






 本文介绍了一种大型深度卷积神经网络在ImageNet数据集上的应用,通过使用GPU加速的2D卷积,实现了大规模图像识别的最佳性能。网络包含5个卷积层和3个全连接层,通过数据增强和dropout技术有效防止过拟合。
本文介绍了一种大型深度卷积神经网络在ImageNet数据集上的应用,通过使用GPU加速的2D卷积,实现了大规模图像识别的最佳性能。网络包含5个卷积层和3个全连接层,通过数据增强和dropout技术有效防止过拟合。
1、Introduction
当前的对象识别方法中,必不可少的的属机器学习了,而以前万级别的图像数据库已经做得很好了,现在百万级的数据的数据库产生,例如LabelMe, ImageNet。所以开始这数百万级的对象识别研究。
However, the immense complexity of the object recognition task means that this problem cannot be specified even by a dataset as large as ImageNet, so our model should also have lots of prior knowledge to compensate for all the data we don’t have. (然而,对象识别任务巨大的复杂度意味着这个问题不能由数据来特殊化,即使数据量大如ImageNet这样也不行吗,因此要求我们的模型有大量的先决知识来弥补未知数据的缺陷。)
对比其他的方法,CNN的连接少而易训练,效果也很好。不过对于这么大规模的高分辨率图像,CNN也很难做。不过现在的GPUs 配上很高优化的2D卷积,能实现如此大规模的CNN。
本文所做的:1、我们用ILSVRC-2010和ILSVRC-2012竞赛使用的ImageNet的子集训练了一个最大的卷积神经网络,并且达到了这些数据集已知的最好效果。2、我们写了一个优化很高的2D卷积GPU实现,以及公开的其他所有训练卷积神经网路的固定操作。3、我们的神经网络包含大量的不常见的新特征,可以提高网络的性能并减少训练时间,详细见第三部分。4、我们神经网络的大小会造成过拟合是一个很重要的问题,即使我们有一百二十万训练的标记图像。因此我们使用了几种有效的防止过拟合的方法,将在第4部分详细展开。
The specific contributions of this paper are as follows:
- we trained one of the largest convolutional neural networks to date on the subsets of ImageNet used in the ILSVRC-2010 and ILSVRC-2012 competitions and achieved by far the best results ever reported on these datasets.
- We wrote a highly-optimized GPU implementation of 2D convolution and all the other operations inherent in training convolutional neural networks, which we make available publicly.
- Our network contains a number of new and unusual features which improve its performance and reduce its training time, which are detailed in Section 3.
- The size of our network made overfitting a significant problem, even with 1.2 million labeled training examples, so we used several effective techniques for preventing overfitting, which are described in Section 4.
Our final network contains five convolutional and three fully-connected layers, and this depth seems to be important: we found that removing any convolutional layer (each of which contains no more than 1% of the model’s parameters) resulted in inferior performance. (我们最终的神经网络包含五个卷积层和三个全连接层,它们的深度都是很重要的:我们发现无论移除哪一层都会影响性能,虽然说这里面的一个只包含模型参数的1%不到。)
In the end, the network’s size is limited mainly by the amount of memory available on current GPUs and by the amount of training time that we are willing to tolerate. Our network takes between five and six days to train on two GTX 580 3GB GPUs. All of our experiments suggest that our results can be improved simply by waiting for faster GPUs and bigger datasets to become available. (最后,神经网络的大小受限于当前GPU上可用的内存量和我们所能接受的训练时间。我们的神经网络使用GTX 580 3GB的GPUs,大概花费五到六天。实验表明,只需等待更快的GPU和更大的数据集就可以改善我们的结果。)
2、The Dataset
数据ImageNet,以及top-1error and top-2 error。
top1——测试图像中正确标签不在模型认为最可能的一个标签中的比例。
The top-5 error rate is the fraction of test images for which the correct label is not among the five labels considered most probable by the model.(top5——测试图像中正确标签不在模型认为最可能的五个标签中的比例。)
对ImageNet数据库的图像只进行了尺寸的改变256×256,(长方形的就把短边放大到256来截)
3、The architecture
- ReLU Nonlinearity
相对于一般的sigmod和tanh来说,ReLU: f(x)=max(0,x), 只需要比较与0的大小,很大程度上提高了训练速度。

- Training on Multiple GPUs
A single GTX 580 GPU has only 3GB of memory, which limits the maximum size of the networks that can be trained on it. (单个内存3GB的GTX 580 GPU限制了在其上进行神经网络训练的网络大小。) The parallelization scheme that we employ essentially puts half of the kernels (or neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers. (实际上,我们采用的并行化方案将每个内核的一半(或神经元)放在每个GPU上,还有另外一个技巧:GPU仅在某些层进行通信。) Choosing the pattern of connectivity is a problem for cross-validation, but this allows us to precisely tune the amount of communication until it is an acceptable fraction of the amount of computation. (选择连接模式是交叉验证的一个问题,但这使我们可以精确地调整通信量,直到它是计算量的可接受的一部分为止。)即两块GPU上的数据是否通信。
- Local Response Normalization
ReLUs have the desirable property that they do not require input normalization to prevent them from saturating. The following local normalization scheme aids generalization. (ReLU具有不需要输入正则化即可防止饱和理想的属性,但局部归一化方案有助于泛化。)
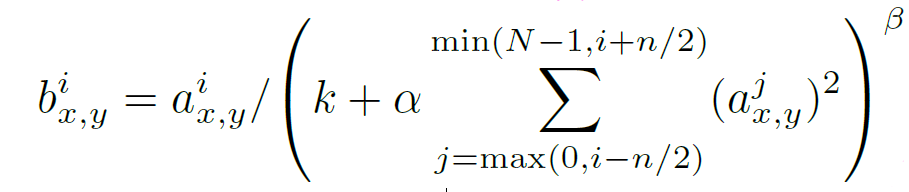
a表示第i个核在位置(x, y) 运用ReLU 非线性神经元输出;
n 是同一位置上临近kernel map的数目;
N 是kernel 总数;
参数 k, n, α, β都是超参数,一般设置为k=2, n=5, α=10-4, β = 0.75。
We applied this normalization after applying the ReLU nonlinearity in certain layers.

- Overlapping Pooling
Pooling layers in CNNs summarize the outputs of neurons in the same kernel map. Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap. To be more precise, a pooling layer can be thought of as consisting of a grid of pooling units spaced s pixels apart. If we set s = z, we obtain traditional local pooling as commonly employed in CNNs. If we set s < z, we obtain overlapping pooling. This is what we use throughout our network, with s = 2 and z = 3. (CNN中的池化层汇总了同一kernel map中神经元的输出。 传统上意义上由相邻池化单元的邻域是不重叠的。 更准确地说,一个池化层可以视为一个由间隔为s个像素的池化单元网格组成。 如果设置为s = z,我们将得到CNN中常用的传统池化池。 如果设置s < z,则得到的是重叠池。 这就是我们在整个网络中使用的数据,其中s = 2,z = 3。)
- Overall Architecture
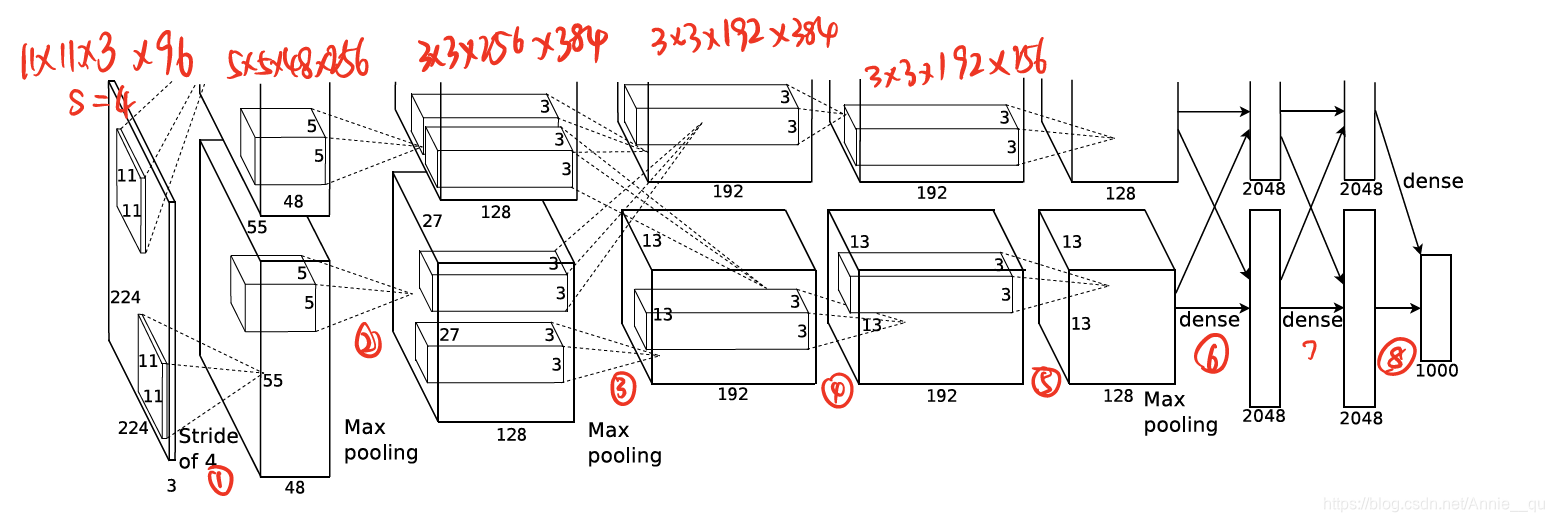
网络包含了带权重的八层,前五层是卷积层后三层是全连接层,以及最后的是一个包含产生一个有1000种标签输出的分布的1000-way softmax。第2, 4, 5 层卷积核只与同一GPU上的上层卷积核相连(有两个并行的GPU,前面讲了),第三层卷积核是与第二层所有的kernel map相连。全连接层也是连接所有的上层neurons。一二层卷积层后有Response-normalization layer。 Max-pooling layers follow both response-normalization layers as well as the fifth convolutional layer. ReLU非线性函数使用于每一个卷积和全连接层后。
4、Reducing overfitting
本文中的神经网络包含大约6千万参数,虽然ILSVRC的1000个类别让每个训练样本从图像到标签的映射限制在了10 bits 之内,但是仍然不能保证这么大的参数量不会过拟合,所以需要考虑过拟合。
有两种防止过拟合的方法,一种是数据增强,也就是增加数据量,二是dropout。
- Data Augmentation
The easiest and most common method to reduce overfitting on image data is to artificially enlarge the dataset using label-preserving transformations. (最简单也最常用的降低过拟合的方法,就是使用保留标签转换的方法,对数据集进行人为扩大。)
同样,数据增强也有两种方法,一是从256×256的图像(及其水平映射)中随机提取出224×224的图像进行训练,一张图片就可以变成多张训练图片了。测试集则也用同样的办法,从四个角以及中间各取一张图像生成五张,加上同样方式提取的水平映射的五张,一共十张图像进行测试。
第二种数据增强的方法是改变训练图像RGB通道灰度值。对训练图片RGB 像素值使用PCA。To each training image, we add multiples of the found principle components, with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from a Gaussian with mean zero and standard deviation 0.1. (对每个训练图像,我们添加多个由PCA找到的主成分,大小与特征值成比例,再乘以一个高斯N(0,0.1)分布的一个随机值。)
对一个RGB像素值![]() ,有
,有
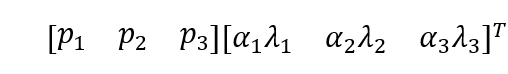
![]() 和
和![]() 是第i个特征值和特征值对应的RGB像素的3×3协方差矩阵,
是第i个特征值和特征值对应的RGB像素的3×3协方差矩阵,![]() 则是高斯随机值。This scheme approximately captures an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination. (该方案尽可能地捕获了原始图像的重要属性,即,对象的身份不受光照的强度和颜色变化影响。)
则是高斯随机值。This scheme approximately captures an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination. (该方案尽可能地捕获了原始图像的重要属性,即,对象的身份不受光照的强度和颜色变化影响。)
- Dropout
The recently-introduced technique, called “dropout”, consists of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in backpropagation. So every time an input is presented, the neural network samples a different architecture, but all these architectures share weights. This technique reduces complex co-adaptations of neurons, since a neuron cannot rely on the presence of particular other neurons. It is, therefore, forced to learn more robust features that are useful in conjunction with many different random subsets of the other neurons. At test time, we use all the neurons but multiply their outputs by 0.5, which is a reasonable approximation to taking the geometric mean of the predictive distributions produced by the exponentially-many dropout networks. (最近引入的技术称为“dropout”,包括将每个隐藏神经元的输出以50% 的概率设置为零。被置为0的神经元不会对正向传播做出贡献,也不会参与反向传播。 因此,对每次输入,神经网络都采用不同的结构进行训练(50%置零),但是所有结构都会共享权重。 所以神经元无法依靠特定其他神经元而存在,则该技术减少了神经元的复杂共适应。由于被迫学习更健壮的特征,这些特征可与其他神经元的许多不同随机子集(特征)结合使用。 在测试时,我们使用所有神经元,但将它们的输出乘以0.5,也就是合理地采用以指数级下降的网络所预测的分布的几何平均值。)
5、Detail of learning
使用随机梯度下降法进行训练,以及一些参数设置。
6、Results
在这个部分描述了网络运用在ILSVRC-2010,ILSVRC-2012,ImageNet Fall 2011以及ImageNet Fall 2009上的结果。
定性分析:在两块GPU上,对输入图像的第一次卷积后的96个卷积核进行反洗,可以看出GPU1基本与颜色无关,而GPU2很大程度上与颜色有关。特性每次运行都不一样,与权重参数也没有关系。
另外,在ILSVRC-2010中,top-5 还是比较靠谱的。另外,图像是否相似,可以通过the feature activations included by an image at the last. 使用欧式距离来计算图像各实值向量的相似性。It could be made efficient by training an auto-encoder to compress these vectors to short binary codes.
7、Discussion
Our results show that a large, deep convolutional neural network is capable of achieving record-breaking results on a highly challenging dataset using purely supervised learning. 本文这个版本已经是能做到的最好的版本了删掉任何一层都会让错误率增加。本文没有用非监督学习的方法进行预训练,虽然使用可能会让结果更好。当然可以继续对神经网络进行优化设计,像人类的视觉神经系统学习。

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









