







一、 Transformer结构上有哪些可以优化的点?
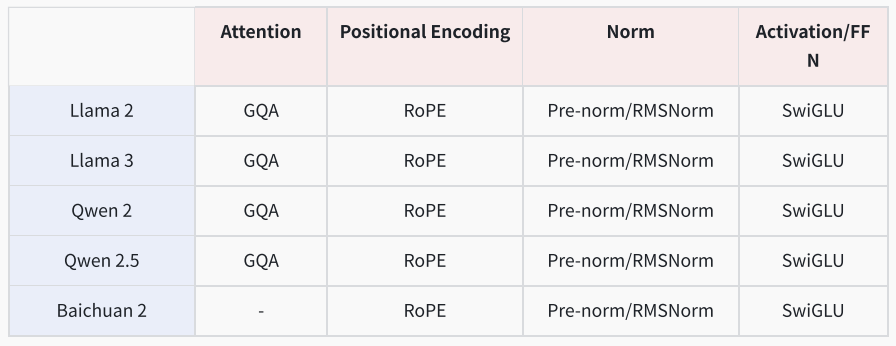
1. Attentiona. Scaled Product Attention2. Positional Encodinga. RoPE3. Norma. pre-normalizationb. RMSNorm4. Activation function/FFNa. SwiGLU5. Inference Speedupa. KV Cacheb. GQA
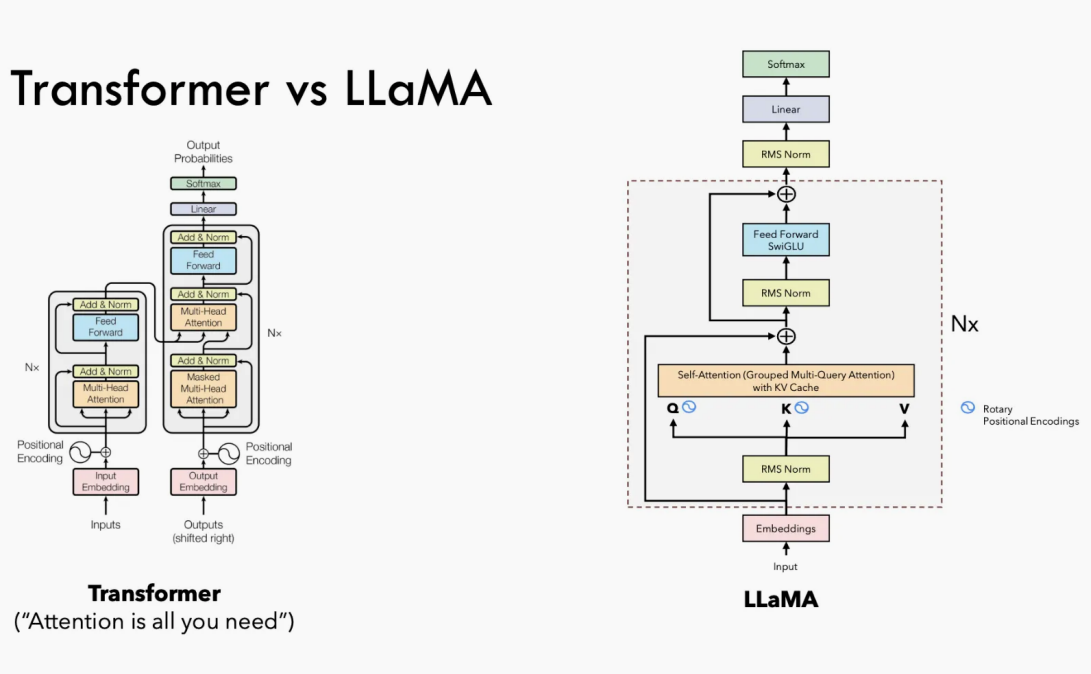
二 、KV Cache
为什么LLM在输出⻓序列的时候,到后长没有感觉很慢呢?按算法原理
1. 因为除了每⼀个新出的字都要与前面所有的字计算相关性,
2. 并且前面出现的字,还要和更前面的字计算相关性,
越到后⾯需要计算的历史越多,应该越慢。时间复杂度是O(n*n) ->需要写两个循环
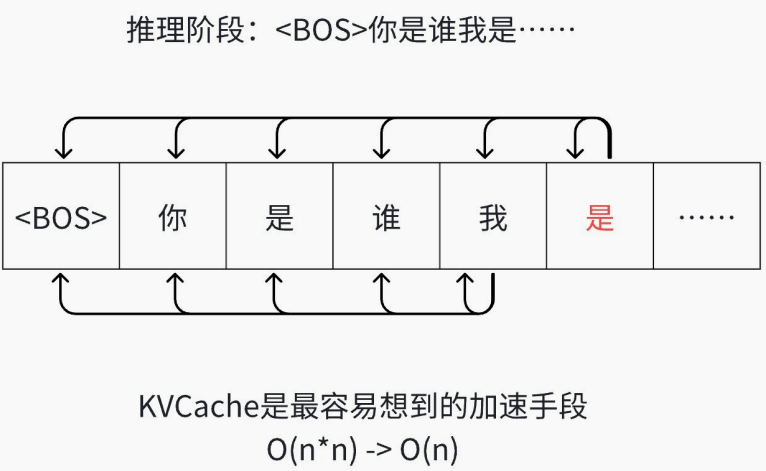
为何只对Key 和 Value使⽤Cache?因为只有Key和Value要重复使⽤,Query不需要重复使⽤。是针对推理阶段的优化技术。
因为只有推理阶段才是⼀个⼀个往外出字的
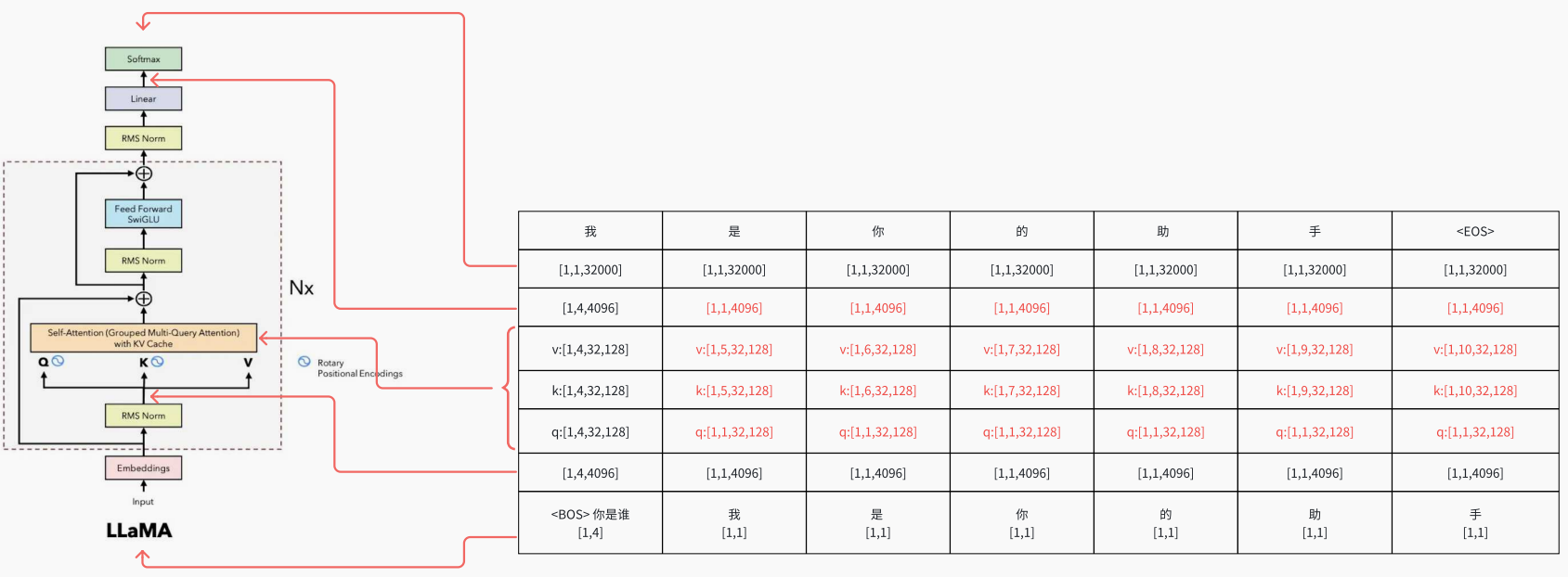
1 输⼊序列:你 是 谁2 输出序列:我 是 你 的 助 ⼿34 # 注意这⾥是与 Ecoder-Decoder 结构不同的56 第⼀步: <BOS> 你 是 谁 -> 我7 第⼆步: <BOS> 你 是 谁 我 -> 是8 第三步: <BOS> 你 是 谁 我 是 -> 你9 第四步: <BOS> 你 是 谁 我 是 你 -> 的10 第五步: <BOS> 你 是 谁 我 是 你 的 -> 助11 第六步: <BOS> 你 是 谁 我 是 你 的 助 -> ⼿12 第七步: <BOS> 你 是 谁 我 是 你 的 助 ⼿ -> <EOS>1314 最终结果: <BOS> 你 是 谁 -> 我 是 你 的 助 ⼿ <EOS>
原始的计算过程:
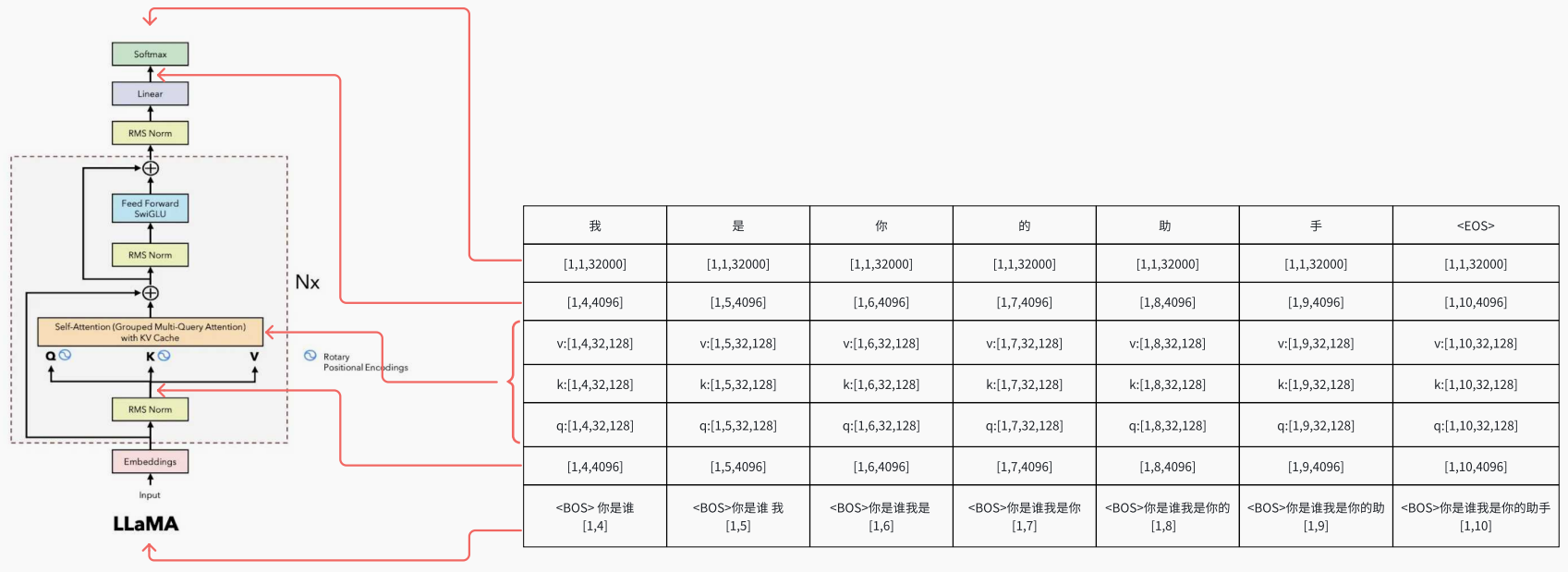
加入KV Cache 的过程:
KV cache strategies
The key-value (KV) vectors are used to calculate attention scores. For autoregressive models, KV scores are calculated every time because the model predicts one token at a time. Each prediction depends on the previous tokens, which means the model performs the same computations each time.
A KV cache stores these calculations so they can be reused without recomputing them. Efficient caching is crucial for optimizing model performance because it reduces computation time and improves response rates. Refer to the Caching doc for a more detailed explanation about how a cache works.
Transformers offers several Cache classes that implement different caching mechanisms. Some of these Cache classes are optimized to save memory while others are designed to maximize generation speed. Refer to the table below to compare cache types and use it to help you select the best cache for your use case.
| Cache Type | Memory Efficient | Supports torch.compile() | Initialization Recommended | Latency | Long Context Generation |
|---|---|---|---|---|---|
| Dynamic Cache | No | No | No | Mid | No |
| Static Cache | No | Yes | Yes | High | No |
| Offloaded Cache | Yes | No | No | Low | Yes |
| Offloaded Static Cache | No | Yes | Yes | High | Yes |
| Quantized Cache | Yes | No | No | Low | Yes |
| Sliding Window Cache | No | Yes | Yes | High | No |
| Sink Cache | Yes | No | Yes | Mid | Yes |
Default cache
The DynamicCache is the default cache class for most models. It allows the cache size to grow dynamically in order to store an increasing number of keys and values as generation progresses.
Disable the cache by configuring
use_cache=Falsein generate().
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
model.generate(**inputs, do_sample=False, max_new_tokens=20, use_cache=False)Cache classes can also be initialized first before calling and passing it to the models past_key_values parameter. This cache initialization strategy is only recommended for some cache types.
In most other cases, it’s easier to define the cache strategy in the cache_implementation parameter.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
past_key_values = DynamicCache()
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, past_key_values=past_key_values)代码实现
class DynamicCache(Cache):
def __init__(self, num_hidden_layers: Optional[int] = None) -> None:
super().__init__()
self._seen_tokens = 0 # Used in `generate` to keep tally of how many tokens the cache has seen
self.key_cache: List[torch.Tensor] = [] # shape:`[batch_size, num_heads, seq_len, head_dim]`
self.value_cache: List[torch.Tensor] = [] # shape:`[batch_size, num_heads, seq_len, head_dim]`
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]: # Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
# Update the cache
if len(self.key_cache) <= layer_idx:
# There may be skipped layers, fill them with empty lists
for _ in range(len(self.key_cache), layer_idx):
self.key_cache.append([])
self.value_cache.append([])
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif len(self.key_cache[layer_idx]) == 0: # fills previously skipped layers; checking for tensor causes errors
self.key_cache[layer_idx] = key_states
self.value_cache[layer_idx] = value_states
else:
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
# 返回所有Cache的值
return self.key_cache[layer_idx], self.value_cache[layer_idx]
class LlamaAttention(nn.Module):
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
**kwargs, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# use -1 to infer num_heads and num_key_value_heads as they may vary if tensor parallel is used
query_states = query_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
if past_key_value is not None: # sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position":
cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
attn_output = torch.matmul(attn_weights, value_states)
return attn_output, attn_weights, past_key_value对 KV Cache 的总结:• 以空间换时间加速优化• 只在推理阶段使⽤,因为训练时是⼀起算的,不⽤⼀步⼀步算• 只在Decoder结构中使⽤◦ Encoder中的self-attention是并⾏计算的,⼀次就算出了全部结果◦ Decoder中的cross-attention计算,其Key和Value是Encoder输出的结果,本来也缓 存◦ LLM都是Decoder-only的结构,不涉及以上两种Attention的计算• KVCache占⽤的空间太多怎么办?GQA优化技术
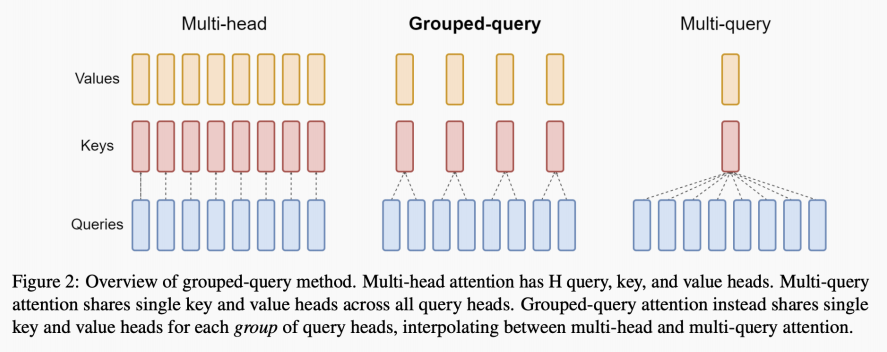
GQA:Group Query Attention
问题⼀:KVCache占⽤空间太⼤怎么办?减少缓存的KV的数量:◦ 别⽤KVCache◦ 只⽤⼀部分◦ 共享使⽤:MQA问题⼆:共享之后,效果下降的厉害怎么办?◦ 别共享太多,在效果和空间占⽤上找个最优点:GQA
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1,
repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads,
seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class LlamaAttention(nn.Module):
def __init__():
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
def forward():
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# use -1 to infer num_heads and num_key_value_heads as they may vary if tensor parallel is used
query_states = query_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
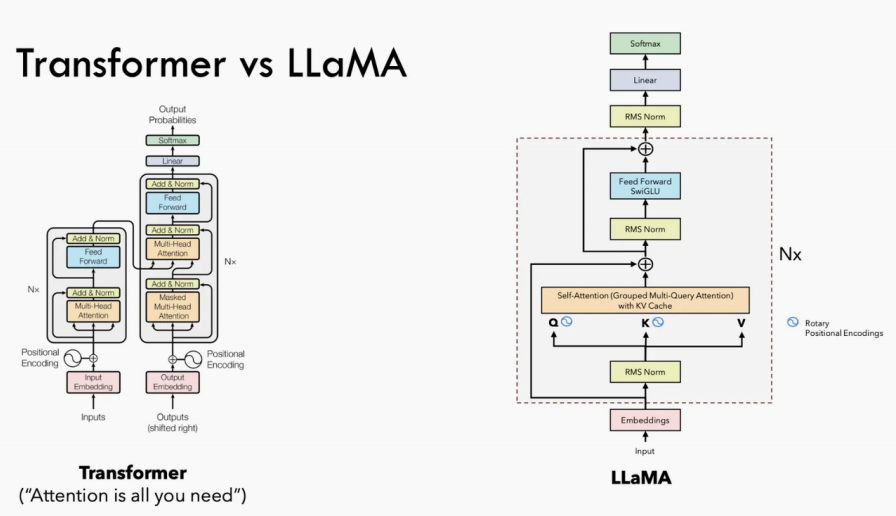
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3))/math.sqrt(self.head_dim)PreNorm与RMSNorm
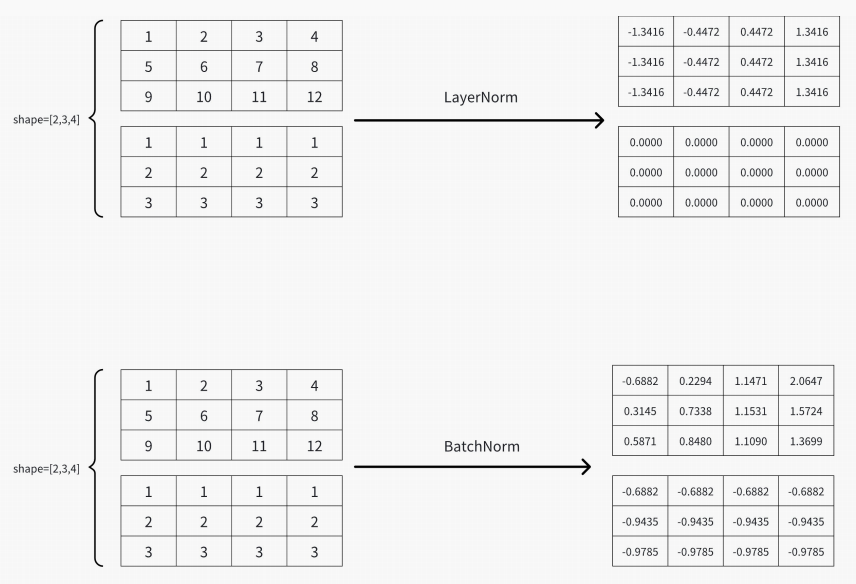
Norm的动机:



常见的Norm操作:BatchNorm VS LayerNorm

RMSNorm

Norm操作的位置


SwiGLU
常见的激活函数:
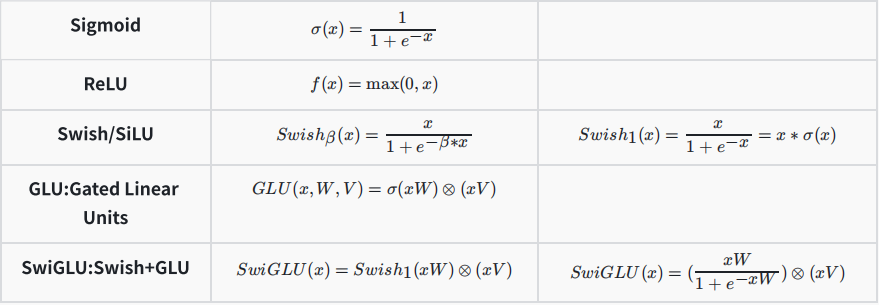
Transformer 与 Llama中的 MLP
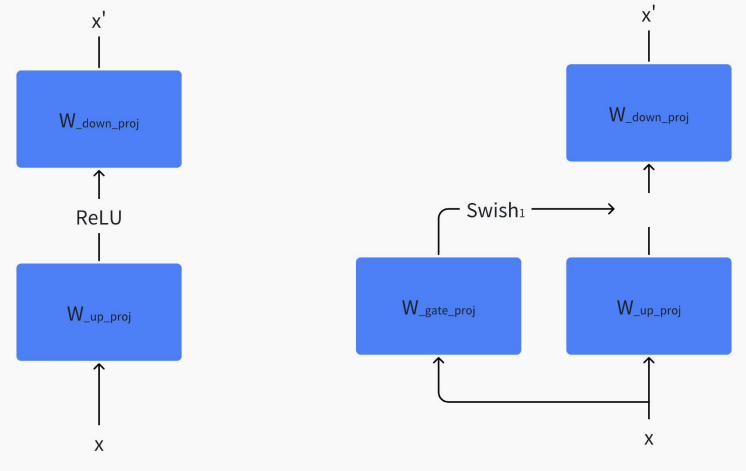
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size,
bias=config.mlp_bias)
self.act_fn = ACT2FN[config.hidden_act] # sigmoid激活函数
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_projRoPE

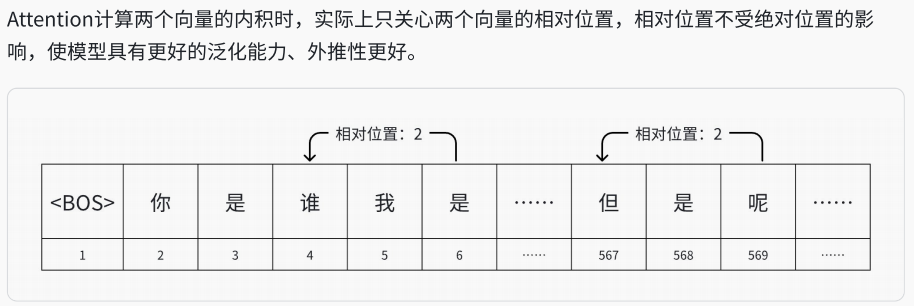

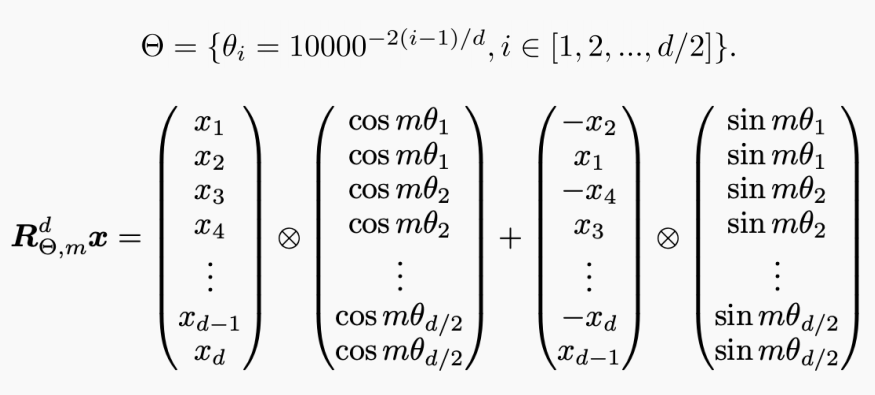
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
class LlamaSdpaAttention():
def forward():
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# use -1 to infer num_heads and num_key_value_heads as they may vary if tensor parallel is used
query_states = query_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
......
cos, sin = self.rotary_emb(value_states, position_ids)
query_states, key_states = apply_rotary_pos_emb(query_states,
key_states, cos, sin)
......
class LlamaRotaryEmbedding(nn.Module):
def __init__():
self.inv_freq = _compute_default_rope_parameters()
def forward(self, x, position_ids):
......
# 计算 m*theta
freqs = (inv_freq_expanded.float() @
position_ids_expanded.float()).transpose(1, 2)
emb = torch.cat((freqs, freqs), dim=-1) # 计算cos(m*theta) sin(m*theta)
cos = emb.cos()
sin = emb.sin()
......
return cos, sin
def _compute_default_rope_parameters():
......
# 计算 theta
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2,
dtype=torch.int64).float().to(device) / dim))
......


















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











