



 本文围绕生成对抗网络(GAN)展开,介绍了其训练中存在的挑战,如训练不稳定、模式崩溃等。阐述了GAN的评估方法,包括FID指标。还提及了Conditional Generation的使用场景,以及GAN在无监督学习中的应用,如Cycle GAN和StarGAN等图像翻译模型。
本文围绕生成对抗网络(GAN)展开,介绍了其训练中存在的挑战,如训练不稳定、模式崩溃等。阐述了GAN的评估方法,包括FID指标。还提及了Conditional Generation的使用场景,以及GAN在无监督学习中的应用,如Cycle GAN和StarGAN等图像翻译模型。
GAN(下)
GAN的挑战
GAN的训练过程是一个博弈过程,生成器和判别器互相竞争,往往会发生训练不稳定的情况。生成器和判别器需要棋逢敌手。不仅如此,可能会出现模式崩溃,即生成器只能生成一小部分样本,而其他样本都是重复的或无法生成的。还有梯度消失和梯度爆炸、模型选择、训练数据质量。
GAN的评估
问题
- Mode Collapse(模式崩溃)–产生重复的
- Mode Dropping --多样性不够,达不到和data一样丰富的多样性
- GAN产生的图片same as real data
部分解决方式
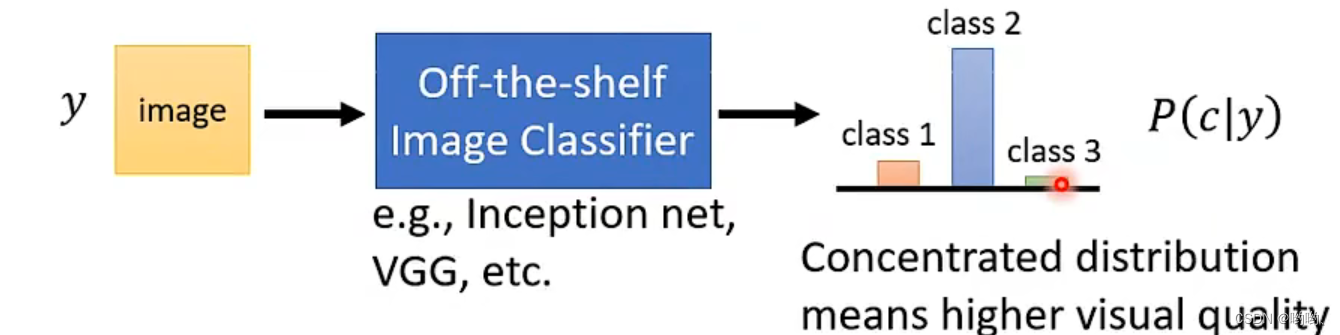
- Quality:把一张放到Inception Network中,当几率分布越集中,可能越好。
- Diversity:把多张图片放入Inception Network,看平均的分布,如果比较平坦,也许多样性足够。
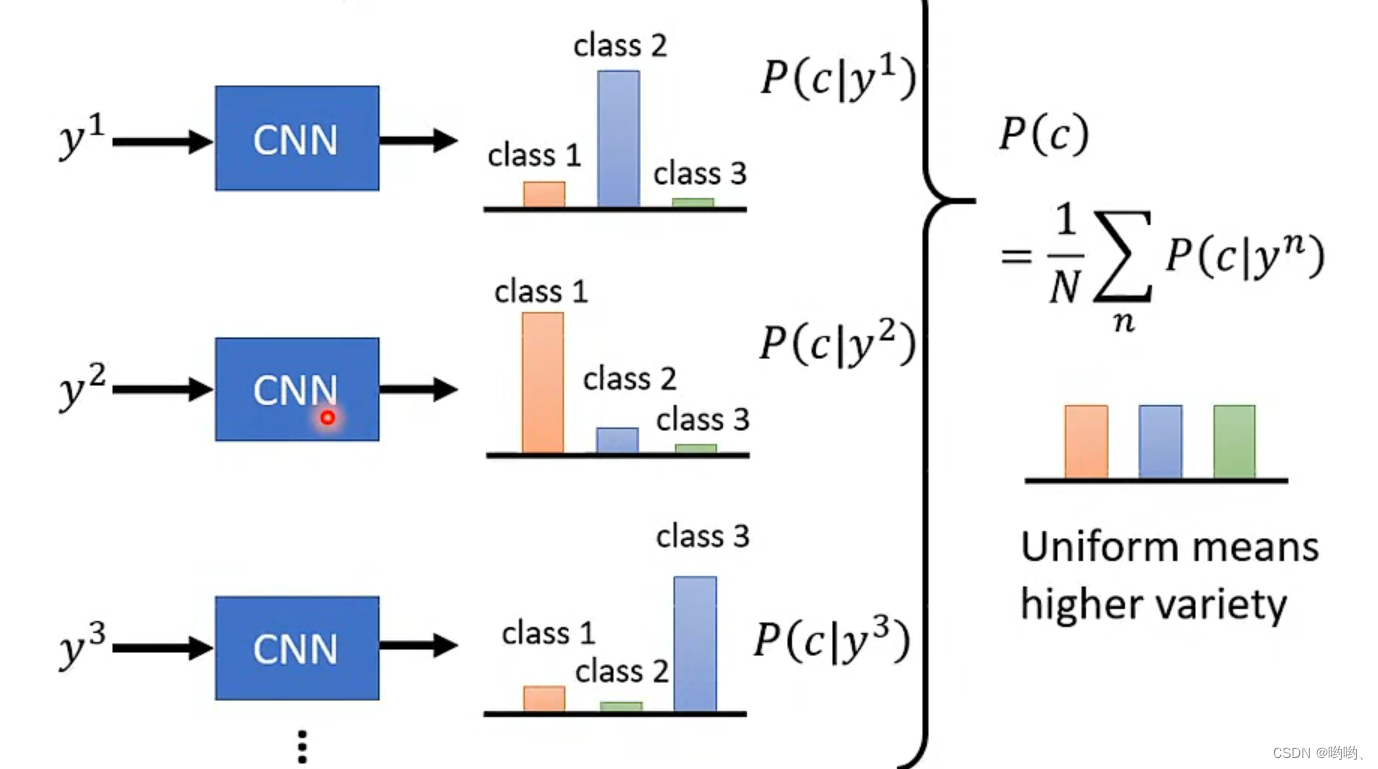
注意:一个是一张图片,一个是多张。Inception Network用于图象分类等。
FID(Fréchet Inception Distance)
FID是一种用于衡量GAN生成图像与真实图像之间差异的指标。FID的计算基于图像的统计特征,具体而言,它使用了Inception网络在图像分类任务上的中间特征(即pool3层)来表示图像的统计特征(中间特征为多维向量)。对于真实图像和生成图像,分别计算它们在Inception网络上的中间特征的均值向量和协方差矩阵,然后计算它们之间的Fréchet距离。FID的值越小,表示生成图像与真实图像之间的差异越小。
Conditional Generation
Conditional Generation是指使用一些条件信息来控制生成模型生成特定类型的数据。在机器学习中,条件信息通常是指一些额外的输入,例如类别标签、文本描述、图像等信息,这些信息有助于生成模型生成特定类型的数据。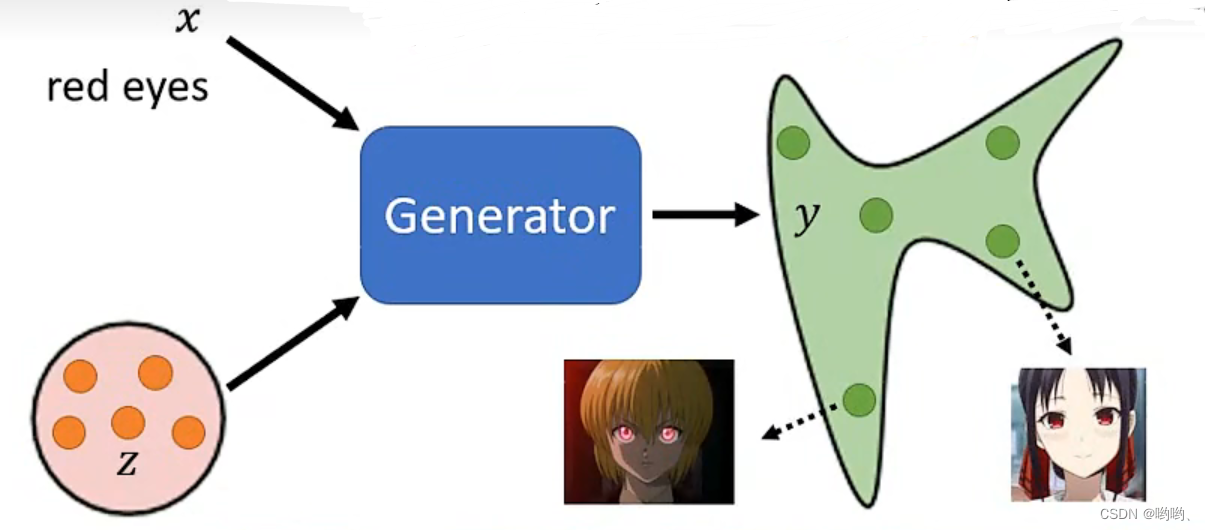
使用
- 文字生成图片
当文字和图片相配的时候,D才会给高分,True text-image pairs,图片与文字信息成对,全面。
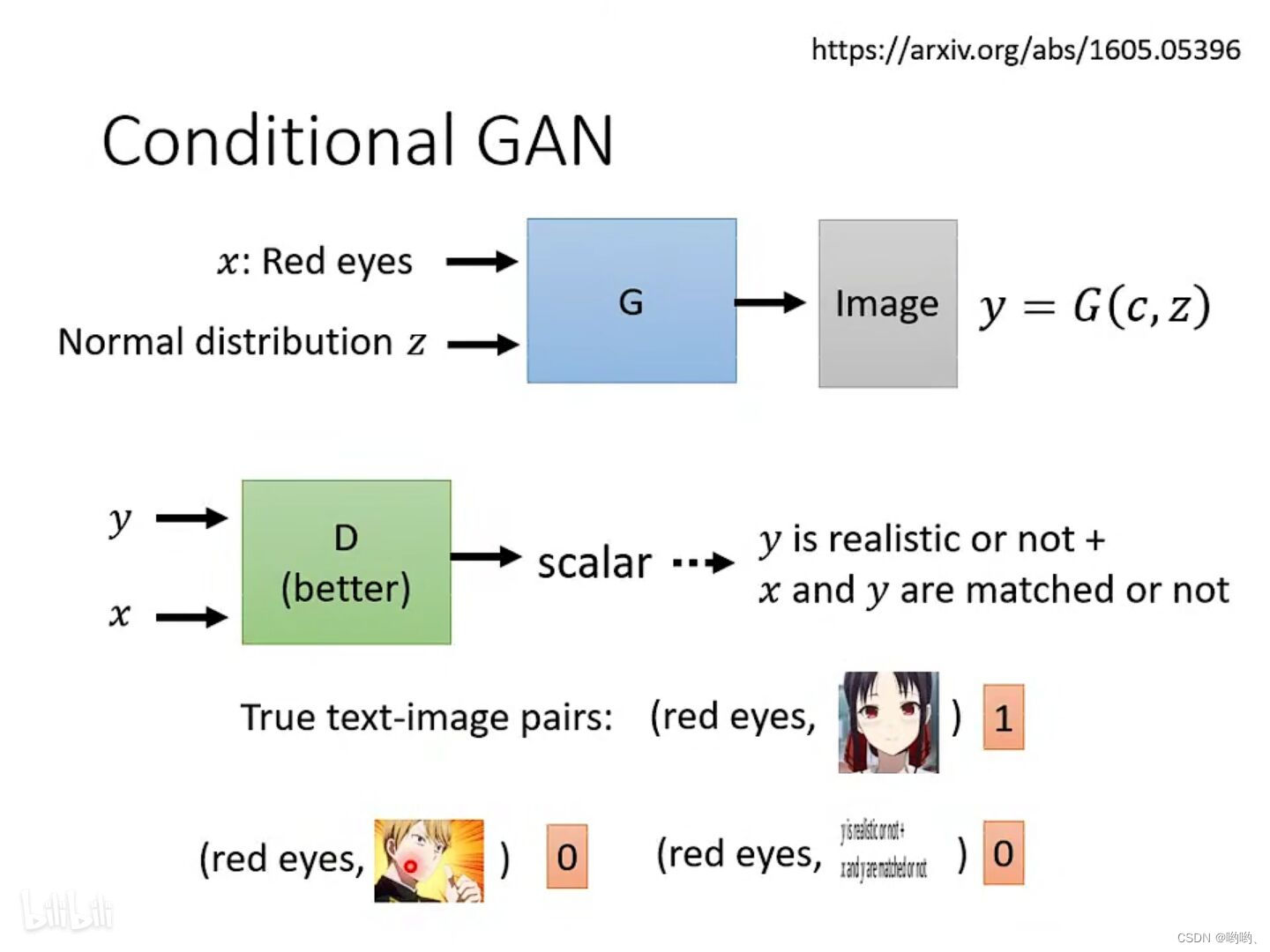
- 图片生成图片
类似于文字生成图片—pix2pix.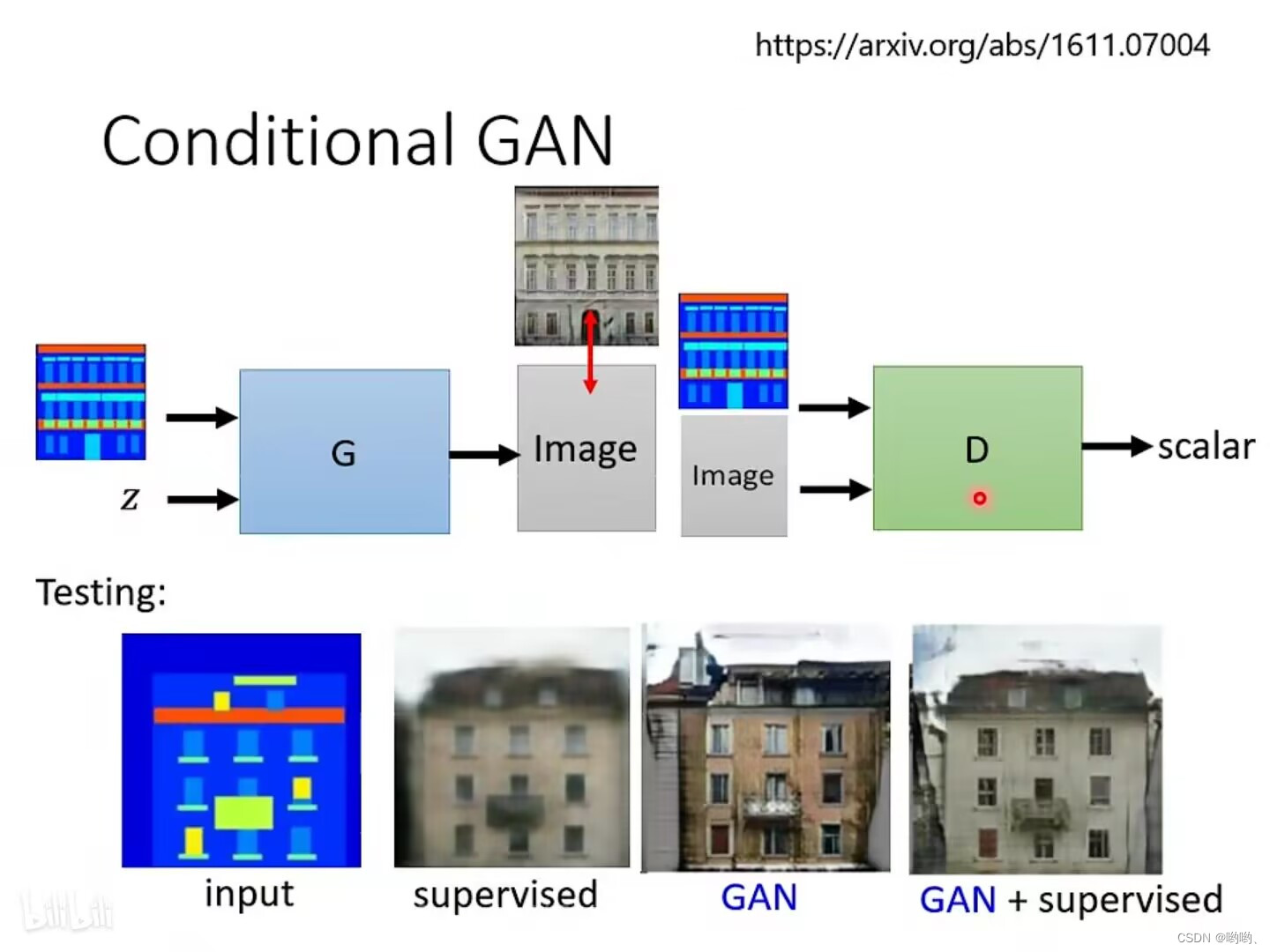
- 其他应用
声音生成文字、图片变成会动的等等。
GAN用在无监督学习
影像风格转换、文字风格转换、摘要、翻译、ASR(将人类的语音信号转换为文本或其他形式的语言表示)等用途。
Cycle GAN
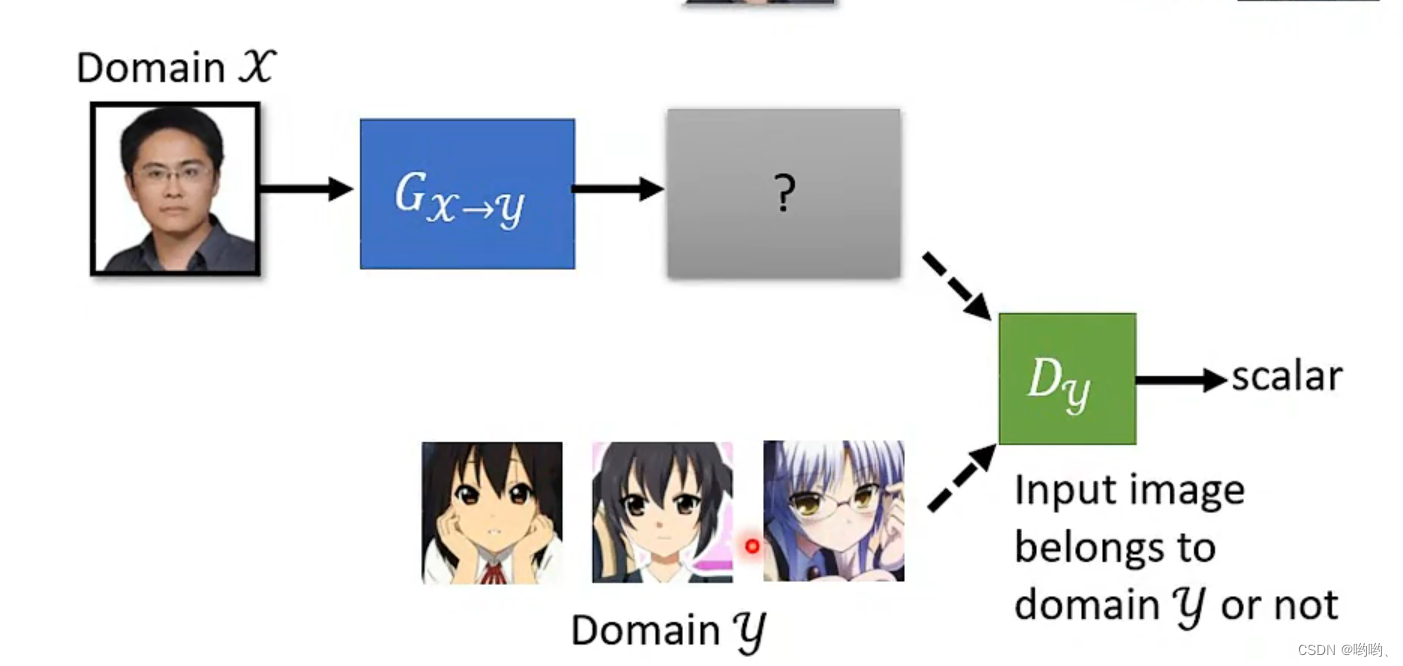
- 可能会ignore input,CycleGAN是一种基于GAN的图像翻译模型,可以将一组图像从一个领域转换到另一个领域,而不需要对应的输入输出对进行配对。它的核心思想是利用两个对抗网络模型,分别用于将一个领域中的图像转换为另一个领域中的图像,同时保持图像的一致性。
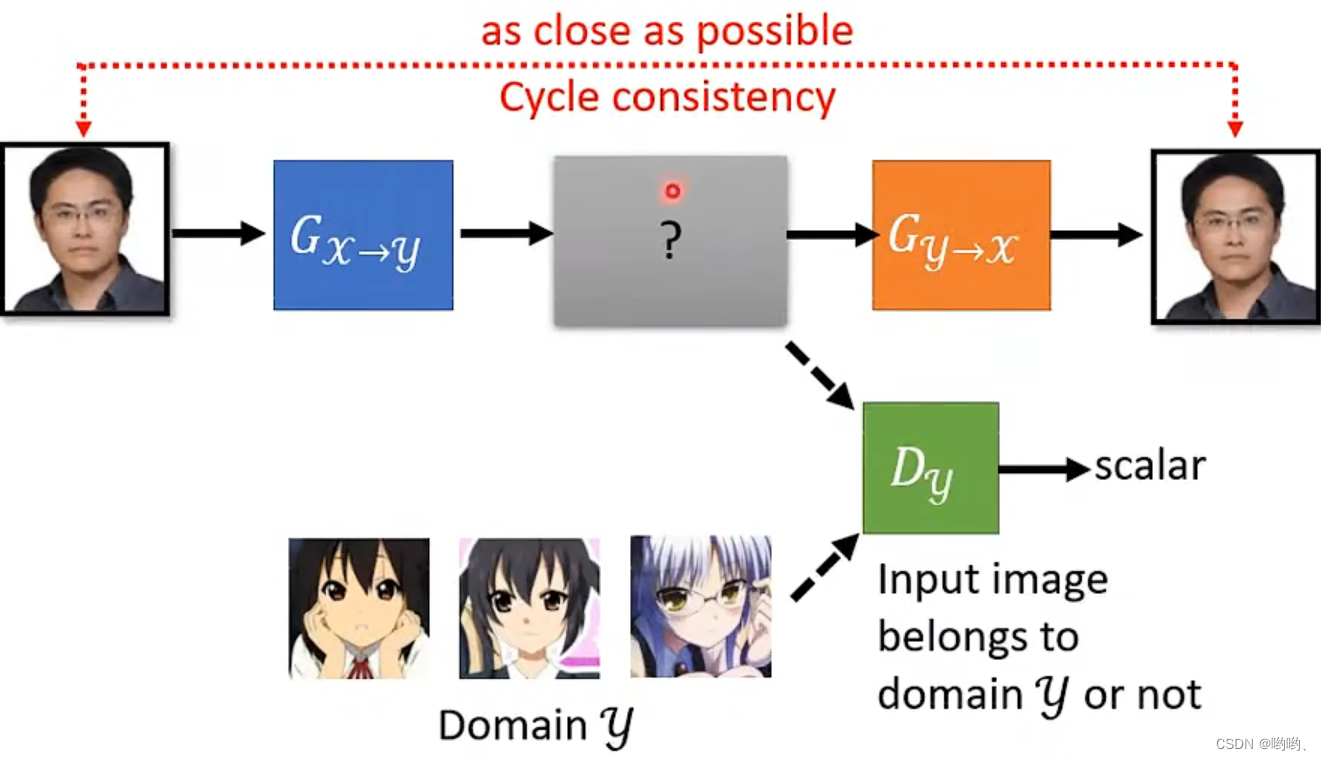
- CycleGAN的网络结构包括两个生成器和两个判别器,其中一个生成器用于将A领域中的图像转换为B领域中的图像,另一个生成器则用于将B领域中的图像转换为A领域中的图像。每个生成器都有一个对应的判别器,用于判断生成器生成的图像是否与真实的图像相似。可能会出现奇怪的转换,几率比较小。Cycle GAN可以双向的。
StarGAN
StarGAN是一种多域图像翻译模型,可以将一张输入图像转换成多个不同域中的图像,例如将一张人脸图像转换为不同年龄、性别、发型、眼镜等不同特征的图像。与CycleGAN不同,StarGAN可以实现多个不同领域之间的图像转换,而不是仅限于两个领域之间的转换。
StarGAN的网络结构包括一个生成器和一个判别器,生成器接收一个输入图像并根据目标域的条件生成相应的输出图像。判别器则用于判断生成的图像是否为真实的图像,同时也要判断这张图像属于哪一个域。StarGAN的损失函数包括对抗性损失、条件重构损失和域分类损失。

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









