







MTP:Multi-Token Prediction
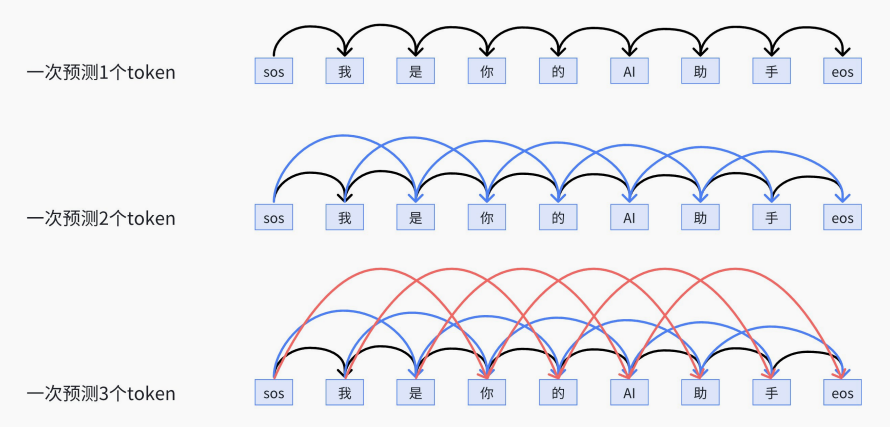
LLM⼀次只能⽣成⼀个token的⽅式好不好?当然不好,能不能⼀次⽣成多个token呢?即使不能,那能不能⼤概知道后⾯要说啥,就像⼈说话的时候,说了前⾯,大概后面要说啥已经有了⼀个⼤概的规划和印象了。MTP是⼀个优化⽅向,有很多论⽂,我们就简单直接讲DeepSeek⾥⾯是怎么做的。训练阶段:提⾼数据利⽤率推理阶段:提⾼推理速度。
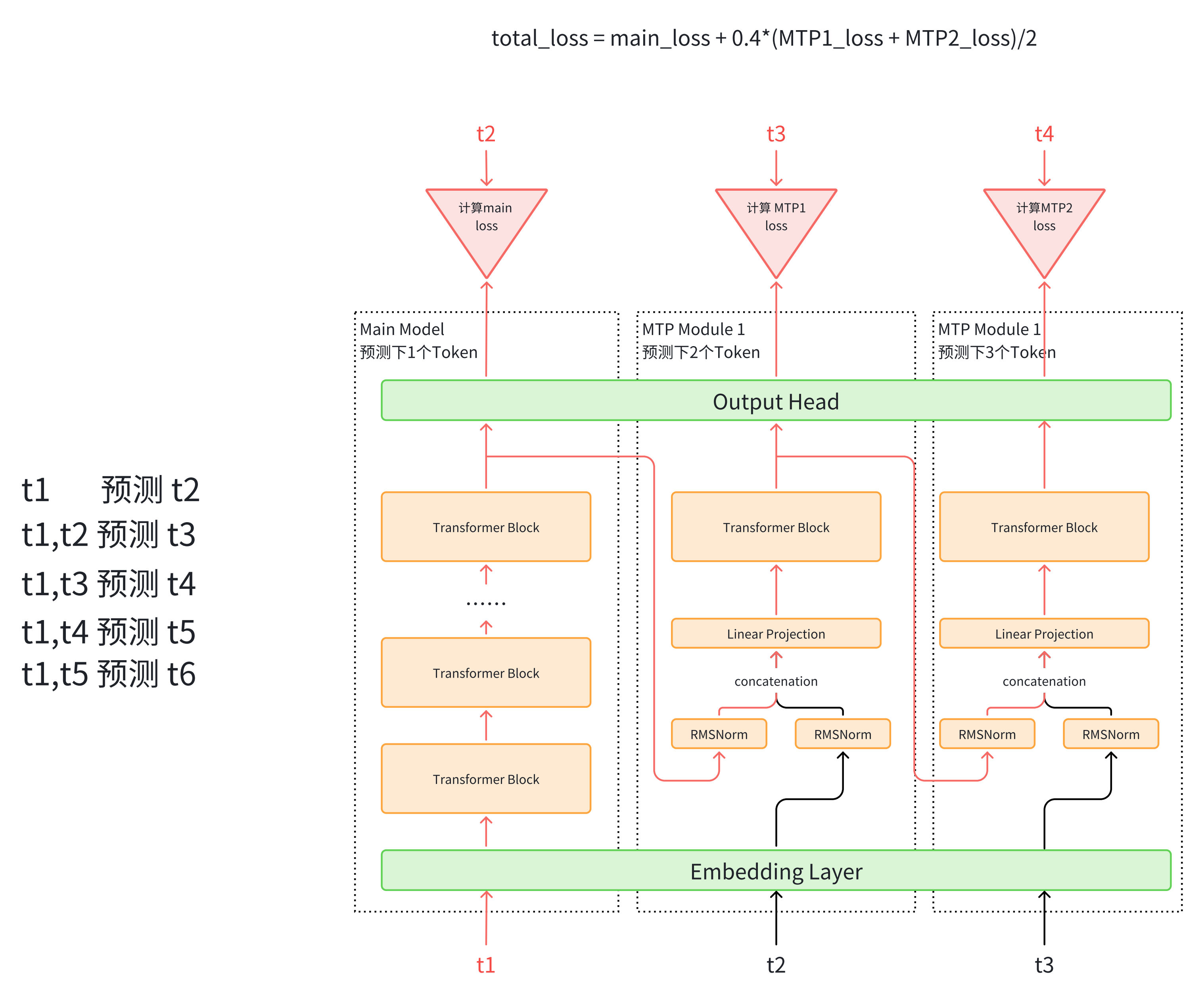
算法1. 只在训练时使用,计算loss;推理时,仍然只用主干⽹络,抛弃MTP模块,每次预测⼀个token2. Loss的计算是将多个MTP模块的loss取平均3. 使⽤上⼀个token辅助预测⼀下,也更符合transformer结构
伪代码:
#伪代码
class MTPBlock(nn.Module):
def __init__(self, emb, output_head):
# 传⼊共享的embedding层和Output_head 层
self.emb = emb
self.output_head = output_head
# 两个RMSNorm层
self.hs_norm = RMSNorm()
self.x_norm = RMSNorm()
# 拼接后的线性投影层
self.projection = nn.Linear()
# 每个MTPblock中的transformer Decoder层
self.trm = nn.TransformerDecoderLayer(...)
def forward(self, x, hidden_states):
# x.shape = [b,s,d_model]
# hidden_states.shape = [b, s, d_model]
x = self.emb(x)
hidden_states = self.hs_norm(hidden_states)
x = self.x_norm(x)
# 两部分拼接后投影
x = torch.cat(hidden_states,x)
x = self.projection(x)
# 投影后过transformer decoder layer
x = self.trm(x)
hidden_states = x
y = self.output_head(x)
# y是这个MTP模块输出,⽤于计算Loss
# hidden_states是输出的隐层,⽤于传⼊下⼀个MTP模块
return y, hidden_states
class MoE(nn.Module):# 在主模块之外,加⼊MTP流程
def __init__(self):
...
self.emb = nn.Embedding()
self.output_head = nn.Linear()
self.num_future_tokens = 3 # 预测下⼏个token,这⾥预测下3个token,也就
有2个MTP模块
# 声明MTP模块
self.MTP = nn.ModuleList([MTPBlock(self.emb, self.output_head)
for i in range(self.num_future_tokens-1)])
def forward(self, x):
# x.shape = [b,s,d_model]
...
hidden_states = ..... # 主流程得到的隐层
main_loss = ...
mtp_loss = 0.0
next_predictions = ... # 主流程预测的下⼀个label
if self.training:# 训练阶段才使⽤MTP流程
for i in range(self.num_future_tokens-1):# 逐个过每个MTP模块
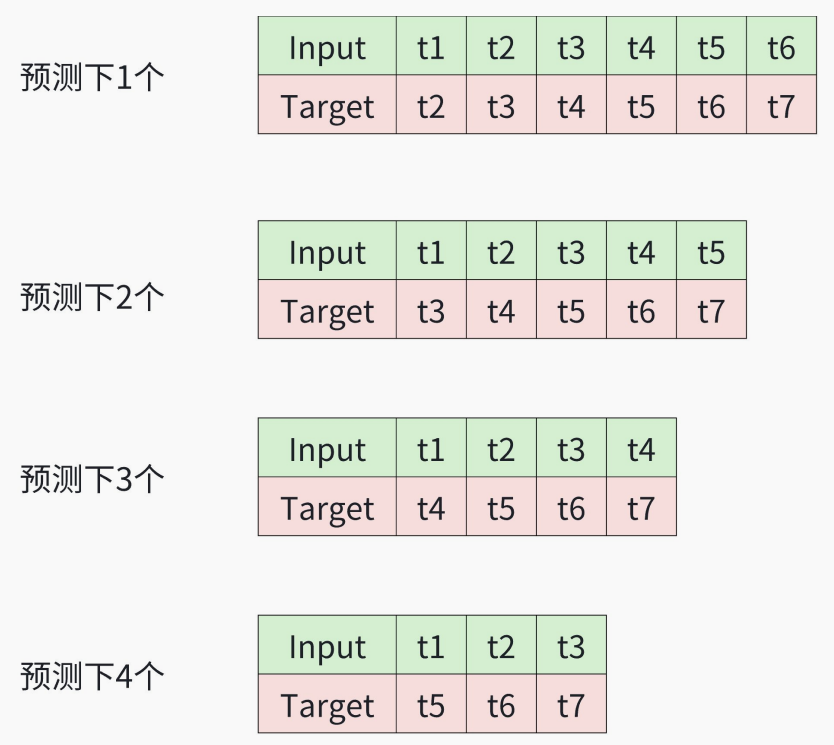
k = i + 2 # 应该预测token的间隔数量
target = x[:,k:,:] # 取对应的输出(⻅下图)
inp = x[:,k-1:-1,:]# 取对应的输⼊(⻅下图)
future_predictions, hidden_states = self.MTP[i](inp, hidden_states)
mtp_loss += nn.CrossEntropy(target, future_predictions)
# 计算总的loss
total_loss = main_loss + 0.3 * mtp_loss/2
...
# 返回主⼲流程预测结果和总的loss
return next_predictions, total_loss
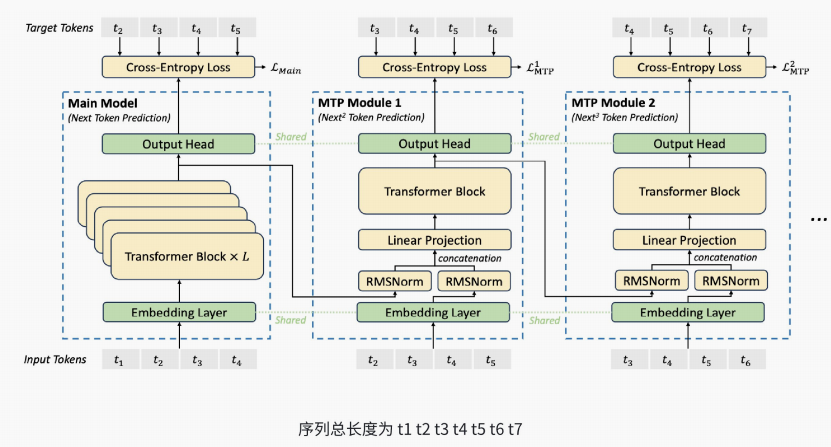
在训练过程中,模型首先通过主模型生成当前输入token的表示,然后将该表示输入第⼀个 MTP子模块,预测下⼀个token的表示。接着,将预测的表示输⼊下⼀个MTP 子模块,继续预测后续的令牌表示。这种方式使得模型在⼀次前向传播中能够预测多个后续令牌,从而丰富了上下文信息,提⾼了训练效率。在推理阶段,MTP 模块可以被丢弃,主模型独立进行推理。




















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











