




前言:
前两天在微信公众号看到,有很多博客在写n8n+大模型创建自己工作流,给工作带来更高效便捷的功能,所以我也在网上看了几篇,想自己在本地部署实现一下。下边就是我这两天研究的成果,本地部署n8n+本地部署deepseek大模型+本地部署ollama,实现的工作流。
在 AI 与自动化融合的趋势下,将可视化工作流工具 n8n 与本地大模型(DeepSeek)、模型管理工具(Ollama)结合,能打造高效、私密的 AI 自动化系统。本文将详细拆解从环境准备到三者联动的完整流程,包含关键配置代码与问题解决方案,适合有基础 Linux 操作经验的开发者参考。
一、部署前的环境准备
1.1 硬件要求(自己电脑虚拟机,有条件可以使用云服务器)
本地部署需满足基础算力需求,避免运行时卡顿或崩溃:
CPU:至少 4 核(推荐 8 核及以上,用于多任务并发)
内存:3GB
硬盘:空闲空间≥50GB(Ollama 及模型缓存占约 20-30GB,n8n 及依赖占 10-15GB)
网络:初始部署需联网下载镜像与模型(后续可离线运行)
1.2 软件依赖
确保系统已安装以下工具(以 Anolis OS release 8.6 为例):
#所需要安装的依赖
yum install -y python3 python3-devel
yum install -y gcc gcc-c++ make
#n8n安装时找不到python地址,需要配置一下
export PYTHON=/usr/bin/python3
echo $PYTHON
二、分步部署核心组件
2.1 用 Ollama 管理 DeepSeek 大模型
Ollama 是轻量级大模型管理工具,支持一键拉取、启动模型,无需复杂环境配置。
步骤 1:安装 Ollama
从官方安装安装包(适用于Linux)
官网下载地址
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
#启动脚本-设置system管理
cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="OLLAMA_MODELS=/data/models/ollama"
Environment="OLLAMA_HOST='0.0.0.0'"
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
[Install]
WantedBy=default.target
#启动模型服务(默认监听127.0.0.1:11434)
systemctl daemon-reload
systemctl start ollama
systemctl enable ollama
验证安装(出现版本号即成功)
ollama --version
步骤 2:拉取并启动 DeepSeek 模型
Ollama 支持 DeepSeek 的多个版本(如 7B、13B),此处以常用的deepseek-r1:1.5b进行测试。
#拉取模型(首次运行需下载约1.1GB文件,耐心等待)
ollama pull deepseek-r1:1.5b
通过curl发送请求,验证模型是否正常响应:
curl -X POST
-H “Content-Type: application/json”
-d ‘{“model”: “deepseek-r1:1.5b”, “prompt”: “你好”}’
http://192.168.0.85:11434/api/generate
若返回包含 Python 代码的 JSON 结果,说明 Ollama 与 DeepSeek 已成功联动。
2.2 部署 n8n 可视化工作流工具(通过npm安装n8n服务)
#node下载地址(node版本使用22版本以上的)
https://nodejs.org/zh-cn/download
ln -s /home/node-v22.4.1-linux-x64/bin/node /usr/bin/node
ln -s /home/node-v22.4.1-linux-x64/bin/npx /usr/bin/npx
ln -s /home/node-v22.4.1-linux-x64/bin/npm /usr/bin/npm
# 1. 设置npm使用国内镜像源(npmmirror,原淘宝npm镜像,已更名为npmmirror)
npm config set registry https://registry.npmmirror.com
# 2. 验证源是否切换成功(输出 https://registry.npmmirror.com 即正确)
npm config get registry
#npm安装n8n
npm install -g n8n
#启动n8n
n8n start
#设置成http访问的,默认需要https访问的
vim ~/.bashrc
export N8N_SECURE_COOKIE=false
source ~/.bashrc
n8n stop && n8n start
#访问方式
打开浏览器,输入http://localhost:5678,首次访问需设置管理员账号(邮箱 + 密码)。登录后即可看到 n8n 的可视化工作流编辑器,界面如下:
•左侧:节点库(包含 HTTP、AI、数据库等 200 + 节点)
•中间:工作流画布(拖拽节点构建流程)
•右侧:节点配置面板(设置参数、认证等)
三、关键配置:n8n 联动 Ollama+DeepSeek
n8n 本身不直接支持 Ollama,但可通过「HTTP 请求节点」调用 Ollama 的 API,间接实现与 DeepSeek 的联动。
3.1 创建 python脚本
#安装python依赖
pip install fastapi uvicorn requests pydantic
#python脚本实现功能介绍
搭建一个中间层 API 服务(使用 FastAPI),提供带 API Key 认证的接口
该中间层转发请求到本地 DeepSeek 模型(如通过 Ollama 部署的模型)
在 n8n 中配置这个中间层 API 的地址和密钥
3.2 python脚本内容
from fastapi import FastAPI, HTTPException, Depends
from fastapi.security import APIKeyHeader
import requests
from pydantic import BaseModel
import uvicorn
# 配置
API_KEY = "n8n-deepseek-@uth-789" # 自定义你的本地API密钥
OLLAMA_URL = "http://192.168.0.85:11434/api/generate" # Ollama的API地址
API_KEY_NAME = "X-API-Key" # 请求头中API密钥的名称
app = FastAPI(title="Local DeepSeek API with Auth")
# API密钥验证
api_key_header = APIKeyHeader(name=API_KEY_NAME, auto_error=False)
async def get_api_key(api_key: str = Depends(api_key_header)):
if api_key == API_KEY:
return api_key
else:
raise HTTPException(
status_code=403,
detail="Invalid or missing API Key"
)
# 请求模型
class QueryRequest(BaseModel):
prompt: str
model: str = "deepseek-r1:1.5b" # 默认使用的DeepSeek模型
stream: bool = False
# 响应模型
class QueryResponse(BaseModel):
response: str
# 推理接口
@app.post("/api/chat", response_model=QueryResponse)
async def chat(request: QueryRequest, api_key: str = Depends(get_api_key)):
try:
# 转发请求到Ollama
ollama_response = requests.post(
OLLAMA_URL,
json={
"model": request.model,
"prompt": request.prompt,
"stream": request.stream
}
)
if ollama_response.status_code != 200:
raise HTTPException(
status_code=ollama_response.status_code,
detail=f"Error from Ollama: {ollama_response.text}"
)
# 处理响应
result = ollama_response.json()
return {"response": result.get("response", "")}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
# 启动服务,默认端口8000
uvicorn.run("deepseek_api:app", host="0.0.0.0", port=8000, reload=True)
四、n8n配置本地部署大模型以及输出内容
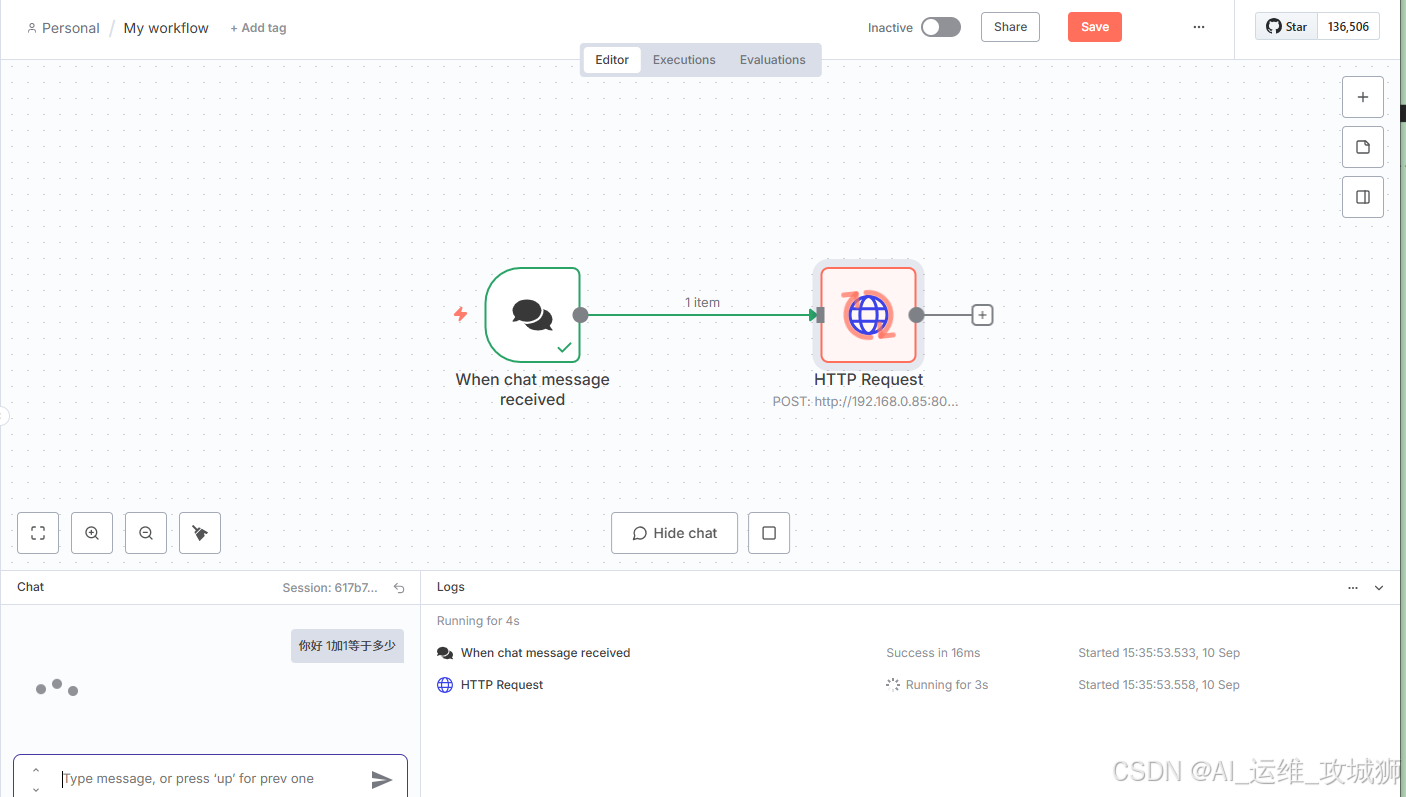
新建工作流—添加输入消息模块
点击加号添加HTTP Request模块
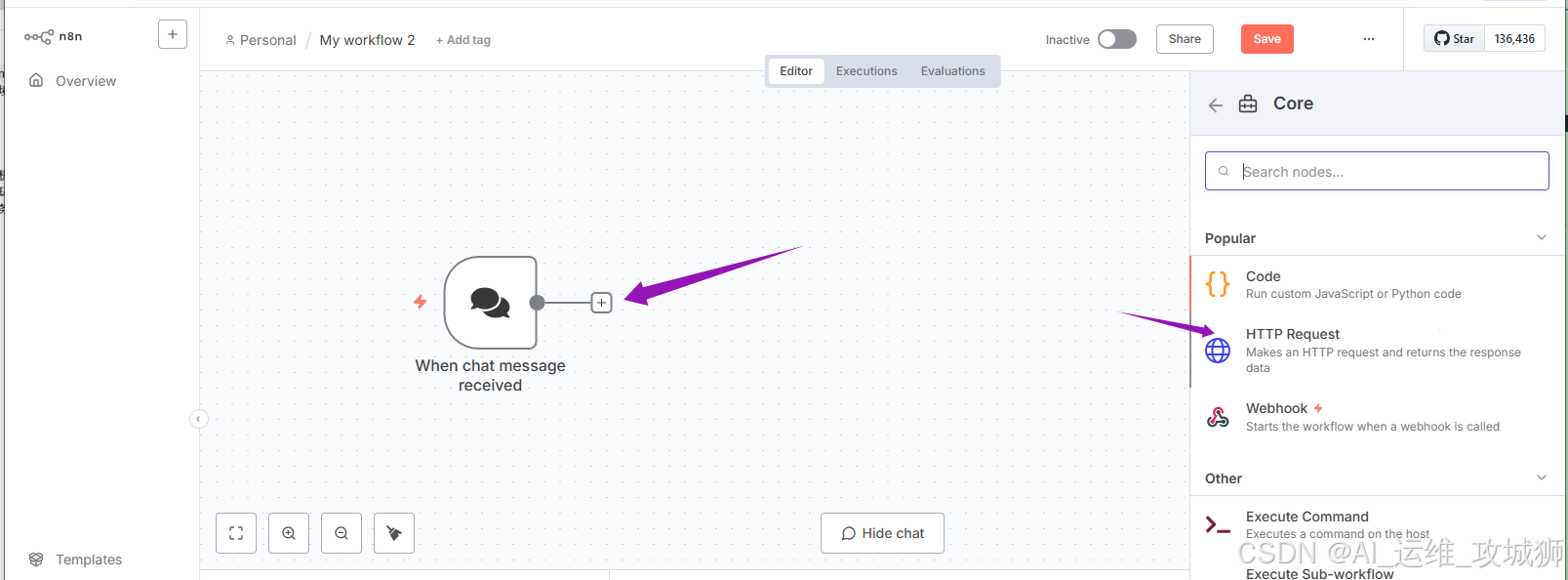
配置HTTP Request模块
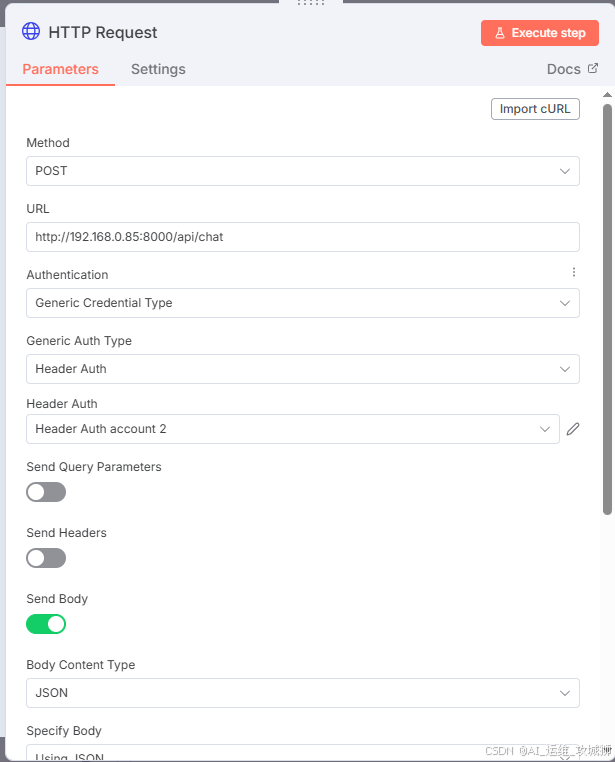
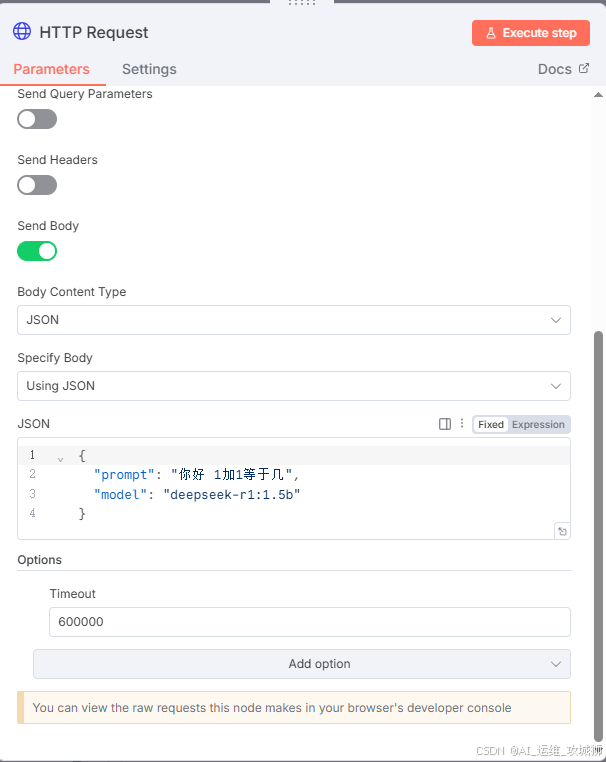
接下来可以进行询问是否正常
点击 Execute step,等待大模型回复是否正常使用
#思考过程
#结果
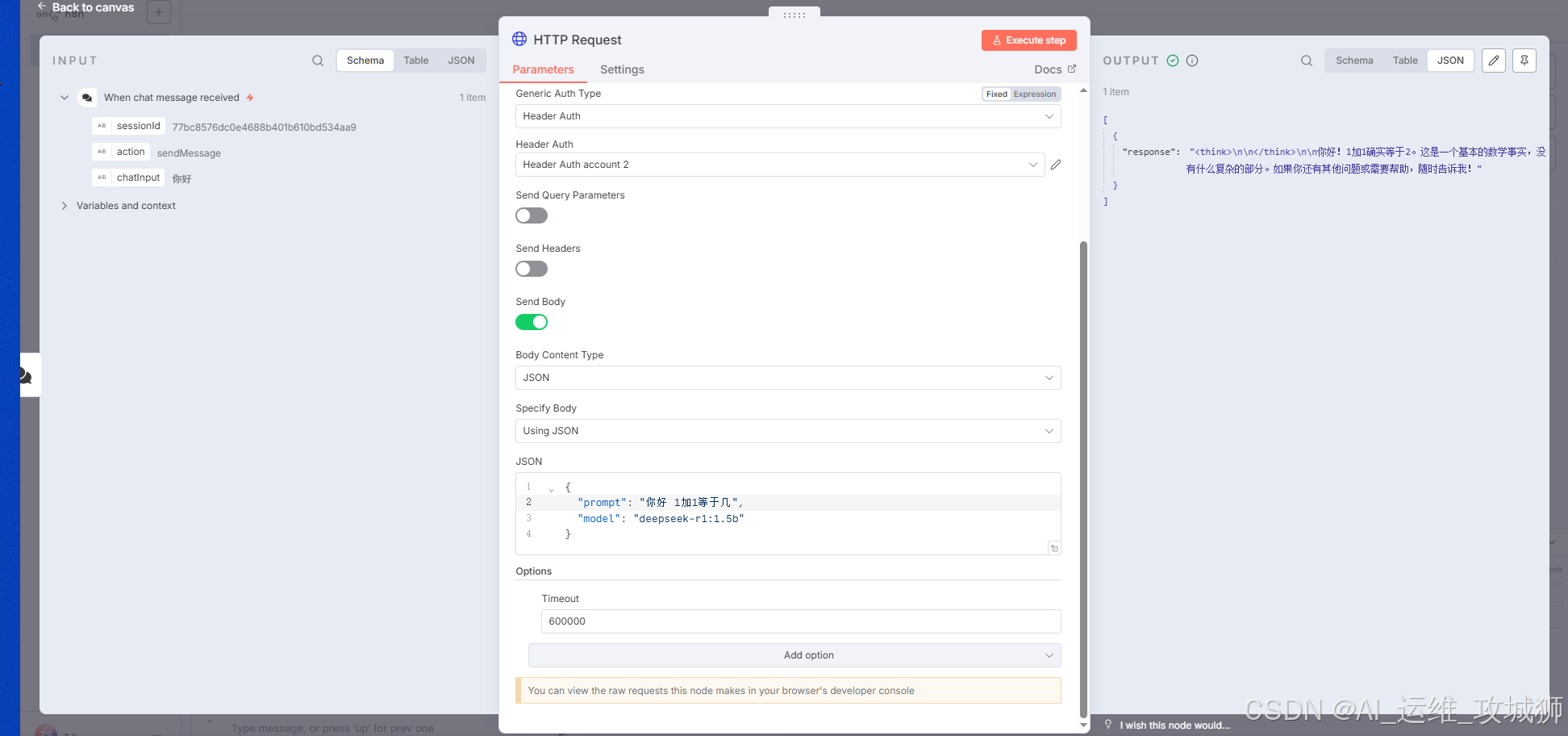
到现在是一个流程,实现了所有都部署在本地,而且可以训练自己的大模型。可以代替自己的公司的线上客服进行使用。
结语
本文完成了 n8n、Ollama、DeepSeek 的本地联动部署,核心优势在于:
- 私密性:所有数据存储在本地,避免敏感信息上传云端。
- 灵活性:通过 n8n 的可视化界面,无需编写大量代码即可调整工作流。
- 轻量级:Ollama 简化了模型管理。
后续可探索的扩展方向:
1.模型切换:在 Ollama 中拉取其他模型(如 Llama 3、Qwen),在 n8n 的 HTTP 请求中修改model参数即可切换。
2.GPU 加速:若本地有 NVIDIA 显卡,可安装 NVIDIA Docker Runtime,让 Ollama 使用 GPU 运行模型(需额外配置,参考Ollama 官方文档)。
3.前端界面:用 React、Vue 等框架开发简易前端,通过调用 n8n 的 Webhook,让非技术人员也能使用 AI 功能。
若在部署过程中遇到其他问题,可参考各工具的官方文档: - n8n 官方文档
- Ollama 官方文档


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









