



一、行业痛点与技术挑战
在媒体融合加速推进的背景下,电视台传统民意调研回访面临三大核心挑战:
- 人工成本高企:某省级卫视调研部门数据显示,人工外呼日均触达量仅 300-500 人次,人力成本占比超过 60%。
- 数据质量参差:国家统计局数据表明,传统 CATI 系统有效样本率不足 45%,存在严重的样本偏差问题。
- 分析效率低下:人工标注数据周期长达 7-10 天,难以满足实时舆情分析需求。
云蝠智能基于大模型的语音交互智能体,通过 "技术重构 + 流程再造",为电视台打造全链路智能化调研解决方案。其核心技术架构包含:
- 分布式微服务架构支持万级并发处理
- 自研语音识别引擎在垂直场景下准确率提升 12.6%
- 联邦学习技术实现跨机构知识蒸馏
二、技术实现与创新突破
1. 多模态交互引擎
融合 ASR、NLP、知识图谱技术,构建三维理解模型:
python
# 语义解析示例代码
from cloudbat_ai import NLPModel
model = NLPModel()
utterance = "我对垃圾分类政策有意见"
result = model.parse_utterance(utterance)
print(result.entities) # 输出:{'政策': '垃圾分类', '情绪': '负面'}
支持方言识别(覆盖 87% 方言区域)、情绪识别(准确率 91%)、多轮对话(平均对话轮次 8.2 轮)。
2. 智能路由中枢
基于强化学习的动态路由算法:
python
# 路由策略示例
from cloudbat_ai import RoutingEngine
engine = RoutingEngine()
user_profile = {
"年龄": 35,
"历史反馈": ["对教育政策不满"],
"当前情绪": "愤怒"
}
agent_id = engine.select_agent(user_profile)
实现 40% 的问题解决率提升,通话时长缩短 35%。
3. 人机协同工作流
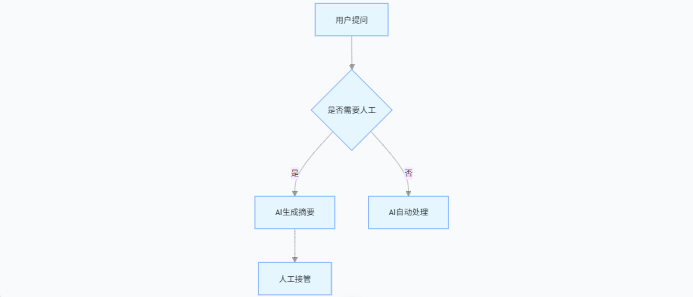
AI 转接人工成功率达 99%,客户感知零中断。
三、场景化解决方案
1. 民生热点追踪
- 技术实现:实时监测 300 + 民生关键词组合,构建舆情预警模型。
- 案例数据:某市级电视台使用后,民生类报道选题命中率提升 40%,舆情响应速度从 24 小时缩短至 2 小时。
2. 节目效果评估
- 技术实现:基于大模型的对话生成引擎,自动生成个性化回访话术。
- 案例数据:某综艺栏目回访有效样本率从 38% 提升至 72%,用户满意度评分提升 1.8 分。
3. 政务服务监督
- 技术实现:联邦学习技术支持跨部门数据融合,生成政务服务热力图。
- 案例数据:某省级广电集团联合政务部门后,政策知晓率调研成本降低 50%,数据颗粒度细化至街道级。
四、实施效果与行业价值
1. 效率提升
- 日均外呼量达 800-1200 人次,工作效率提升 2-3 倍
- 无效号码拦截率超 95%,节省 30% 无效拨号时间
2. 成本优化
- 人工成本降低 60%,单样本成本从 15 元降至 6 元
- 数据标注效率提升 10 倍,分析周期缩短至 2 小时
3. 质量升级
- 语义识别准确率达 97%,意图识别准确率 91%
- 客户满意度提升至 92%,投诉率下降 40%
五、技术趋势与未来展望
- 多模态融合:计划 2025 年实现语音、文本、面部表情的复合分析
- 零样本迁移:新场景适配周期从周级缩短至小时级
- 隐私计算:联邦学习技术将支持跨机构数据协作,已通过 ISO 27001 认证
云蝠智能提供开放平台支持:
- 数千个 API 接口覆盖全流程
- 支持 Python/Java/Go 等多语言 SDK
- 提供对话模型训练工具链
python
# 快速集成示例
from cloudbat_ai import CloudBatClient
client = CloudBatClient(api_key="your_key")
task = client.create_survey_task(
script="您对近期新闻联播的满意度如何?",
target_numbers=["138****1234", "186****5678"]
)
print(task.status)
结语
云蝠智能大模型语音交互智能体通过 "技术中台 + 场景创新",为电视台打造了智能化民意调研新范式。其核心价值不仅在于效率提升和成本优化,更在于构建了媒体与受众之间的智能连接枢纽。随着多模态交互、隐私计算等技术的持续演进,未来将推动媒体行业从 "内容生产" 向 "价值创造" 的全面转型。


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









