






 本文介绍AlexNet相关内容,其目的是对ImageNet竞赛中的高分辨率图像分类并提升大型神经网络能力。提出了最大CNN模型、GPU实现等方法,采用ReLU、多GPU训练等架构,还通过数据增强和Dropout减少过拟合,虽有优势但架构仍待优化。
本文介绍AlexNet相关内容,其目的是对ImageNet竞赛中的高分辨率图像分类并提升大型神经网络能力。提出了最大CNN模型、GPU实现等方法,采用ReLU、多GPU训练等架构,还通过数据增强和Dropout减少过拟合,虽有优势但架构仍待优化。
作者: Alex Krizhevsky
日期: 2012.1.1
类型: article
来源: NIPS
评价:AlexNet, deeplearning breakthrough
论文链接:
1 Purpose
- The competition: To classify the 1.2million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes.
- To improve the capability of large neural networks.
Challenges
- The realistic object recognition task need large dataset: Compare with MNIST digit-recognition task, Objects in realistic settings exhibits considerable variability. Small datasets are not enough.
- Need prior knowledge: The immense complexity of the object recognition task means that this problem cannot be specified even by a dataset as large as ImageNet, so our model should also have lots of prior knowledge to compensate for all the data we don’t have.
- CNN is not enough: Despite the relative efficiency of their local architecture, they have still been prohibitively(过高的) expensive to apply in large scale to high-resolution images.
2 The previous work
- Best performance reported before on ImageNet 2010: [High-dimensional signature compression for large-scale image classification.]
- Best performance published on ImageNet 2009: T. Mensink et al. Metric Learning for Large Scale Image Classification: Generalizing to New Classes at Near-Zero Cost. ECCV. 2012
3 The proposed method
- largest cnn model: They trained one of the larges convolutional neural networks to date on the subsets of ImageNet used in the ILSVRC-2010 and ILSVRC-2012 competitions, and achieved by far the best results ever reported on these datasets.
- GPU implementation: They wrote a highly-optimized GPU implementation of 2D convolution and all the other operations inherent in training the convolutional neural networks.
- Tricks: Their network contains a number of new features which improve the performance and reduce the training time.
- Deal with overfitting: Use several effective techniques for preventing overfitting.
- An important architecture: removing any convolutional layer would lead to inferior performance.
3.1 Data sets
- ILSVRC2010(ImageNet Large Scale Visual Recognition Challenge: with roughly 1000 images in each of 1000 categories. In all, roughly 1.2million images, 50,000 validition images, and 150,000 testing images.
- ILSVRC2012: the author just validate on the data set, because the test set labels are not availabel.
3.2 The architecture
-
ReLU
non-saturating nonlinearity f ( x ) = m a x ( 0 , x ) f(x)= max(0,x) f(x)=max(0,x) is much faster than those saturating nonlinearity like sigmoid, tanh;
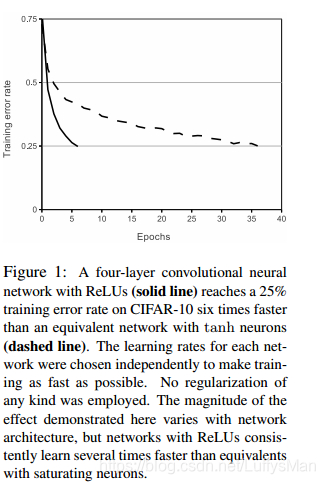
-
Taining on Multiple GPUs
- Due to the huge amount of parameters, one GPU’s memory is not enough. They spread the net across two GPUs.
- Current GPUs are paticularly well-sutied to cross-GPU paralleization, as they are able to read from and write to one another’s memory directly, without going through host machine memory.
-
Local Response Normalization
- This sort of response normalization implements a form of lateral inhibition(侧抑制) inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels.
- It proved to work, reduces their top-1 and top-5 error by 1.4% and 1.2%.
-
Overlapping Pooling
- Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap. But the author set the stride = 2 and kernel size = 3, make it overlapping pooling.
- They observe during training that models with overlapping pooling, find it slightly more difficult to overfit.
-
Overall architecture
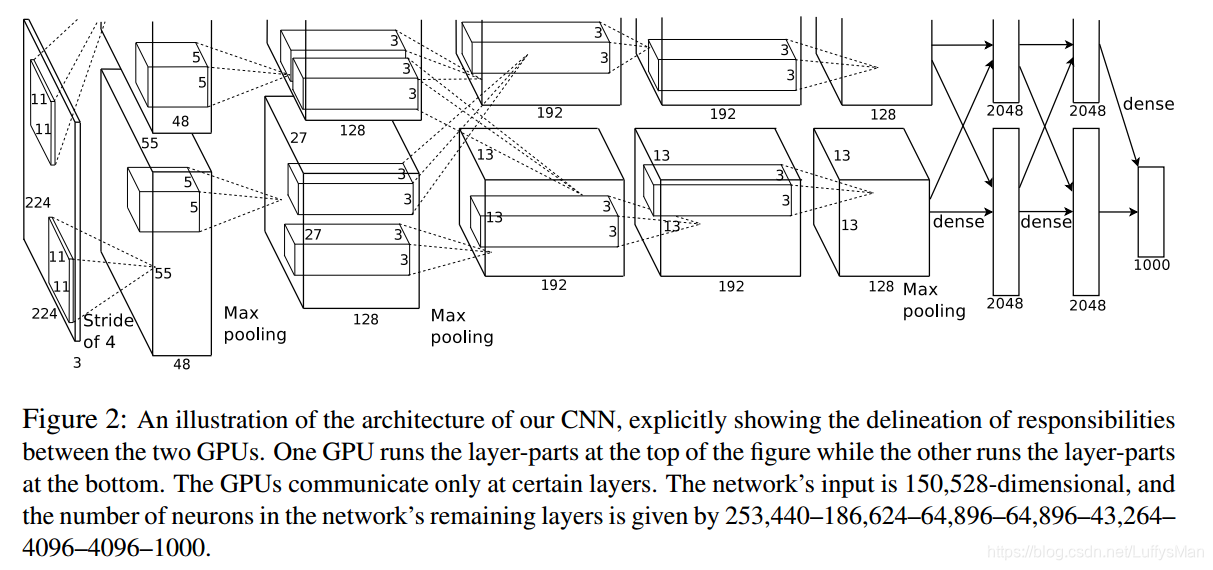
- layers: 8 layers, with 5 convolutional layers and 3 fully connected layers;
- objective: multinomial logistic regression
- local response normalization: LRN follow the first and the second convolutional layers;
- Overlapping pooling: follow both response-normalization layers of 1,2, and the 5th layer;
- GPU communication: GPU communicate only at certain layers, which are the 3rd convolutional layer and the first two fulliy convolutional layers;
3.3 Reducing Overfitting
- Data Augmentation: two different methods
- They generating image translations and horizontal reflections, and then extract 224x224 patches from 256x256 images. Tremendously enlarge the data set by a factor of 2048. They use a simialar but much simple form when testing.
- The secong form of data augmentation consists of altering the intensities of the RGB channels in training images.The author think that it captures an important property of natural images, that object identity is invariant to channels in the intesity and clolor of the illumination.
- Dropout
- like assembly learning: According to the author, dropout can obtain an effect that like combine many different models
- more robust: It can force the model to learn more robust features that are useful in conjuntion with many different random subsets of the other neurons.
- Supress overfitting: They use dropout in the first two fully-connected layers. Without dropout, their network exihbits substantial overfitting.
- double the iterations to converge: In their experiment, dropout roughly doubles the iterations to converge.
3.4 Results
| Model | Top-1 | Top-5 |
|---|---|---|
| Sparse coding | 47.1% | 28.2% |
| SIFT + FVS | 45.7% | 25.7% |
| CNN | 37.5% | 17.0% |
Table 1: Comparison of results on ILSVRC-2010 test set. In italics are best results achieved by others
| Model | Top-1(val) | Top-5(val) | Top-5(test) |
|---|---|---|---|
| SIFT + FVs [7] | – | – | 26.2% |
| 1 CNN | 40.7% | 18.2% | - |
| 5 CNNs | 38.1% | 16.4% | 16.4% |
| 1 CNN* | 39.0% | 16.6% | – |
| 7 CNNs* | 36.7% | 15.4% | 15.3% |
Table 2: Comparison of error rates on ILSVRC-2012 validation and test sets. In italics are best results achieved by others. Models with an asterisk* were “pre-trained” to classify the entire ImageNet 2011 Fall release. See Section 6 for details.
- They author found that emprically the result of vailidation error and test error do not differ by more than 0.1%.
Are the data sets sufficient?
Yes
3.6 Advantages
- Surpass all the other practice by a large distance. Nearly halve the Top-5 error rate in ILSVRC 2010.
- A simple model which can perform better provided faster GPUs and lager data sets.
3.7 Weakness
- The architecture is not optimal, it still has many aspects to improve. The later works proved this.
4 What is the author’s next step?
They said they would like to use very large and deep convolutional nets on vidio sequences where the temporal structure provides very helpful information that is missing or far less obvious in static images.
4.1 Do you agree with the author about the next step?
Yes.
5 What do other researchers say about his work?
- Karen Simonyan et al. VERY DEEP CONVOLUTIONAL NETWORKS
FOR LARGE-SCALE IMAGE RECOGNITION. ICLR, 2015.(VGG)
With ConvNets becoming more of a commodity in the computer vision field, a number of attempts have been made to improve the original architecture of Krizhevsky et al. (2012) in a bid to achieve better accuracy. - Christian Szegedy et al. Going Deeper with Convolutions. CVPR, 2015. (GoogLeNet)
Our GoogLeNet submission to ILSVRC 2014 actually uses 12 times fewer parameters than the winning architecture of Krizhevsky et al [9] from two years ago, while being significantly more accurate. - Kaiming He et al. Deep Residual Learning for Image Recognition. CVPR, 2015.(ResNet)
Deep convolutional neural networks [22, 21] have led to a series of breakthroughs for image classification.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









