接测量状态或导数:只能测量系统的部分输出或与状态相关的某些量,无法直接获取 x(t)或 dtdx(t)。
- 多组实验数据:数据可能来自多组不同的实验,每组实验的条件可能略有差异。
2.3 参数估计问题的数学表述

三、基于Picard算子的参数估计框架
3.1 Picard算子的定义

3.2 问题重构
为了将参数估计问题转化为一个更易于处理的形式,我们借助Picard算子将原问题重构为含无限维变量与约束的约束优化问题。定义一个函数空间 H,其中的元素是定义在时间区间 [t0,tf]上的连续函数。引入无限维变量 z(t)∈H,考虑以下约束优化问题:

3.3 梯度 - 收缩算法设计
利用Picard算子的收缩性质,我们设计了一类“梯度 - 收缩”算法来求解上述约束优化问题。该算法的基本思想是在每一步迭代中,先沿着损失函数的负梯度方向更新参数 θ,然后利用Picard算子的收缩性质对函数 z(t)进行更新,使其更接近Picard算子的不动点。
具体步骤如下:

3.4 收敛性分析
为了保证“梯度 - 收缩”算法能够收敛到局部最优,我们给出了以下充分条件:
- 损失函数的可微性:损失函数 L(θ)关于 θ是可微的,且其梯度 ∇θL(θ)是Lipschitz连续的。
- Picard算子的收缩性质:Picard算子 T在函数空间 H上是收缩的,即存在常数 0<LT<1,使得对于任意的 z1(t),z2(t)∈H,有 ∥T(z1)(t)−T(z2)(t)∥≤LT∥z1(t)−z2(t)∥。
- 步长和收缩因子的选择:步长 αk和收缩因子 βk的选择满足一定的条件,例如 ∑k=0∞αk=∞,∑k=0∞αk2<∞,且 βk在一定范围内变化。
在这些条件下,可以证明“梯度 - 收缩”算法生成的序列 {(θk,zk(t))}会收敛到约束优化问题的一个局部最优解。
四、实验验证
4.1 实验设置
为了验证“梯度 - 收缩”算法的鲁棒性和有效性,我们在多种模型与数据集上进行了系统测试。选择了几个具有代表性的非线性常微分方程模型,如Lotka - Volterra模型、Van der Pol振子模型等。对于每个模型,生成了不同质量的模拟数据,包括含噪、稀疏、非均匀采样等情况,同时也考虑了多组实验数据的整合。
4.2 对比方法
将“梯度 - 收缩”算法与现有的几种常用参数估计方法进行对比,包括最小二乘法、梯度下降法、遗传算法等。这些方法在不同的数据质量条件下都有一定的应用,但在处理低质量数据时存在各自的局限性。
4.3 实验结果
实验结果表明,“梯度 - 收缩”算法在处理低质量数据时具有显著的优势。在含噪数据情况下,该算法能够更好地抑制噪声的影响,估计出的参数更接近真实值;对于稀疏和非均匀采样数据,算法能够充分利用有限的信息,通过Picard算子的迭代更新,逐步逼近真实解;在多组实验数据整合方面,算法能够有效地融合不同组数据的信息,提高估计的准确性和鲁棒性。与对比方法相比,“梯度 - 收缩”算法在估计误差、收敛速度等方面都有明显的改进。
五、结论与展望
本文提出了一种基于Picard迭代的新框架用于非线性常微分方程的参数估计,通过将原问题重构为含无限维变量与约束的约束优化问题,并利用Picard算子的收缩性质设计了“梯度 - 收缩”算法。理论分析证明了算法的收敛性,实验验证了算法在处理低质量数据时的鲁棒性和有效性,相较于现有方法具有显著改进。
未来的研究可以进一步探索如何优化算法的性能,例如改进步长和收缩因子的选择策略,以提高算法的收敛速度和估计精度。同时,可以将该算法应用到更多实际领域的复杂系统中,解决更多的实际问题。此外,还可以研究如何结合其他先进的技术,如深度学习等,进一步提升参数估计的能力。
综上所述,基于Picard迭代的参数估计框架为非线性常微分方程的参数估计提供了一种新的有效方法,具有广阔的应用前景和研究价值。
📚第二部分——运行结果
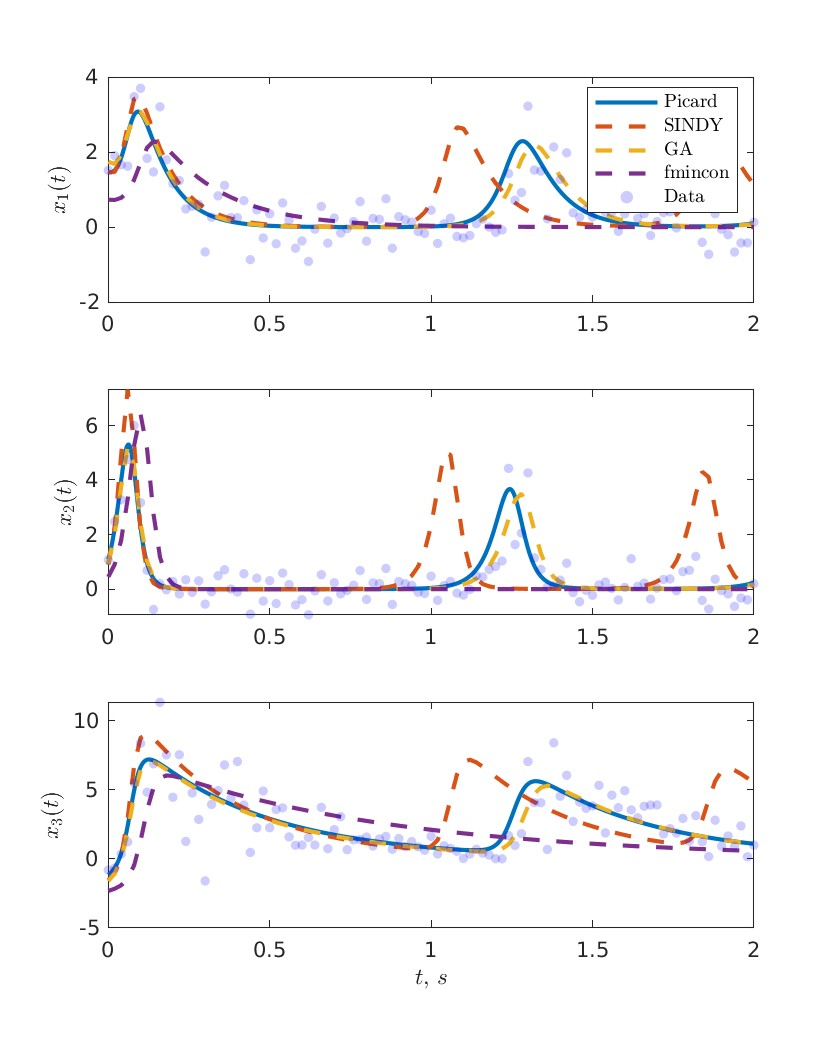
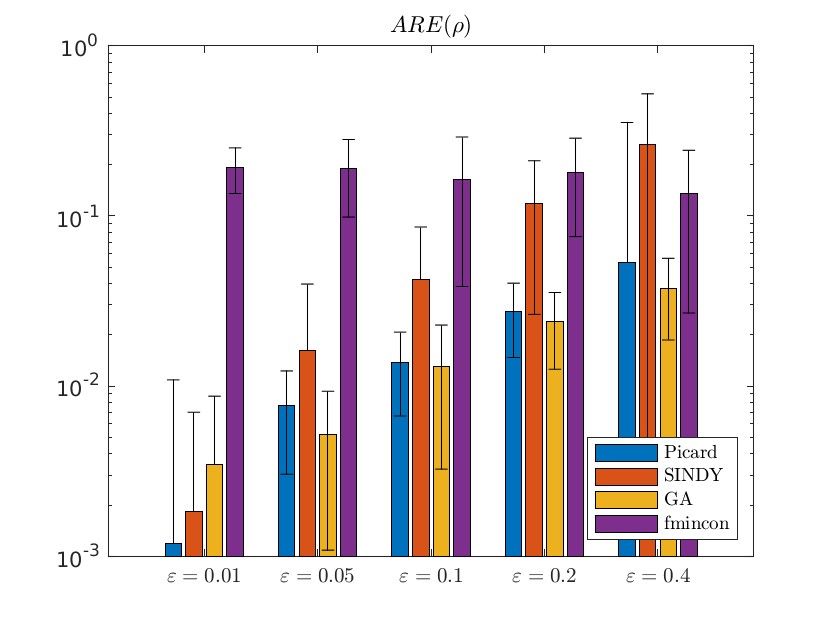
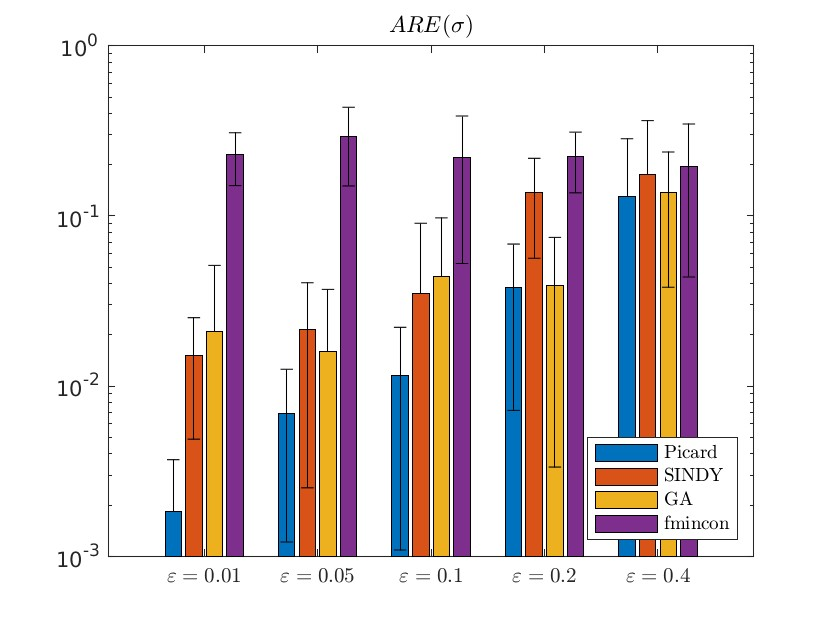
部分代码:
function [] = plot_VDP_results(ARE1, ARE2, loss_struc1, loss_struc2)
PLOT_DIR = '../results/VDP';
mkdir(PLOT_DIR)
epss = [0.01, 0.05, 0.1, 0.2, 0.4];
lambdas = [1, 2, 5, 10, 15];
bar_names = {};lambda_names = {};
for j = 1:length(epss)
bar_names{j} = ['$\varepsilon = ' , num2str(epss(j)), '$'];
end
X = categorical(bar_names);
for j = 1:length(lambdas)
lambda_names{j} = ['$\lambda = ' , num2str(lambdas(j)), '$'];
end
% % computing loss for N_s = 101
bar_values = [];std_values = [];
for i = 1:length(loss_struc1)
bar_values = [bar_values; mean(loss_struc1{i}')];
std_values = [std_values; std(loss_struc1{i}')];
end
% bar_values = [bar_values; mean(loss1_lambda15')];
% std_values = [std_values; std(loss1_lambda15')];
% bar_values = [bar_values; mean(loss1_lambda20')];
% std_values = [std_values; std(loss1_lambda20')];
% bar_values = [bar_values; mean(loss1_lambda25')];
% std_values = [std_values; std(loss1_lambda25')];
f = figure(1);
f.Position = [100 100 400 300];
clf;
hold on
b = bar(X, bar_values');
ylim([0.0005, 2])
set(gca, 'YScale', 'log', ...
'FontSize',10)
nbars = length(epss); ngroups = length(b);
% % Get the x coordinate of the bars
x = nan(ngroups, nbars);
for i = 1:ngroups
x(i,:) = b(i).XEndPoints;
end
% % Plot the errorbars
errorbar(x,bar_values,std_values,'black','linestyle','none');
title('Loss function for $N_s = 101$', 'Interpreter', 'latex')
legend(lambda_names, 'Location', 'northwest', 'Interpreter', 'latex')
xaxisproperties= get(gca, 'XAxis');
xaxisproperties.TickLabelInterpreter = 'latex'; % latex for x-axis
hold off
saveas(f, [PLOT_DIR, '/Loss_function_VDP_Ns=101.jpg'])
saveas(f, [PLOT_DIR, '/Loss_function_VDP_Ns=101.eps'])
saveas(f, [PLOT_DIR, '/Loss_function_VDP_Ns=101.pdf'])
% % computing loss for N_s = 51
bar_values = [];
std_values = [];
for i = 1:length(loss_struc2)
bar_values = [bar_values; mean(loss_struc2{i}')];
std_values = [std_values; std(loss_struc2{i}')];
end
% bar_values = [bar_values; mean(loss2_lambda15')];
% std_values = [std_values; std(loss2_lambda15')];
% bar_values = [bar_values; mean(loss2_lambda20')];
% std_values = [std_values; std(loss2_lambda20')];
% bar_values = [bar_values; mean(loss2_lambda25')];
% std_values = [std_values; std(loss2_lambda25')];
f = figure(2);
f.Position = [100 100 400 300];
clf;
hold on
bar(X, bar_values')
ylim([0.0005, 2])
set(gca, 'YScale', 'log', ...
'FontSize',10)
title('Loss function for $N_s = 51$', 'Interpreter', 'latex')
nbars = length(epss); ngroups = length(b);
% % Get the x coordinate of the bars
x = nan(ngroups, nbars);
for i = 1:ngroups
x(i,:) = b(i).XEndPoints;
end
% % Plot the errorbars
errorbar(x,bar_values,std_values,'black','linestyle','none', 'CapSize',4);
legend(lambda_names, 'Location', 'northwest', 'Interpreter', 'latex')
xaxisproperties= get(gca, 'XAxis');
xaxisproperties.TickLabelInterpreter = 'latex'; % latex for x-axis
saveas(f, [PLOT_DIR, '/Loss_function_VDPfull_Ns=51.jpg'])
saveas(f, [PLOT_DIR, '/Loss_function_VDPfull_Ns=51.eps'])
saveas(f, [PLOT_DIR, '/Loss_function_VDPfull_Ns=51.pdf'])
hold off
% computing loss for N_s = 101
bar_values = [];std_values = [];
for i = 1:length(lambdas)
bar_values = [bar_values; mean(ARE1{i}')];
std_values = [std_values; std(ARE1{i}')];
end
f = figure(3);
f.Position = [100 100 400 300];
clf;
hold on
b = bar(X, bar_values');
ylim([0.001, 2])
set(gca, 'YScale', 'log', ...
'FontSize',10)
title('$ARE(\theta_1) + ARE(\theta_2)$ for $N_s = 101$', 'Interpreter', 'latex')
nbars = length(epss); ngroups = length(b);
% Get the x coordinate of the bars
x = nan(ngroups, nbars);
for i = 1:ngroups
x(i,:) = b(i).XEndPoints;
end
% Plot the errorbars
errorbar(x,bar_values,std_values,'black','linestyle','none', 'CapSize',4);
legend(lambda_names, 'Location', 'northwest', 'Interpreter', 'latex')
xaxisproperties= get(gca, 'XAxis');
xaxisproperties.TickLabelInterpreter = 'latex'; % latex for x-axis
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=101.jpg'])
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=101.eps'])
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=101.pdf'])
hold off
% computing ARE for N_s = 51
bar_values = [];std_values = [];
for i = 1:length(lambdas)
bar_values = [bar_values; mean(ARE2{i}')];
std_values = [std_values; std(ARE2{i}')];
end
f = figure(4);
f.Position = [100 100 400 300];
clf;
hold on
b = bar(X, bar_values');
ylim([0.001, 2])
set(gca, 'YScale', 'log', ...
'FontSize',10)
title('$ARE(\theta_1) + ARE(\theta_2)$ for $N_s = 51$', 'Interpreter', 'latex')
nbars = length(epss); ngroups = length(b);
% Get the x coordinate of the bars
x = nan(ngroups, nbars);
for i = 1:ngroups
x(i,:) = b(i).XEndPoints;
end
% Plot the errorbars
errorbar(x,bar_values,std_values,'black','linestyle','none', 'CapSize',4);
legend(lambda_names, 'Location', 'northwest', 'Interpreter', 'latex')
xaxisproperties= get(gca, 'XAxis');
xaxisproperties.TickLabelInterpreter = 'latex'; % latex for x-axis
legend(lambda_names, 'Location', 'northwest', 'Interpreter', 'latex')
xaxisproperties= get(gca, 'XAxis');
xaxisproperties.TickLabelInterpreter = 'latex'; % latex for x-axis
hold off
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=51.jpg'])
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=51.eps'])
saveas(f, [PLOT_DIR, '/ARE_VDPfull_Ns=51.pdf'])
end
🎉第三部分——参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈第四部分——本文完整资源下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python|数据|文档等完整资源获取


















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









