




这章节主要介绍了单元设计在预布局阶段(pre-layout)的延时计算以及在完成布局之后(post-layout)的时序验证。之前的几章节都关注于互联的建模以及单元库。我们将会利用单元以及互连建模的有关技术去获得设计的时序。
目录
5.1 综述
5.1.1 基础延时计算
一个典型的设计包含了许多的组合、时序单元。我们使用下图的逻辑框架去描述延时计算的概念。
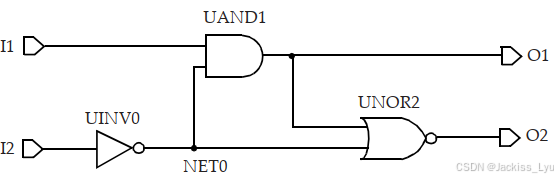
库对于单元的描述指定了单元每个引脚的电容值。因此设计中的每个网络都有容性负载,大小为所有扇出的引脚的电容之和加上互连电容(如果有的话)。出于简洁而言,我们这章节就不考虑互连电容了。对于上图而言,网络NET0的电容就在于NET0与UAND1连接的引脚的电容+NET0与UNOR2连接的引脚的电容之和。输出引脚O1的负载是单元UNOR2加上所有输出逻辑块的电容负载。输入引脚I1和I2的引脚电容分别对应于UAND1和UINV0单元。可以抽象成下图。(简单来看就是这个单元的输出 连接了谁的输入引脚)
就像在第三章中描述的一样,对于多种时序弧,单元库包含了NLDM模型可供使用。这个非线性模型,用一个二维的表格的形式进行描述,两个索引分别为输入过渡时间以及输出电容。单元的输出过渡时间也用一个二维的表格描述,两个索引分别为输入过渡时间和总的输出电容。因此,如果在逻辑模块的输入引脚,输入过渡时间被指定,这时,输出过渡时间以及UINV0-UAND1的时序弧的延时就可以从单元库的描述得出。其他时序弧的时序参数也可以用相同的方法得出。对于一个多输入的单元,不同的输入引脚可以使得输出引脚有不同的过渡时间。对于不同的输出过渡时间的选择,将在5.4节中描述。
5.1.2 延时的计算(包含互连)
预布局的时序
在第四章中描述了,在预布局的时序验证阶段,使用线负载模型对互连参数进行了估计。在多数情况下,电阻对于线负载模型的影响被设为0.这种情况下,线负载模型的影响全部由电容贡献,且对于设计中所有的时序弧前面部分所描述的时延计算方法同样适用。
布线后的时序
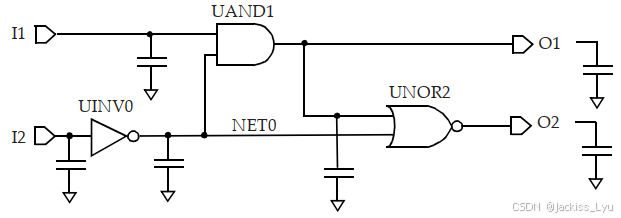
金属走线的寄生参数,映射成一个在驱动和扇出单元之间的网络。上面的图片为例子,网络的互连电阻如下图所示。内部网络如NET0,映射到了多个子节点,因此UINV0的输出负载由RC结构组成。因为NLDM表是和输出电容和输入过渡时间组成的,输出引脚的电阻负载暗示了,NLDM的表不能直接适用(因为出现了电阻,而不是仅有电容存在)。接下来介绍如何将NLDM表格模型和互联电阻结合使用。
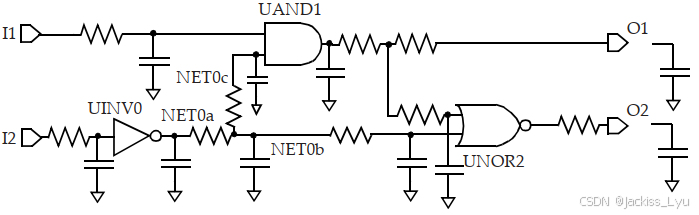
5.2 使用有效电容计算单元延时
为了解决上面“存在电阻而不能直接应用模型的问题”。
有效电容方法,试图通过单一电容,等效其他的负载。所以,在这种情况下,无论是原设计还是现在有了等效电容的设计,都在输出引脚有相似时序。这个等效的单一电容称为有效电容。
下图a展示了一个单元在它的扇出有RC互连网络。在b图中用等效RC π网络进行表示,在c图中就很好说明了等效电容的存在意义。它与原设计具有相同的延时,只不过用一个电容概括了之前的所有电容和电阻。总的来说,具有RC负载的输出单元,相比于只有有效电容的单元,输出波形有很大的不同。
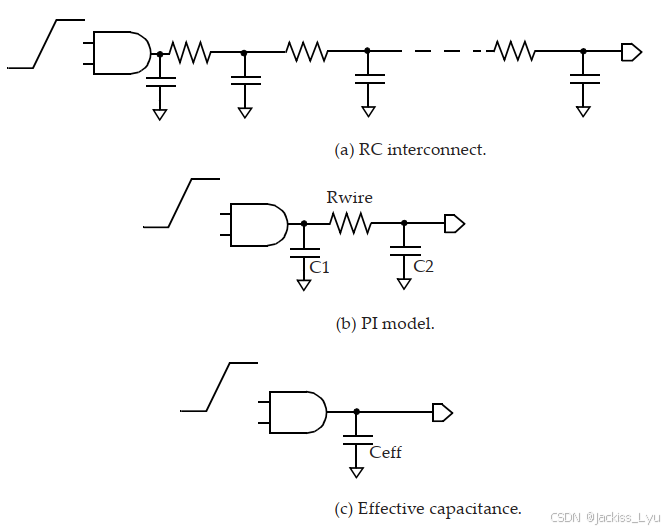
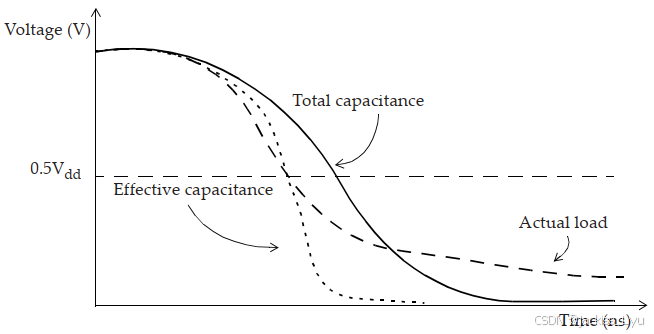
在下图中,展现了三种不同的电容形式下(总电容、有效电容、真实RC),输出波形的不同。可以推断知道,选择具有恰当值的有效电容值,可以使上图中ac两种情况的延时相同。
可以使用上面的公式,配合π型网络,计算等效电容值。
在公式里,C1就是距离输出引脚更近(near-end)的电容,C2就是距离输出引脚更远(far-end)的电容。k的值在0-1之间。在互连电阻的影响可以忽略不计这种情况下,有效电容的大小几乎与总电容的大小相等。如果我们试着把b图中的电阻设为0,那就完全解释的通了。相似的,如果互连电阻相对较大,此时大到视为断路了,那么等效电容就是C1,也就是离得近的那个电容。所以在有限电阻值的情况下,可以取k为0-1的一个值。
有效电容是他俩的函数:
- 驱动单元
- 负载的特征(load characteristics),尤其是驱动单元负载的输入阻抗(input impedance)
对于给定的互连,如果一个单元的输出驱动能力较弱,那么他所看到的有效电容将会更大。如果一个单元的输出驱动能力较强,那么他所看到的有效电容将会更小。因此,有效电容的大小将会介于C1或是总电容之间。接近C1的时候,电阻较大或者单元的驱动能力较强;接近总电容的时候,此时电阻的值较小或者单元的驱动能力较弱。目标引脚的转换时间比驱动单元的输出时间要晚,近端电容(near-end)充电速度快于远端电容(far-end),是电阻对于互连的屏蔽作用(resistive shielding effect),因为驱动单元只能看到远端电容的一部分。
如何理解驱动能力与Ceff的大小关系?
如果没有互连负载,输出引脚也存在着本征电容,可以联想一下反相器链的延时计算。
驱动能力较大,电流较大,尺寸较大,所以本征电容较大,相比之下看到的有效电容就小。
驱动能力较小,电流较小,尺寸较小,所以本征电容较小,相比之下看到的有效电容就大。
我们通过一个迭代的过程(iterative procedure)来获得有效电容。就算法而言,第一步是获取单元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









