







 本文分享了使用PyQt设计GUI界面的过程,并介绍了如何利用PyInstaller将Python深度学习项目打包成Windows可执行文件。文中详细讲解了终端输出、错误信息显示、按钮样式设置等技巧,同时针对打包过程中遇到的大文件及运行速度慢等问题提供了有效的解决方案。
本文分享了使用PyQt设计GUI界面的过程,并介绍了如何利用PyInstaller将Python深度学习项目打包成Windows可执行文件。文中详细讲解了终端输出、错误信息显示、按钮样式设置等技巧,同时针对打包过程中遇到的大文件及运行速度慢等问题提供了有效的解决方案。
这里记录一下想要将我们的深度学习代码封装
如何在windows上实现
由于我比较习惯python
所以相对于qt师兄给我们推荐了pyqt以及pyinstaller
这两个一个做页面
一个来封装代码
所以这里记录一下学习过程
先来安装 看如何在vscode里使用pyqt
查看这篇博文
然后具体操作的步骤可以查看这个博客
各种步骤可以跟着学习
把程序终端输出的内容输出到我设计的GUI界面
我参考了这篇博客
这篇博客的方法超级简单
首先需要在编译生成的GUI界面加上这段代码
def printf(self, mes):
self.output.append(mes) # 在指定的区域显示提示信息
self.cursot = self.output.textCursor()
self.textBrowser.moveCursor(self.cursot.End)
QtWidgets.QApplication.processEvents()
然后在主程序里调用就可以了
Ui_MainWindow.printf(self,str(i/10)+' %.2f'%(time()-tic))
但是需要注意数据必须都是str格式的
否则会报错
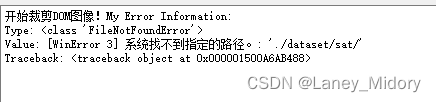
把程序错误内容输出到我设计的GUI界面
主要参考了这篇博客
主要是添加了这几部分代码
首先是外面的函数
def exceptOutConfig(exctype, value, tb):
print('My Error Information:')
print('Type:', exctype)
print('Value:', value)
print('Traceback:', tb)
class EmittingStr(QtCore.QObject):
textWritten = QtCore.pyqtSignal(str) # 定义一个发送str的信号
def write(self, text):
self.textWritten.emit(str(text))
然后是在主类中
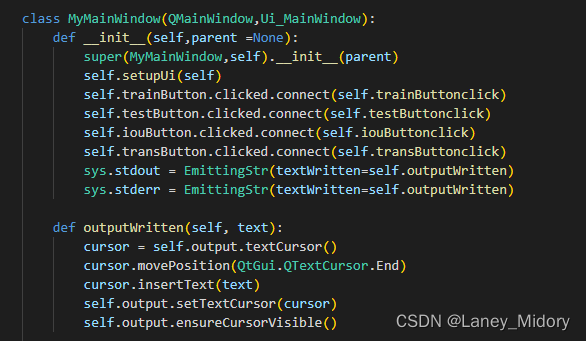
sys.stdout = EmittingStr(textWritten=self.outputWritten)
sys.stderr = EmittingStr(textWritten=self.outputWritten)
def outputWritten(self, text):
cursor = self.output.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.output.setTextCursor(cursor)
self.output.ensureCursorVisible()
最后是if _name_中
if __name__ == "__main__":
sys.excepthook = exceptOutConfig
app = QApplication(sys.argv)
myWin = MyMainWindow()
myWin.show()
sys.exit(app.exec_())
就会有报错信息啦
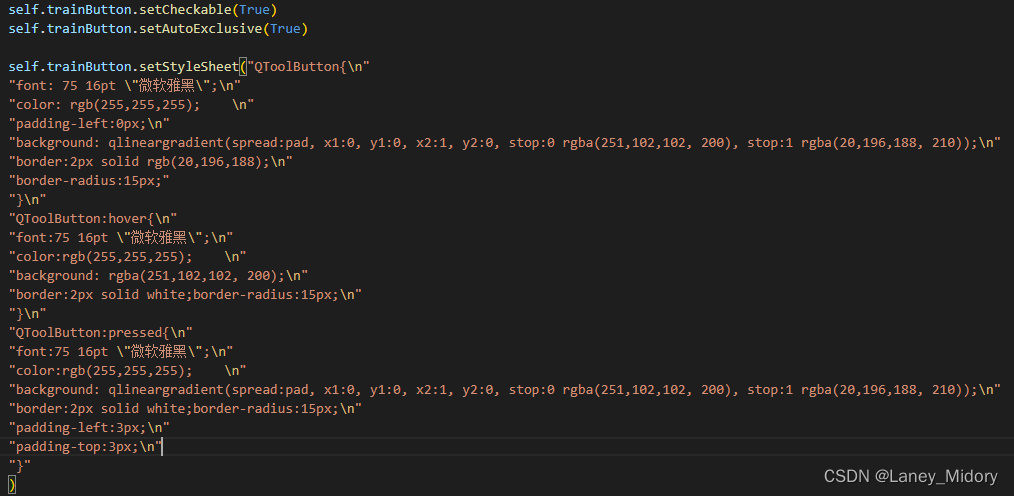
为按钮添加悬停变化
这里我主要参考了这篇博客
讲的非常详细
直接看就好啦
对我来说
就是为每一个控件添加了下面的代码
pyinstaller 封装成exe文件
封装可以直接搜索就有啦
只是我的程序比较大 要稍微多等等
有了exe文件之后报错
这篇博客可以解决
ImportError: ERROR: recursion is detected during loading of “cv2” binary extensions. Check OpenCV installation.
我是参考了这篇博客
卸载重装了opencv-python更换成了4.5的版本
就可以运行啦
虽然成功运行啦
但是还是有运行速度慢,exe太大了的问题
运行速度太慢,程序太大
如何解决这个问题
目前参考了这篇文章
因此我总结一下我的方法
首先是使用下面的语句进行打包
pyinstaller -D -w act_deepl.py
这样生成的虽然不是一个exe文件,但启动速度非常快,包的大小为4.9G
pyinstaller -F -w act_deepl.py
这样生成的是一个exe文件,但是启动速度超级慢,包的大小是2.5G
这俩有利有弊吧
然后尝试使用Enigma Virtual Box打包exe
但是失败了
这个软件出来的包无法在电脑上运行
不知道为什么
所以最可靠的方法就只有新建一个虚拟环境
只安装我们需要的包然后打包最后删除该虚拟环境了
无法避免生成一个大包了
打包总结
打开anaconda的prompt
激活安装了pyinstall的虚拟环境
conda activate torch
进入打包的程序路径
cd C:\Users\Administrator\Desktop\Deepl
开始打包成一个文件夹
pyinstaller -D -w act_deepl.py




















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











