




“使用大模型时,我们经常会看到诸如“参数量”、“Token”、“上下文窗口”、“上下文长度”和“温度”等术语,这些术语代表着什么意思?它们对AI大模型有什么作用?”
参数量:模型的复杂度和性能指标
现在的大模型基本上都是基于Transformer神经网络架构,大模型的“大”也正是基于其参数量(Parameters)大(参见AI|大模型入门(一))。
神经网络中的参数是指连接神经元的权重和偏差,它们决定了神经元之间的传递和网络的输出。参数计算是神经网络设计和训练过程中的重要环节,其目的是为了确定每个神经元的权重和偏差,从而使神经网络能够学习并模拟给定的输入输出关系。
因此,大模型中的参数量(Parameter Count or Number of Parameters)指的是模型中所有可训练的权重(weights)和偏置(biases)的总数。这些参数是模型在训练过程中学习得到的,用于执行特定的任务,如语言理解、图像识别等。通常情况下,参数量越多,模型的表现力越强,但同时也意味着模型的计算复杂度和训练时间会增加。
大参数量的模型可以更好地理解和生成自然语言。例如,GPT-4模型的参数量达到了万亿级别,约为1.8万亿,可以实现对自然语言的生成和理解。
然而,大参数量的模型也存在一些问题。例如,模型的训练时间长,计算复杂度高,需要大量的计算资源。例如,OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,训练一次的成本大约是6300万美元。此外,模型的参数量过多,容易出现过拟合现象,导致模型在实际应用中的泛化能力下降。
详细来说,参数量是衡量模型复杂度的一个重要指标,它影响着大模型的以下方面:
-
学习能力:更多的参数通常意味着模型有更大的能力来捕捉数据中的复杂模式。
-
计算成本:参数量越多,模型的计算需求越高,这可能需要更多的内存和计算时间。
-
存储需求:模型的参数需要存储在内存或硬盘上,参数量越多,所需的存储空间也越大。
-
泛化能力:理论上,参数量较多的模型在训练数据上能够更好地拟合,但也可能面临过拟合的风险,即在训练数据上表现良好,但在未见过的数据上表现不佳。
-
训练数据需求:通常参数量较多的模型需要更多的训练数据来有效地学习,以避免过拟合。
在大型语言模型(如BERT、GPT等)中,参数量可能达到数十亿甚至数百亿。这些模型能够处理复杂的任务,但同时也需要大量的计算资源和训练数据。确定模型的参数量是一个权衡过程,需要考虑到模型的性能、资源限制和任务需求。总的来说,我们需要根据具体场景和需求来选择合适的模型参数量,以实现最佳的模型表现。
Token:模型理解和处理的基本单位
在大模型中,Token是指模型处理的基本数据单位。它可以是单词、字符、短语甚至图像片段、声音片段等。例如,一句话会被分割成多个Token,每个标点符号也会被视为单独的Token。
举个例子,如下图,“你好,我是公众号云网记,请多多关照!”这句话包含标点符号在内共18个字,它被分成了20个Token,每个Token都有一个独一无二的编码(Token ID),如下图所示。
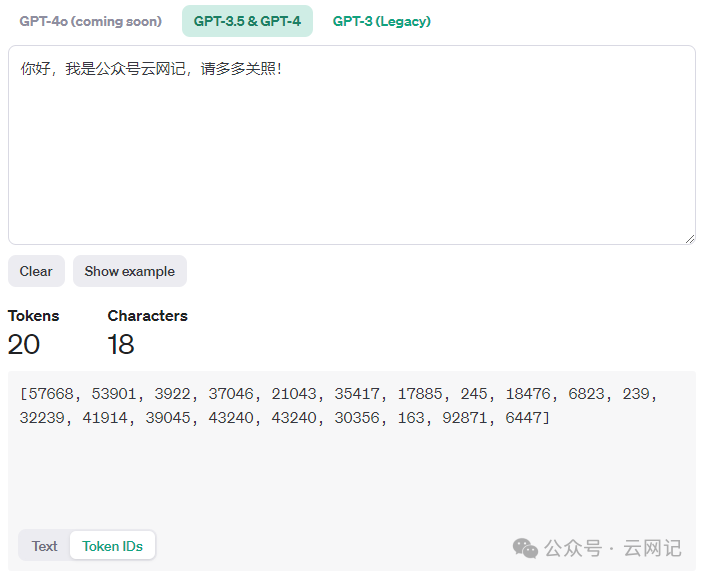
Token的划分方式会影响模型对数据的理解和处理。例如,中英文的Token 划分方式就存在差异。对于中文,由于存在多音字和词组的情况,Token的划分需要更加细致。
上下文窗口:捕捉信息的范围
一、上下文窗口是什么
我们知道大模型大都是基于Transformer架构的(AI|大模型入门(一)),上下文窗口(Context Window)是Transformer一次可以处理的最大序列长度,即在进行预测或生成文本时,所考虑的前一个token或文本片段的大小范围。随着限制Token数量和提示词大小的专有大模型的兴起,以及对检索增强生成(AI|大模型入门(四):检索增强生成(RAG))等技术日益增长的兴趣,理解上下文窗口的关键思想及其含义变得越来越重要,因为这在讨论不同模型时经常被引用。
在大模型中,上下文窗口对于理解和生成与特定上下文相关的文本至关重要。较大的上下文窗口可以提供更丰富的语义信息、消除歧义、处理上下文依赖性,并帮助模型生成连贯、准确的文本,还能更好地捕捉语言的上下文相关性,使得模型能够根据前文来做出更准确的预测或生成。
例如,Moonshot AI(月之暗面)的Kimi Chat支持的上下文窗口大小是20万字(约588KB),可以处理和理解最多20万字的输入和输出。
综上,上下文窗口指的是模型在计算当前词的表示时所考虑的其他词的范围大小。
二、是什么决定了上下文窗口的大小
为了理解这一点,让我们首先回顾一下注意力机制(attention mechanism)是如何工作的(下图)。注意力机制并不关心输入词语的远近距离,而是只关心每个词的权重。在这种机制下,大模型认为你和他说过的所有对话,都对后面的回答是有影响的,因此,它把你问的问题和它前面的回答都作为输入,再综合所有的权重,去寻找下一个词,不断递归,一个词一个词拼接起来,作为答案返回给你。
下图是decoder-only类型的transformer模型的注意力机制工作流程图,LLama-2就是用的这种架构。
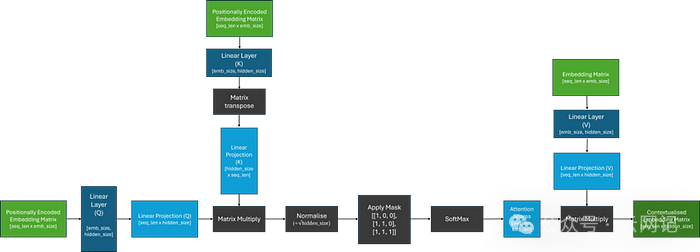
上图中,我们可以看到,注意力分数矩阵的大小是由传递到模型中的序列的长度决定的,并且可以任意增长。也就是说,上下文窗口不是由架构决定的,而是由训练期间给模型的序列长度(即词向量空间)决定的。
注意力机制使用权重理解上下文,这更好的提取了语言的结构,但是没有记住词的先后顺序,因此,大模型使用词向量给每个词位置编码,这就解决了词语先后顺序的问题。但是位置编码的存储空间(词向量空间)是有限的。
而且计算注意力分数的矩阵乘法运算非常昂贵,在没有任何优化的情况下,矩阵乘法在空间复杂度上通常是二次方(平方)关系(O(n^2))。简而言之,如果输入序列的长度增加一倍,所需的内存量就会增加四倍!因此,与训练4k序列长度相比,训练128k序列长度的模型需要大约1024倍的内存。
同时,这种操作对Transformer的每一层和每一个header都要进行一遍,这会导致大量计算的增长。由于模型的参数、任何计算梯度和输入数据共享使用GPU可用存储空间,因此在训练大型模型时,硬件可能很快成为上下文窗口大小的瓶颈。
综上,词向量空间的大小、注意力机制的运算成本决定了上下文窗口的大小。
上下文长度:模型处理能力的上限
一、什么是上下文长度
上下文长度(Context Length)是AI模型一次能够处理的最大Token数量,指的是模型在生成输出时能够一次性考虑的最大输入序列长度,它决定了模型处理能力的上限。上下文长度越大,模型能够处理的数据量就越大。上下文长度决定了模型在生成每个输出时能够一次性"记住"多少信息。
例如,ChatGPT 3.5的上下文长度为4096个Token。这意味着ChatGPT 3.5 无法接受超过4096个Token的输入,也无法一次生成超过4096个Token的输出。
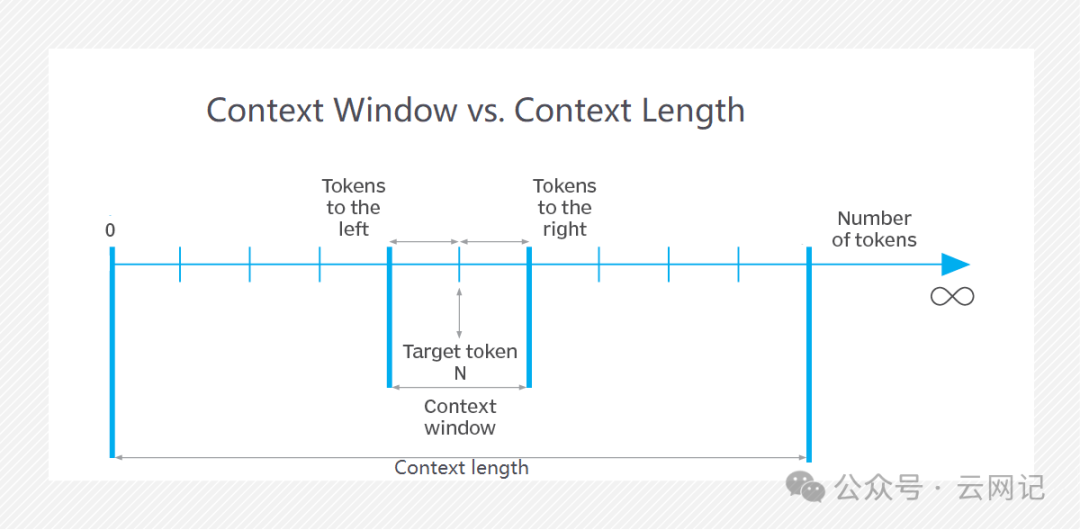
二、上下文窗口 vs. 上下文长度
上下文长度(Context Length)是模型设计时的一个参数,它定义了模型能够处理的最大序列长度。任何给定的输入序列(如一段文本)的长度都不能超过这个上下文长度。
上下文窗口(Context Window),是在预测某个token时模型实际考虑的输入序列的长度。这个窗口小于或等于上下文长度。在某些情况下,模型可能会使用滑动窗口或其他技术来处理超出上下文窗口的较长序列,但这些方法仍然受到上下文长度的限制。
因此,上下文长度是模型能够处理的最大序列长度,而上下文窗口是在实际预测时模型考虑的输入序列的长度。在相同模型中,上下文长度是这两个概念中的“更大的”一个,因为它定义了模型处理能力的上限。上下文窗口则可以根据具体任务的需要进行调整,但不会超过上下文长度。
综上:
1.上下文窗口≤上下文长度。
2.提供大模型的一次输入的长度要考虑上下文长度,大模型处理输入推测下一个词时要考虑上下文窗口。
温度:控制创造性和确定性之间的平衡
大型语言模型(LLMs)被用于各种创造性任务中,它们的输出从优美到奇特、到模仿,再到明显的抄袭不等。
温度(Temperature)参数调节随机性的程度,从而导致更多样化的输出,是控制大模型生成输出随机性的参数。它决定了模型在生成输出时更倾向于创造性还是保守和确定性。因此,它常被称为创造力参数。
温度值越高,模型越倾向于生成随机的、意想不到的输出,但也可能导致语法错误或无意义的文本。温度值越低,模型越倾向于生成符合逻辑和常识的输出,但也可能缺乏创造性和趣味性。
例如,在设置较低温度时,语言模型可能会生成以下句子:“今天天气晴朗,适合户外活动。”而设置较高温度时,模型可能会生成以下句子:“天空像一块巨大的蓝宝石,点缀着棉花糖般的白云。鸟儿在枝头歌唱,微风拂过脸庞,一切都是那么美好。”
学习书籍文档
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

学习视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
项目实战源码
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

参考文献:
1. https://wallstreetcn.com/articles/3692958
2. https://blog.youkuaiyun.com/acelit/article/details/137459237
3. De-Coded: Understanding Context Windows for Transformer Models
https://towardsdatascience.com/de-coded-understanding-context-windows-for-transformer-models-cd1baca6427e
4. https://www.techtarget.com/whatis/definition/context-window


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











