



 GAN是一种深度学习框架,通过Generator和Discriminator的博弈来实现数据的无条件生成。Generator尝试从低维向量生成逼真的高维图像,而Discriminator负责区分真实与生成的图像。训练过程中,Generator力求欺骗Discriminator,使其难以区分真假。Wasserstein距离在WGAN中引入以稳定训练过程,防止梯度爆炸或消失,GradientPenalty和SpectralNormalization等技术进一步优化了训练的稳定性和生成效果。
GAN是一种深度学习框架,通过Generator和Discriminator的博弈来实现数据的无条件生成。Generator尝试从低维向量生成逼真的高维图像,而Discriminator负责区分真实与生成的图像。训练过程中,Generator力求欺骗Discriminator,使其难以区分真假。Wasserstein距离在WGAN中引入以稳定训练过程,防止梯度爆炸或消失,GradientPenalty和SpectralNormalization等技术进一步优化了训练的稳定性和生成效果。
GAN(上)
Network as Generator
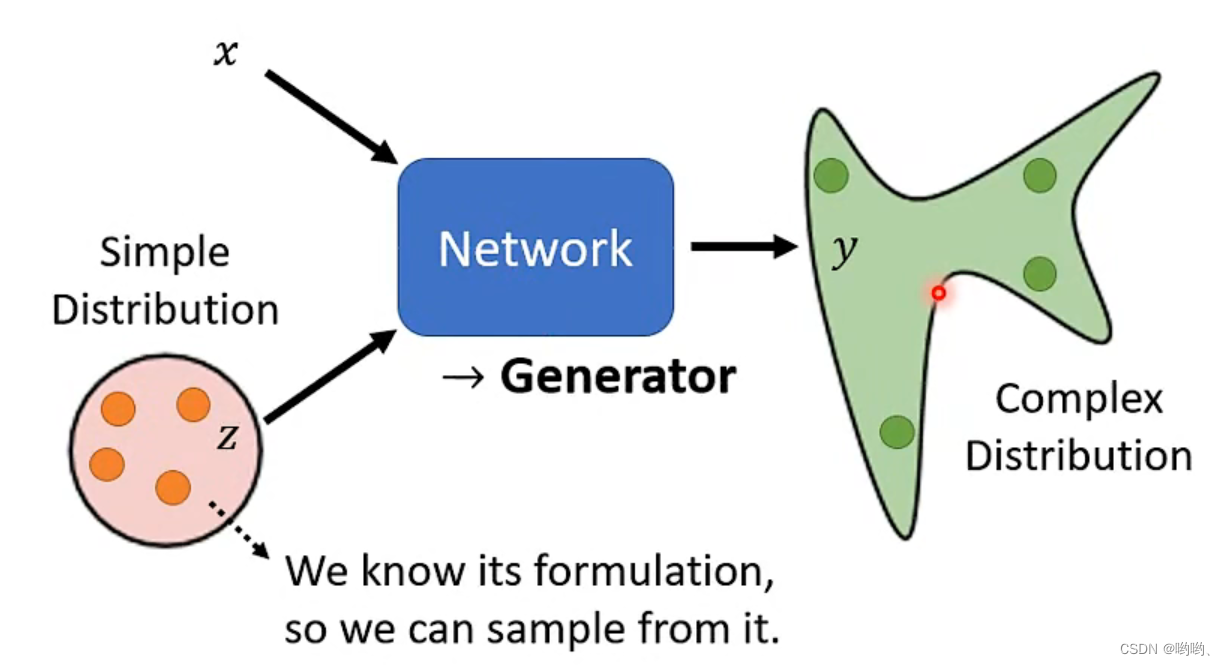
why distribution
当同样的输入有多种可能不同的输出,并且这些输出都是对的。“让机器具有创造能力”
GAN
unconditional generation
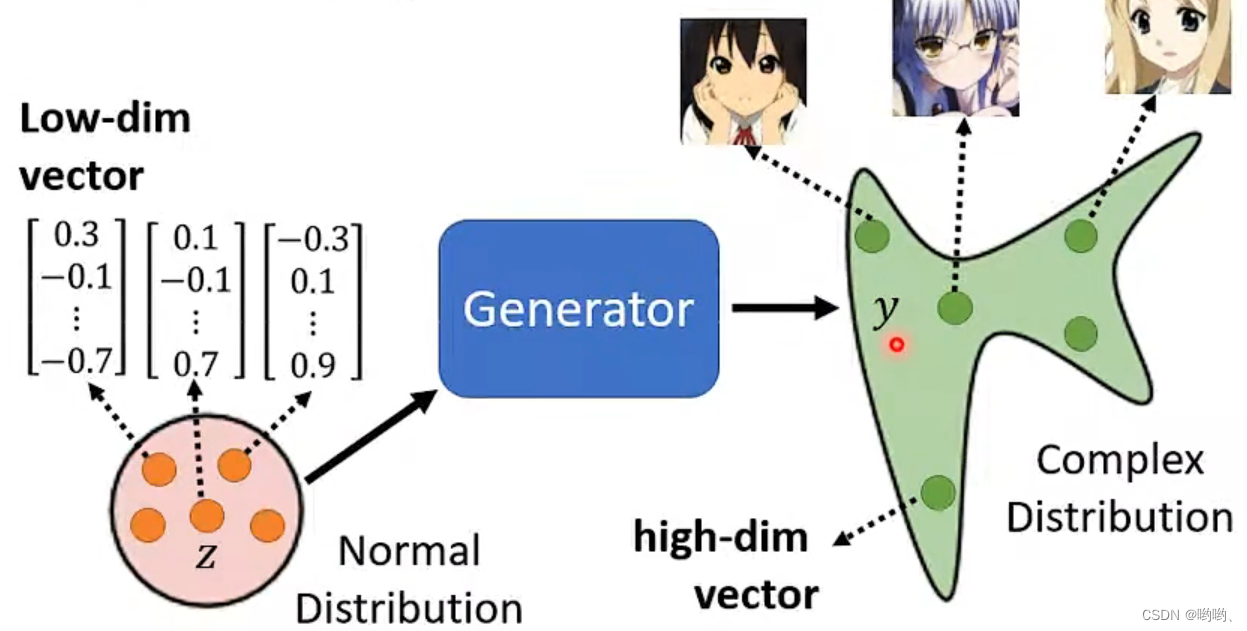
低维度向量输入–>Generation–>对应的输出(高维度)。
Discriminator(鉴别器)
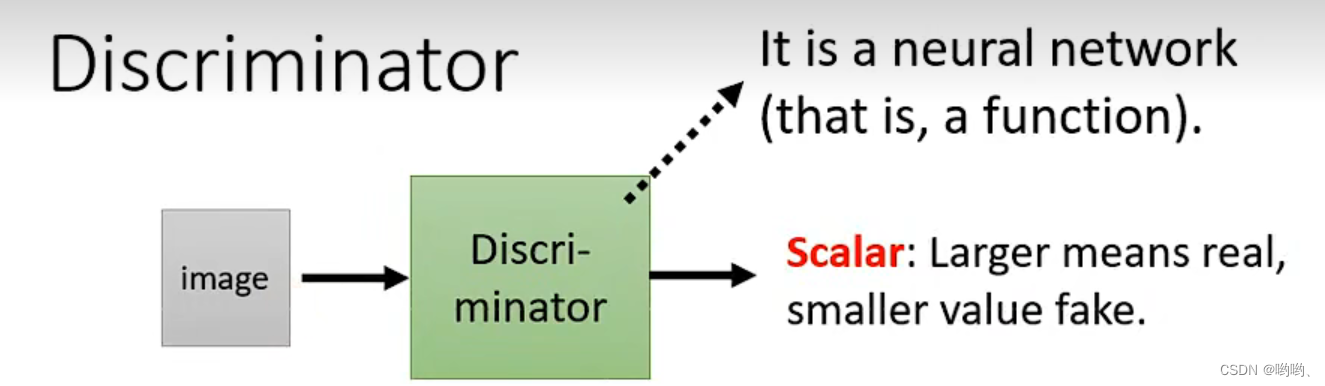
输入一个图像,输出一个scalar(标量),scalar越大说明输入的图像越真实。架构可以自己设计,如CNN、transformer
Basic idea of GAN
类似生物的进化,适者生存。
Generator:生成 Discriminator:鉴别生成的与真实的之间的差异
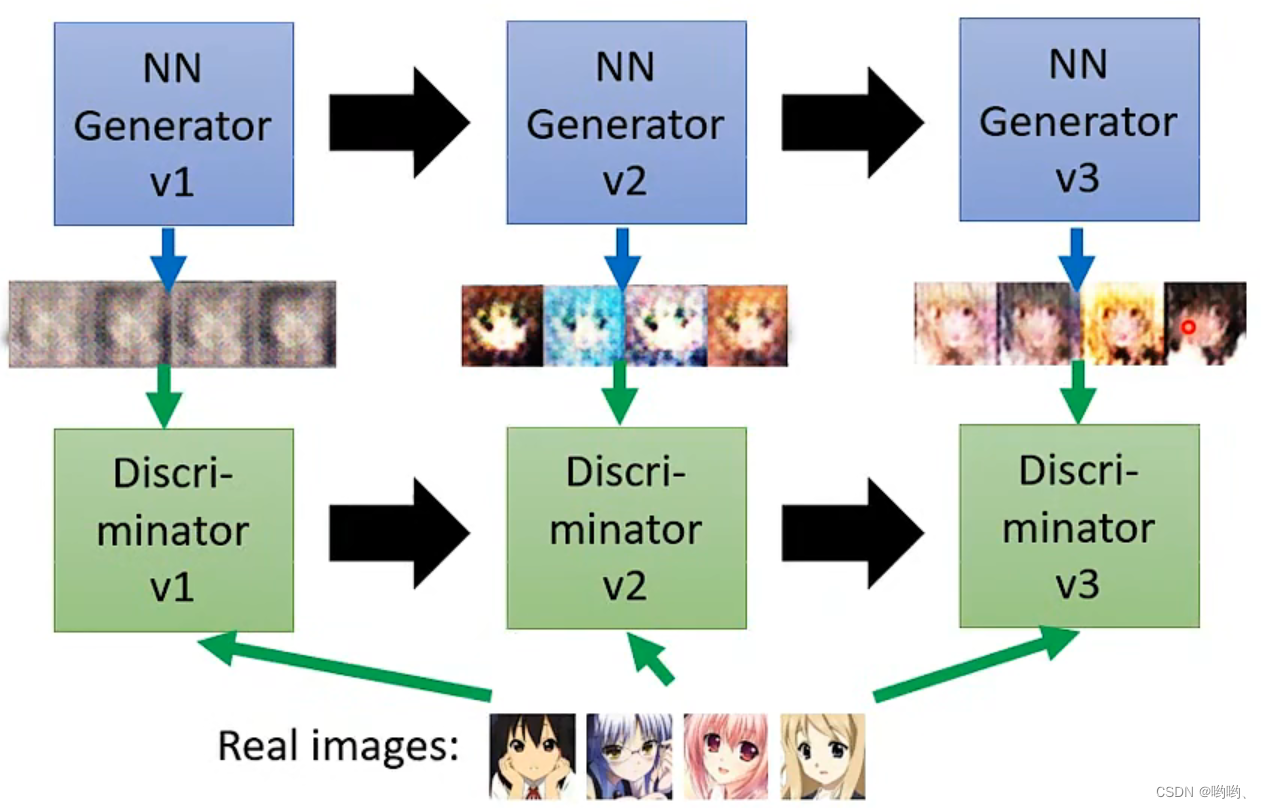
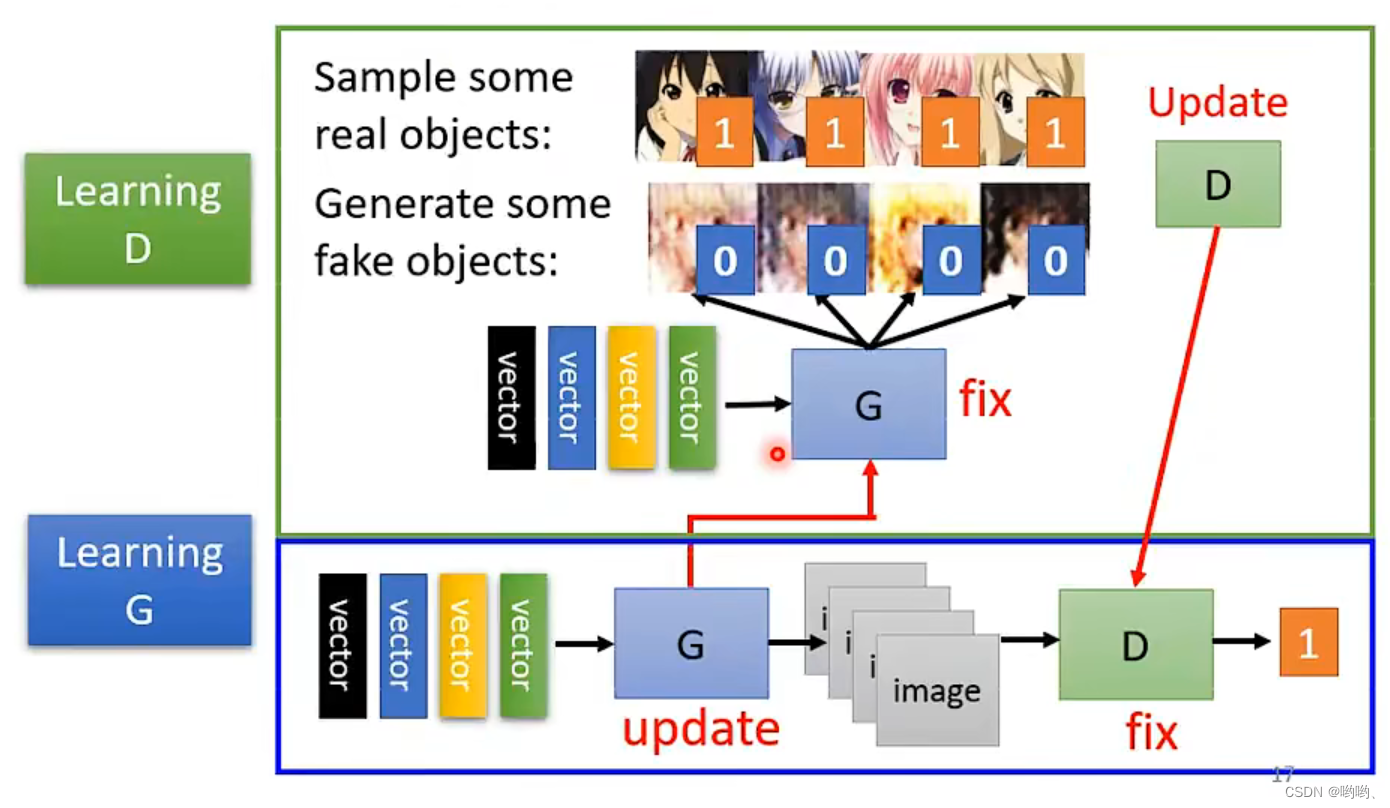
算法
- 初始化generator(G)和discriminator(D)
- 在每次训练迭代中:
-
step1:固定G,update D.找出与真实之间的差异(学会分辨)。
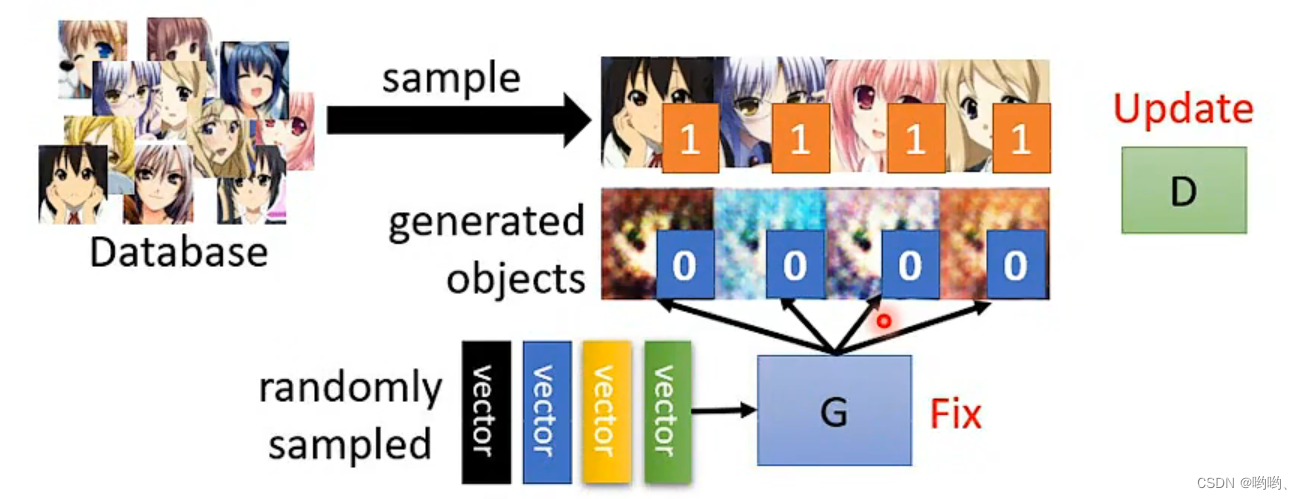
-
step2:固定D,update G。“想办法骗过D”。D打分,让输出的分数越大越好。
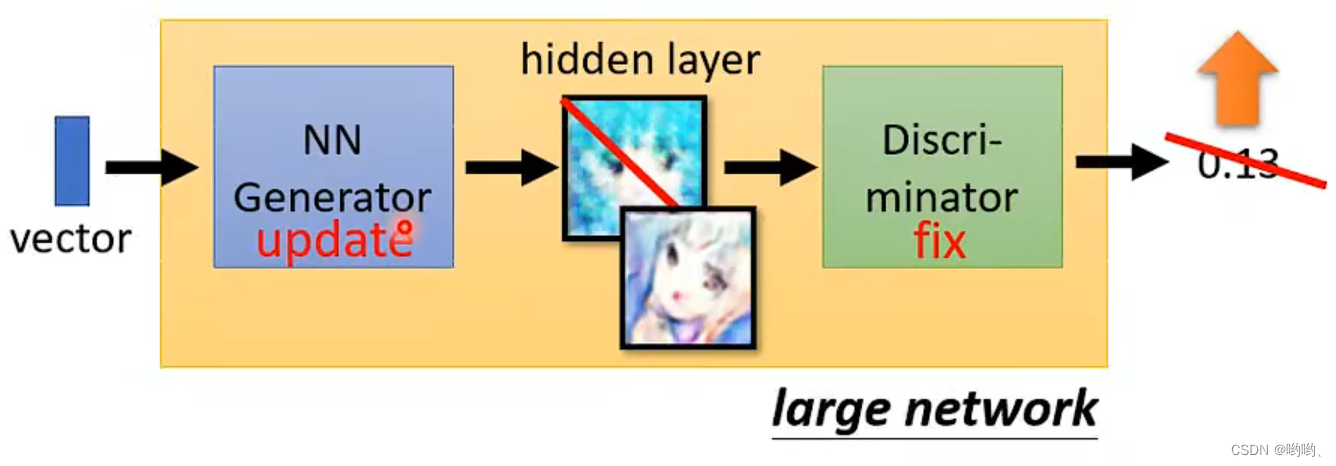
-
反复训练
GAN理论
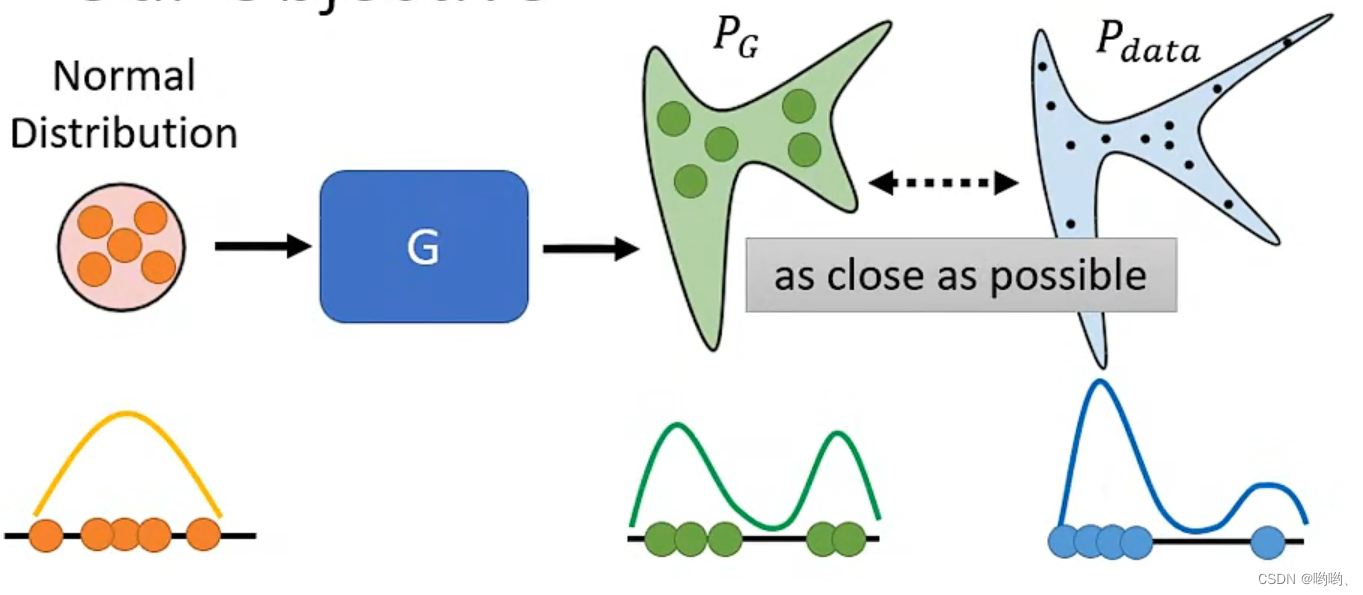
- 目标
一个一般的分布经过G,得到分布 P g P_g Pg,真正的data也形成了一个 P d a t a P_{data} Pdata,要让Pg接近Pdata。
 G
∗
=
arg
min
G
D
i
v
(
P
g
,
P
d
a
t
a
)
G^* = \arg\min_{G}Div(P_g,P_{data})
G∗=argGminDiv(Pg,Pdata)
G
∗
=
arg
min
G
D
i
v
(
P
g
,
P
d
a
t
a
)
G^* = \arg\min_{G}Div(P_g,P_{data})
G∗=argGminDiv(Pg,Pdata)
- divergence计算
将 P g P_g Pg和 P d a t a P_{data} Pdata采样出来,打分,训练Discriminator。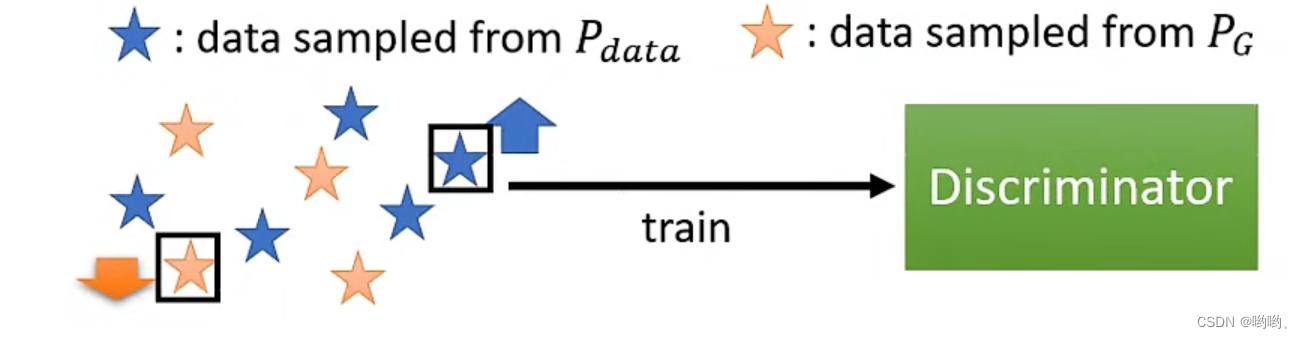
Training: D ∗ = arg max D V ( D , G ) D^* = \arg\max_{D}V(D,G) D∗=argDmaxV(D,G)
Objetive Function (for D): V ( G , D ) = E y P d a t a [ l o g D ( y ) ] + E y P G [ l o g ( 1 − D ( y ) ) ] V(G,D) = E_{y~P_{data}}[logD(y)]+E_{y~P_{G}}[log(1-D(y))] V(G,D)=Ey Pdata[logD(y)]+Ey PG[log(1−D(y))]
期望 P g P_g Pg的D(y)大, P d a t a P_{data} Pdata的D(y)小。其最大值与divergence有关,则可将 max D V ( G , D ) \max_{D}V(G,D) maxDV(G,D)替代 D i v ( P g , P d a t a ) Div(P_g,P_{data}) Div(Pg,Pdata)如下。不同的Objetive Function 有不同的divergence。
G ∗ = arg min G max D V ( G , D ) G^* = \arg\min_{G}\max_{D}V(G,D) G∗=argGminDmaxV(G,D)
Tips for GAN
JS divergence的缺点: P g P_g Pg和 P d a t a P_{data} Pdata通常重合部分很少,如果没有重叠,不管相差多少,计算结果永远为log2。
- Wasserstein distance
Wasserstein距离(也称为Earth Mover’s Distance或EMD)是一种测量两个概率分布之间距离的方法。Wasserstein距离是基于将一个概率分布转换为另一个概率分布所需的最小代价来定义的(穷举全部方法来找最小)。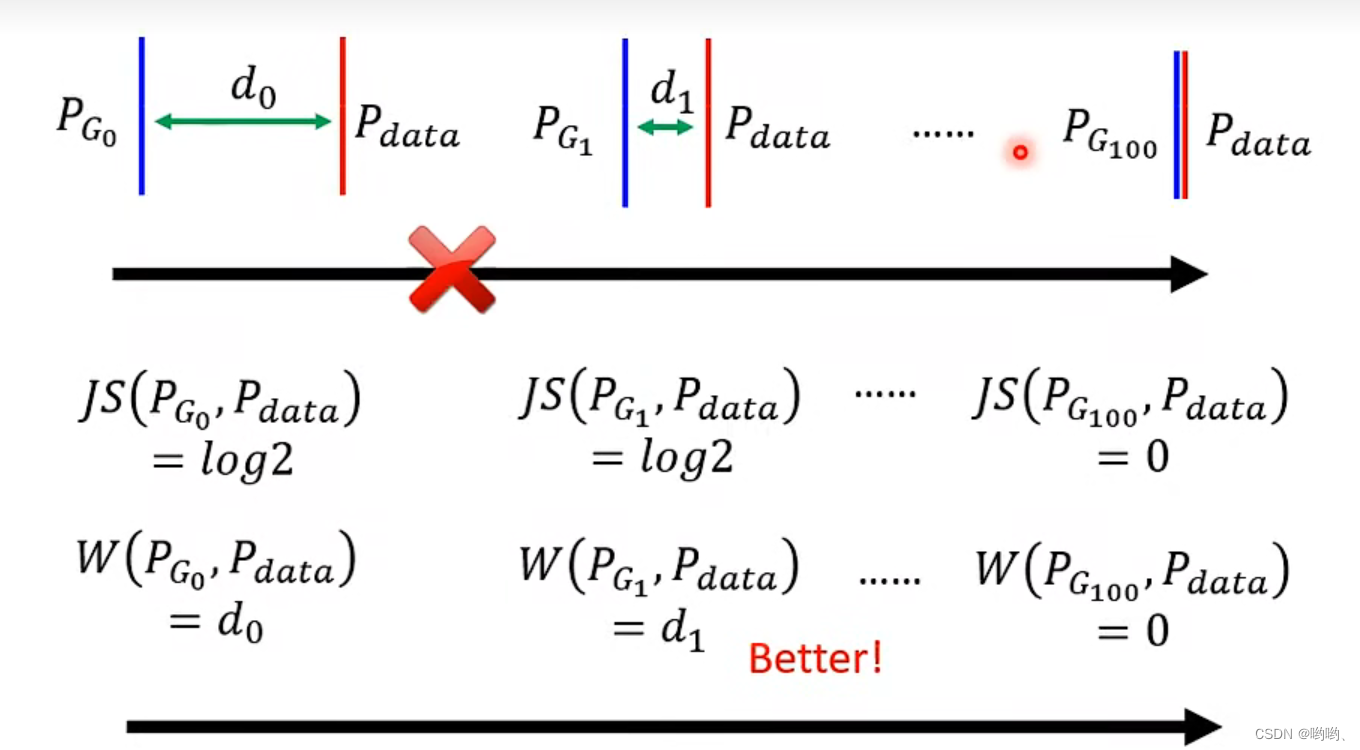
- WGAN
WGAN(Wasserstein GAN)是一种基于Wasserstein距离的生成对抗网络(GAN)的改进版本。Wasserstein距离可以更好地表示生成器和判别器之间的距离,并且有助于稳定训练过程。Wasserstein distance的计算公式:

D必须是一个足够平滑的function。可以保证D的平稳,使训练收敛。
限制方法:
- Weight
在C和-C使用weight参数,当参数更新后if w>c ,w=c;if w<-c ,w=-c。 - Gradient Penalty
Gradient Penalty旨在约束判别器的梯度,使其保持平滑,从而提高WGAN的生成效果和训练稳定性。其主要思想是在WGAN的损失函数中添加一个约束项,该项用于惩罚判别器的梯度。具体而言,该约束项是判别器输出对输入样本的梯度的范数与1之差的平方
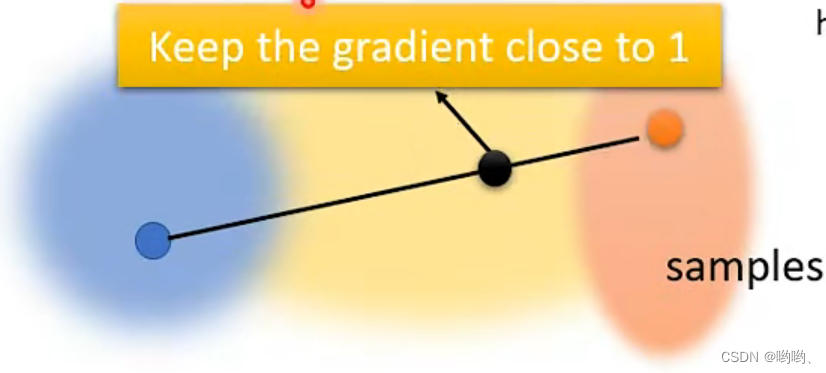
- Spectral Normalization (SNGAN)–>Keep gradient norm
"Keep gradient norm"是一种在训练神经网络时控制梯度爆炸和梯度消失的技术。在深度神经网络中,梯度爆炸和梯度消失是常见的问题,这会导致训练变得不稳定、梯度更新过大或过小,从而影响模型的性能。
"Keep gradient norm"技术的核心思想是在反向传播过程中控制梯度的大小,使其保持在一个合理的范围内。具体而言,这可以通过计算梯度的范数(即梯度的长度)来实现。如果梯度的范数超过了一个预先设定的阈值,那么就将梯度缩放到阈值范围内,以避免梯度爆炸。如果梯度的范数小于阈值,那么就不需要进行缩放,以避免梯度消失。

















 2886
2886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









