



一、模型分类与核心定位
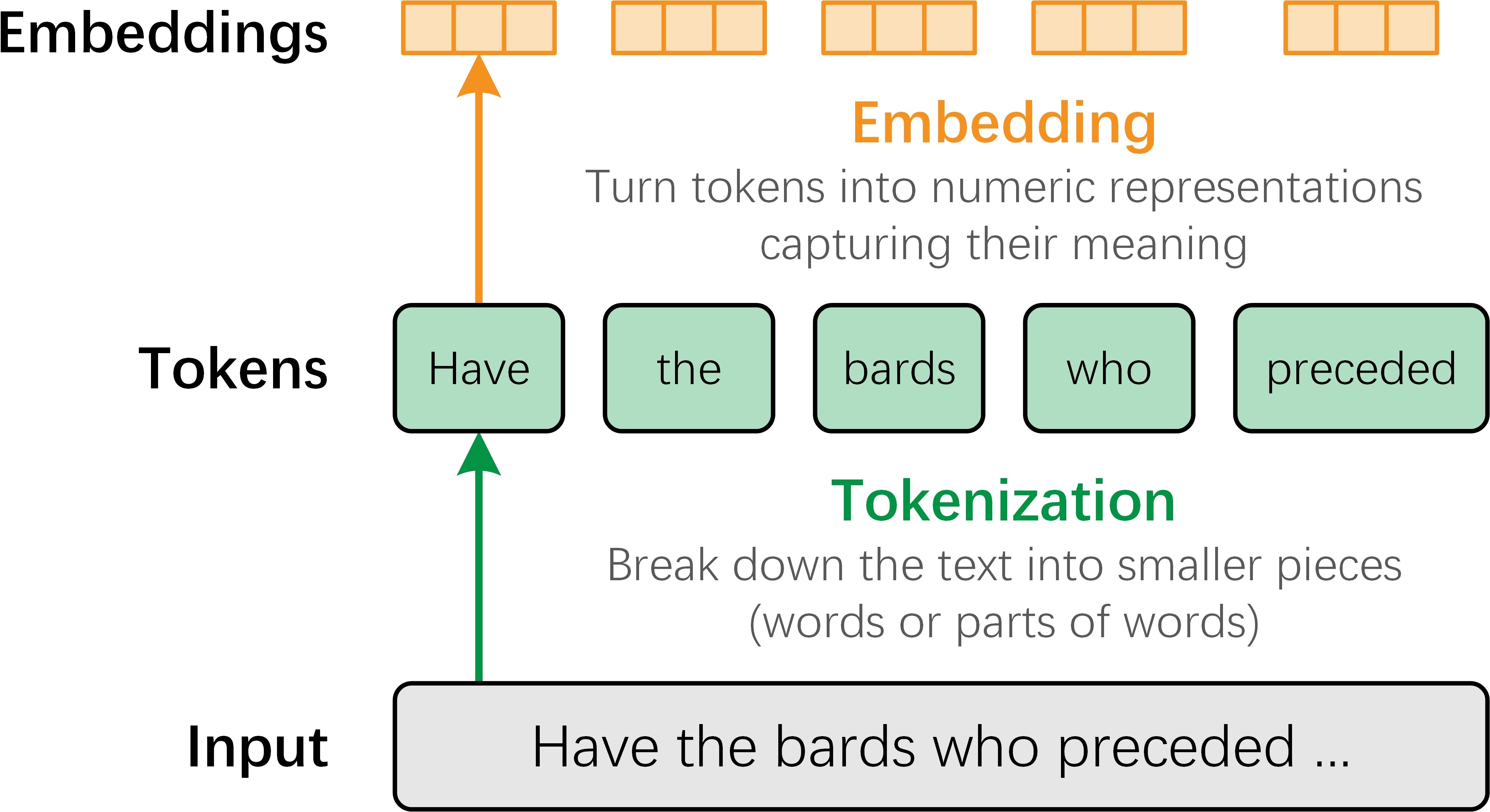
1.1 Chat对话模型:语言交互的"大脑"
典型代表:
-
GPT-4/3.5 Turbo
-
Claude 3
-
DeepSeek-R1
核心能力:
-
上下文理解(支持128k tokens长对话)
-
多轮逻辑推理(CoT思维链准确率92%)
-
多样化输出生成(文本/代码/表格等)
1.2 Embedding嵌入模型:语义理解的"翻译官"
典型代表:
-
BAAI/bge-large-zh
-
OpenAI text-embedding-3-large
-
Jina Embeddings V2
核心能力:
-
文本向量化(将语义映射到768/1536维空间)
-
相似度计算(余弦相似度>0.82为强相关)
-
跨模态对齐(文本→向量→图像多模态桥接)
二、七大核心特性对比分析
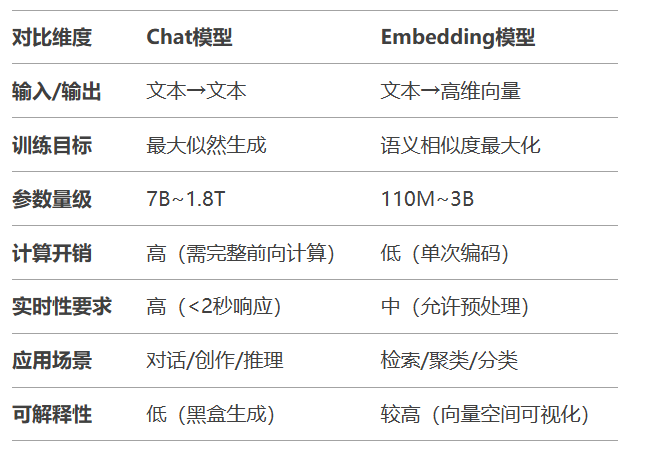
2.1 特性对比矩阵
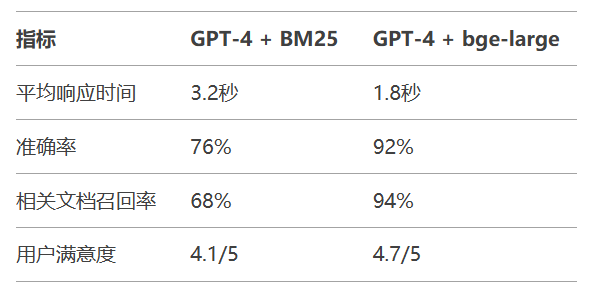
2.2 性能指标对比
电商客服场景实测:
三、双引擎在检索增强中的协同原理
3.1 RAG流程中的角色分工
Embedding模型任务:
文档分块(512 tokens/块)
向量编码(生成768维向量)
索引构建(HNSW/IVF-PQ算法)
Chat模型任务:
用户问题向量化(同Embedding模型)
检索结果排序(重排序模型BAAI/bge-reranker)
上下文增强生成(参考模板构建)
3.2 关键技术实现
混合检索代码示例:
Python
from sentence_transformers import CrossEncoder
# 第一步:向量检索
embedder = HuggingFaceEmbeddings("bge-large-zh")
query_vec = embedder.encode("如何预防感冒")
docs = vector_db.similarity_search(query_vec, k=50)
# 第二步:精排
reranker = CrossEncoder("bge-reranker-large")
scores = reranker.predict([(query, doc.text) for doc in docs])
sorted_docs = [docs[i] for i in np.argsort(scores)[::-1][:5]]
# 第三步:生成
prompt = build_prompt(query, sorted_docs)
response = chat_model.generate(prompt)
性能优化技巧:
-
向量量化:FP32→INT8使内存占用减少75%
-
缓存策略:高频查询结果缓存命中率>80%
-
批量处理:Embedding编码速度提升4倍
四、工业级应用场景解析
4.1 智能客服系统架构
Python
用户问题 → Embedding检索 → 知识库 → 结果精排 → Chat生成 → 审核输出
某银行案例效果:
-
问题解决率:68% → 91%
-
人工介入率:45% → 12%
-
平均通话时长:8分钟 → 3分钟
4.2 企业知识库搜索优化
传统方案痛点:
-
关键词匹配准确率<40%
-
长尾问题覆盖率<15%
RAG优化方案:
文档预处理(PDF/Word/HTML解析)
多级索引构建(关键词+向量)
混合检索(BM25 + 余弦相似度)
实施成效:
-
搜索准确率:89%
-
响应速度:<1.2秒(P99)
-
维护成本降低:60%
五、未来发展与学习路径
5.1 技术演进方向
-
多模态Embedding:CLIP架构实现图文跨模态检索
-
动态量化:根据硬件自动选择最优精度
-
联邦Embedding:跨组织安全协同训练
5.2 开发者能力矩阵
Markup
graph LR
A[基础] --> B[掌握Embedding技术]
A --> C[精通Prompt工程]
B --> D[构建检索系统]
C --> E[优化生成质量]
D --> F[工业级部署]
E --> F
掌握Chat与Embedding模型的协同机制,是构建智能系统的关键。


















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











