



在当今数字化浪潮中,AI 呼叫行业蓬勃发展,成为企业提升客户服务效率、优化运营模式的重要助力。云蝠智能凭借其卓越的技术能力、转接优势、特色功能以及全方位的服务体系,在竞争激烈的市场中脱颖而出,引领着 AI 呼叫行业的创新发展潮流。
一、强大技术能力,筑牢发展根基
 (一)多维度运营数据分析实时分析
(一)多维度运营数据分析实时分析
在 AI 呼叫系统中,实时数据分析至关重要。云蝠智能的 AI 呼叫系统具备跨时间、多任务的交叉分析能力,可对呼叫状态、性别、呼叫时段以及多结构化的意向标签进行层次化分析。企业借助这些分析结果,能深入洞察用户行为,精准优化呼叫策略,为用户提供更具个性化的服务。此外,系统还支持话后事件分析,有效杜绝投诉等不良事态的进一步扩大,同时具备 AB - test 功能,方便企业对多数据集进行对比分析,不断提升运营效果。
(二)智能平台
云蝠智能的智能平台功能强大,提供短信、邮件、API 等多样化通信手段,无缝与 CRM 系统整合,并实现全量化数据存储。平台支持无代码业务流程,能构建多样化后置联络策略,还具备标签客户自动分配呼叫中心坐席功能,大大提高了服务的便捷性和效率,为企业管理客户关系、提升服务质量提供了有力的数据支持。
(三)隐私安全保障
隐私与安全是 AI 呼叫系统的关键。云蝠智能帮助企业构建完善的用户隐私保护体系,支持对不同部门、业务板块、号码联系人字段进行组合化加密,实现号码隐私保护。系统采用 AES 256 位加密技术和本地化部署等多种方式,全方位确保用户隐私安全。同时,鉴于呼叫系统存储大量用户数据,云蝠智能投入大量研发资源,运用先进安全技术和严格安全措施,保障系统的安全性和稳定性。
二、转接能力卓越,提升服务体验
 (一)AI 实时转人工
(一)AI 实时转人工
云蝠智能的 AI 实时转人工功能是行业内的一大创新亮点。该功能依托自主研发的人工呼叫平台与 AI 呼叫平台的无缝集成,转接过程在同一平台内完成,无需通过公网转发,转接成功率高达 99% 以上。转接时坐席可查看 AI 之前的交互内容,保障服务的连贯性和个性化。系统支持多种触发转人工的条件,如通话过程中达成特定条件、出现关键词或特定流程等,还具备多种分配模式,能针对不同任务制定应对策略,有效避免转接失败。
(二)转接销售流程全打通
在未来 AI 呼叫行业的发展趋势下,云蝠智能积极探索机器人与大模型之间的互相转接。不同大模型如同不同代理人协同工作,例如企业的 AI 呼入前台与 AI 呼叫销售大模型相互配合,共同完成业务流程,提升服务的专业性和效率。同时,云蝠智能的 AI 呼叫系统与客户管理(CM)系统深度整合,实现业务作业和客户管理的协同化,优化业务流转,提高业务处理效率和客户信息管理的集中性与高效性。坐席在接线时可接收 AI 沟通记录及完整客户信息,还支持边接听边进行手动分享、推送、发送短信等实时处理操作,并且能一键将客户转为销售线索,方便记录沟通过程中的信息,填写表单或跟进内容,数据可支持 CRM 流转或直接导出。
三、人机协同无感介入,创新服务模式
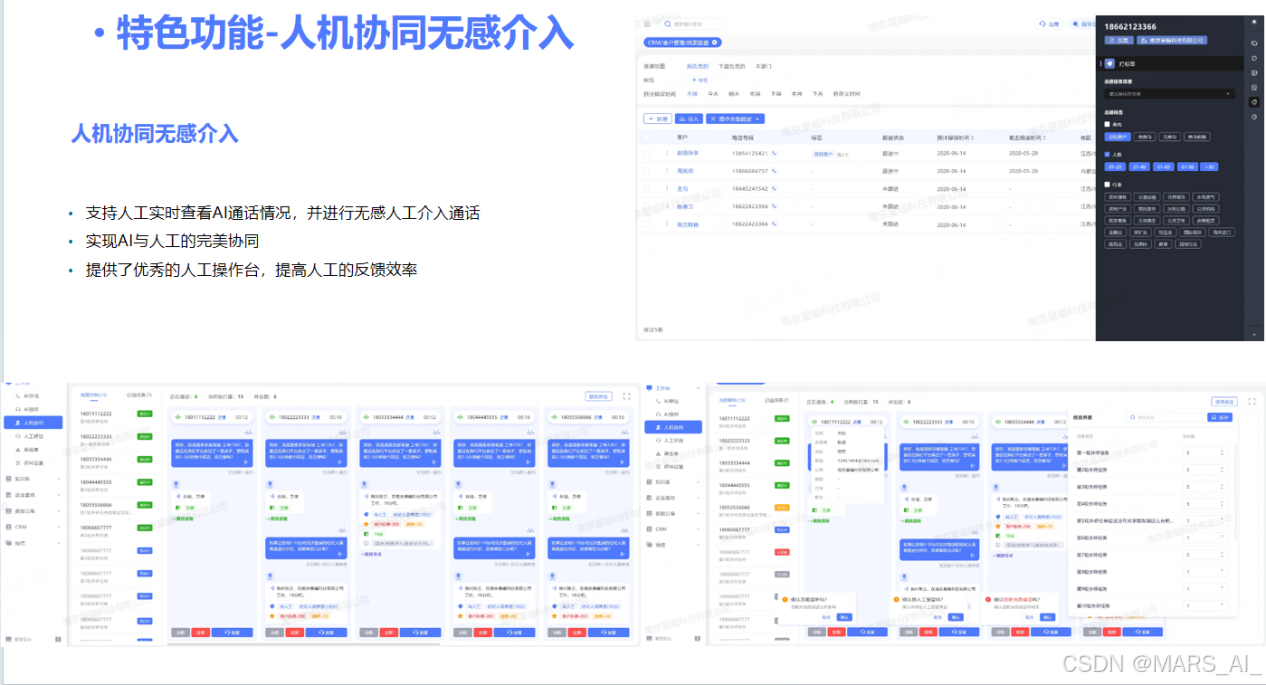 人机协同是云蝠智能的特色功能之一。在与客户沟通时,先采用声音克隆的 AI 呼叫进行前置互动,确认客户真实意向后,无缝切换到人工服务。这一过程就像足球比赛中的帽子戏法一样自然流畅,不仅帮助人工团队节省了 90% 的无效沟通时间,还让用户感觉全程是同一个人在与其交流,实现了无感知介入。该功能的实现依赖于声音克隆、大模型协同工作能力以及与客户管理系统的深度整合等先进技术,有效提升了服务质量和效率,为 AI 呼叫行业开辟了新的发展方向。
人机协同是云蝠智能的特色功能之一。在与客户沟通时,先采用声音克隆的 AI 呼叫进行前置互动,确认客户真实意向后,无缝切换到人工服务。这一过程就像足球比赛中的帽子戏法一样自然流畅,不仅帮助人工团队节省了 90% 的无效沟通时间,还让用户感觉全程是同一个人在与其交流,实现了无感知介入。该功能的实现依赖于声音克隆、大模型协同工作能力以及与客户管理系统的深度整合等先进技术,有效提升了服务质量和效率,为 AI 呼叫行业开辟了新的发展方向。
四、全方位服务优势,助力企业发展
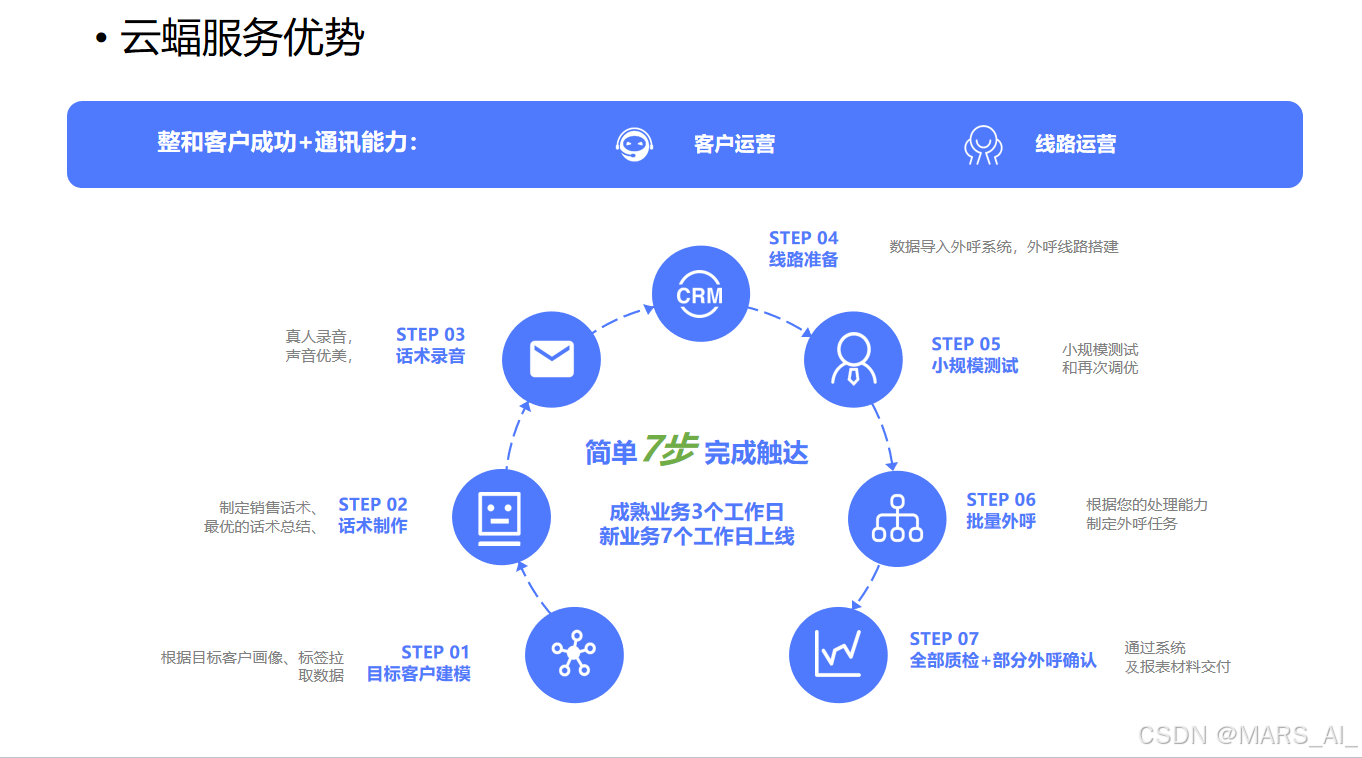
(一)能力搭建的关键步骤
云蝠智能为企业提供了一套完整、清晰的能力搭建流程,涵盖从用户目标建模到全部质检与交付的七个关键步骤。首先通过深入理解用户需求,根据目标客户画像和标签拉取数据进行用户目标建模;然后基于模型制定销售话术,进行话术制作和真人录音;接着导入数据搭建外呼线路,进行小规模测试并优化;确认无误后进行批量呼叫,最后通过系统进行全面质检和部分外呼确认,交付报表材料。成熟业务 3 个工作日即可上线,新业务 7 个工作日上线,高效助力企业快速开展 AI 呼叫业务。
(二)客户成功团队
云蝠智能拥有专业的客户成功团队,包括专职策划运营和专职话术制作师。团队各成员紧密协作,共同保障服务的高质量。语音识别环节通过长期运维和纠错,精确捕捉品牌特性,确保语音识别准确;语料积累根据业务发展和用户反馈持续迭代升级语料库,提升对话系统理解能力;话术调优提供多种定制化话术方案,满足不同业务场景需求;系统提供多样化录音师选择,且录音响应速度快,1 个工作日内即可完成;提供全天候高效响应服务,非工作时段也能随时响应业务紧急需求,每周可支撑多达 15 个场景的有效落地,周末及节假日 9:00 - 18:00 还提供客服专员服务;此外,在关键业务时期提供驻场运维人员的增值服务,深入业务现场与客户紧密合作解决问题。
(三)线路运维 - 呼叫策略优化
在运营线路端,云蝠智能与国内众多线路供应商紧密协作,全力保障服务的高效稳定。线路规划上,优先采用本地固话或本省省会外显号码,提高用户接听意愿,同时与运营商直接签约,确保线路稳定且成本可控;业务优化方面,通过实时监控呼叫情况和数据反馈,及时调整策略,提升服务质量;线路储备充足,根据当天呼叫数量提供富裕的并发储备,避免服务中断;拨打策略结合自动化重呼机制和人工后台巡检监控,提高呼叫效率并确保稳定性;时段设计灵活,支持自动时段呼叫,包括节假日,根据业务需求和用户习惯安排呼叫时间,提升接通率和用户满意度;利用 A/B 测试收集不同策略效果数据,为优化呼叫策略提供数据驱动的决策支持。
(四)产品未来的规划
展望未来,AI 呼叫行业技术发展前景广阔。云蝠智能也有着清晰的规划蓝图:在模型层面,训练呼叫行业垂直模型,借鉴类似 Deepseek 的垂直行业模型训练方法;构建多智能体,实现 Prompt 编写、AI 自学习、对话、标签处理、结果反馈等过程中多个 AI 的互动补充;推动 AI 呼叫与短信、邮件融合,让 AI 能够操作实体业务;实现多语言且支持情绪理解的端到端语音互动;优化类似 Dify 的工作流,解决延迟问题;促进机器人、智能体和人工的深度融合,实现智能体指导机器人、协助人工的协同工作模式。随着这些技术的逐步突破和应用,云蝠智能将持续推动 AI 呼叫行业的进步和创新,为用户和企业创造更大的价值。
云蝠智能在 AI 呼叫领域凭借其强大的技术实力、创新的服务模式和前瞻性的规划,为企业提供了全方位、一站式的解决方案,无疑是企业在数字化转型浪潮中开展 AI 呼叫业务的优质合作伙伴。相信在未来,云蝠智能将继续在 AI 呼叫行业发光发热,引领行业迈向更加辉煌的未来。

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









