



 AttnGAN是一个基于注意力机制的生成对抗网络,它通过多阶段细化实现细粒度的文本到图像生成。模型包括注意力生成网络和深度注意力多模态相似性模型(DAMSM),后者用于计算图像与文本的细粒度匹配损失。AttnGAN在CUB和COCO数据集上的表现显著优于现有技术。
AttnGAN是一个基于注意力机制的生成对抗网络,它通过多阶段细化实现细粒度的文本到图像生成。模型包括注意力生成网络和深度注意力多模态相似性模型(DAMSM),后者用于计算图像与文本的细粒度匹配损失。AttnGAN在CUB和COCO数据集上的表现显著优于现有技术。
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
一、摘要
在本文中,我们提出了一个注意力生成对抗网络(AttnGAN),它允许注意力驱动的多阶段细化,以实现细粒度的文本到图像生成。AttnGAN利用一种新的注意力生成网络,通过关注自然语言描述中的相关词语,可以在图像的不同子区域合成细粒度的细节。此外,提出了一种深度注意力多模态相似性模型来计算细粒度的图像-文本匹配损失,用于训练生成器。所提出的AttnGAN显著优于先前的最新技术水平,在CUB数据集上将最佳报告的初始得分提高了14.14%,在更具挑战性的COCO数据集上提高了170.25%。还通过可视化AttnGAN的注意力层来执行详细分析。这是第一次表明,分层注意GAN是能够自动选择的条件,在词的水平上产生的不同部分的图像。
二、AttnGAN优势
在全局句子向量上调节GAN,单词级缺乏重要的细粒度信息,并且防止生成高质量图像。在生成复杂场景(如COCO数据集中的场景)时,这个问题会变得更加严重。为了解决这个问题,我们提出了一个注意力生成对抗网络(AttnGAN),它允许注意力驱动,多阶段细化细粒度的文本到图像生成。
三、两大核心
该模型有两个新的组件,注意力生成网络和深度注意多模态相似性模型(DAMSM)。
———在后面会重点介绍
- 注意力生成网络
开发了一种注意力机制,用于生成器通过关注与被绘制的子区域最相关的单词来绘制图像的不同子区域。除了将自然语言描述编码成全局句子向量之外,还将句子中的每个词编码成词向量。
生成网络在第一阶段利用全局句子向量生成低分辨率图像。在接下来的阶段中,它用每个子区域中的图像向量通过使用注意力层来查询词向量,以形成词上下文向量。然后,它结合区域图像向量和相应的词上下文向量,以形成一个多模态上下文向量,在此基础上生成周围的子区域中新的图像特征。这有效地产生在每个阶段具有更多细节的更高分辨率的图片。 - DAMSM
通过注意机制,DAMSM能够使用全局句子级别信息和细粒度单词级别信息来计算生成的图像与句子之间的相似性。因此,DAMSM为训练生成器提供了额外的细粒度图像-文本匹配损失。
四、架构分析
每个注意力模型自动检索条件(即,最相关的词向量),用于生成图像的不同子区域; DAMSM为生成网络提供了细粒度的图像-文本匹配损失。
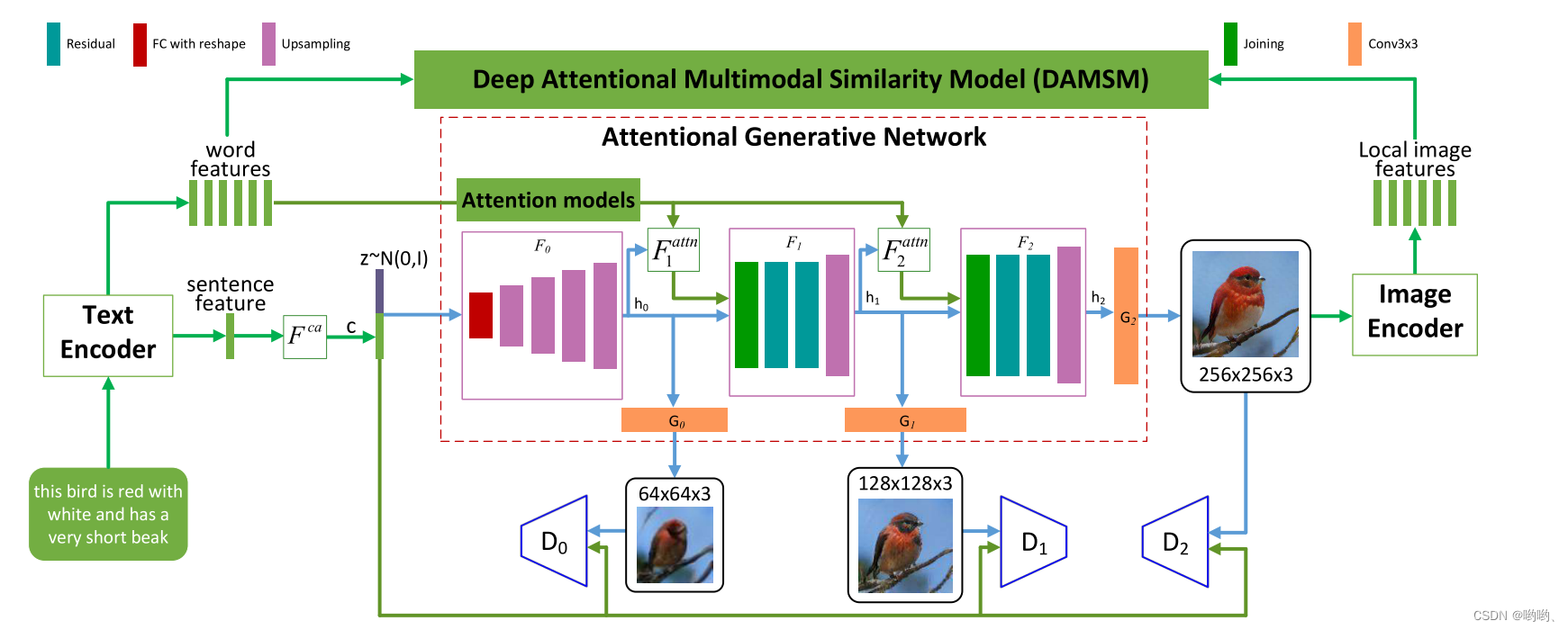
- 残差residual是指实际观测值与预测值之间的差异,通常用于评估预测模型的精度和准确性。残差连接是将网络中的某一层的输出直接与之前某一层的输入相加,从而构成一个新的输入。
- FC with Reshape,全连接层(Fully Connected Layer),为了方便网络的设计和计算,对输入数据进行了 Reshape 操作。在某些情况下,输入数据的大小可能与全连接层的输出大小不匹配,这时就需要对输入数据进行 Reshape 操作。Reshape 操作可以将输入数据的形状调整为与全连接层的输出形状相匹配,这样就可以在全连接层中使用这些数据了。
- 上采样Upsampling是指将输入数据的分辨率或尺寸增加的一种操作。上采样可以通过插值等方法将低分辨率、小尺寸的图像或数据增加到原始大小,从而提高图像质量或信息量。
- Joining连接通常指的是将两个或多个网络层或模型进行连接,以构建更复杂的网络结构或模型。这种连接操作可以通过堆叠、串联、并联等方式进行。
- Conv3*3是指卷积神经网络(Convolutional Neural Network,CNN)中使用的一种卷积核,该卷积核的大小为 3x3。具有参数较少,计算率较高,特征提取能力强的优点。
注意力生成网络
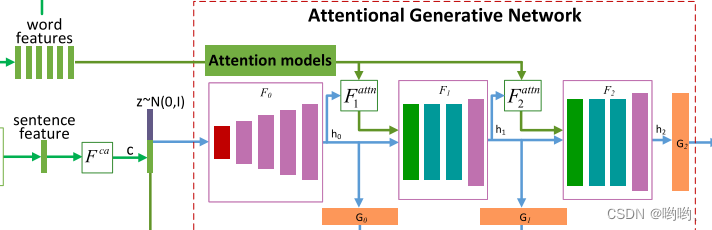
如图所示有m个生成器(
G
0
,
G
1
,
…
,
G
m
−
1
G_0,G_1,…,G_{m-1}
G0,G1,…,Gm−1),其隐藏状态(
h
0
,
…
h_0,…
h0,…)作为输入,并生成小到大尺度(
x
0
,
…
x_0,…
x0,…)。
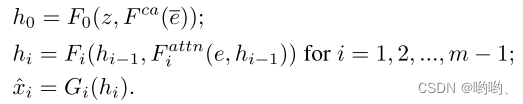
-
该式子中 z z z通常是从标准正态分布采样的噪声向量, e ‾ \overline{e} e是全局句子向量, e e e是词向量矩阵。 F c a F^{ca} Fca表示将句子向量 e e e转换为条件向量的条件增强。 F i a t t n F^{attn}_i Fiattn是AttnGAN的第 i i i阶段处提出的注意力模型。 F c a F^{ca} Fca、 F i a t t n F^{attn}_i Fiattn、 F i F_i Fi和 G i G_i Gi被建模为神经网络。
-
噪声向量 是指在GAN中被用来作为生成器网络输入的一种随机向量。
-
条件向量 是指在一些机器学习模型中,用于表示额外的条件或上下文信息的一种向量。
注意力模型 F a t t n ( e , h ) F^{attn}(e,h) Fattn(e,h)
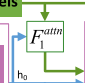
注意力模型有两个输入:单词特征
e
e
e和来自隐含层的图像特征
h
h
h。
- 首先通过添加新的感知层来将单词特征转化到图像特征的公共语义空间,即
e
′
=
U
e
e'=Ue
e′=Ue。
—>公共语义空间指的是一种在自然语言处理中应用广泛的语义表示模型,它可以将不同语言或不同模态的语言表示映射到同一个向量空间中,从而实现跨语言或跨模态的语义理解和交互。 - 然后基于图象的隐层特征 h h h为图象的每个子区域计算词的上下文向量。 h h h的每一列是图像子区域的特征向量。
- 对于第
j
j
j个子区域,其词的上下文向量是与
h
j
h_j
hj相关的词向量的动态表示,匹配最相关的单词向量来约束其生成,增加图像的细粒度细节。通过下式进行计算:
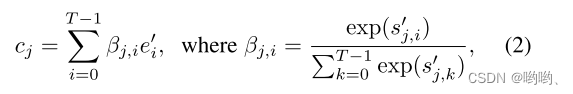
其中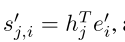 ,β
j
,
i
_{j,i}
j,i表示当生成图像的第j个子区域时模型对第i个词的权重。
,β
j
,
i
_{j,i}
j,i表示当生成图像的第j个子区域时模型对第i个词的权重。 - 最后,图像特征和相应的词上下文特征相结合生成图像,将生成的图像和句子特征输入到D中训练。
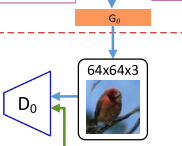
损失函数
-
为了生成具有多个级别的逼真图像,注意力生成网络的最终目标函数被定义为:
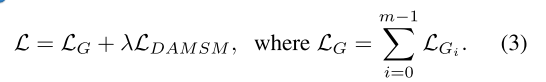
其中λ为平衡因子,用于平衡等式(2)的两项超参数。等式(3)的第一项是GAN的损失,共同近似条件和无条件分布。在AttnGAN的第i级, G i G_i Gi具有对应的 D i D_i Di。
———该部分介绍公式(3)第一项,第二项 L D A M S M L_{DAMSM} LDAMSM在后面会介绍。 -
G i G_i Gi的损失函数定义为:
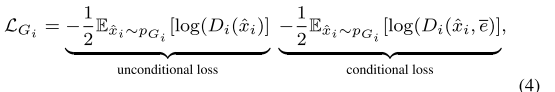
其中无条件损失(unconditional loss)确定图像是真实的的还是假的,而有条件损失(conditional loss)确定图像和句子是否匹配。 -
D i D_i Di的损失函数定义为:

其中 x i x_i xi是第i个尺度的真实图像分布 P d a t a i P_{data_i} Pdatai, x ^ \widehat{x} x 是相同尺度的 P G i P_{G_i} PGi。AttnGAN的判别器是不相交的,所以可以进行并行训练,它们每一个都专注于单个图像尺度。
DAMSM
DAMSM主要有两个神经网络,文本编码器和图像编码器。其将图像的子区域和句子中的单词映射到一个公共语义空间,从而在单词级别测量图像-文本相似度,以计算图像生成的细粒度损失。
- 文本编码器:双向长短期记忆网络(LSTM)。
- 图像编码器:将图像映射到语义向量的卷积神经网络(CNN)。
文本编码器
- 从文本描述中提取语义向量,在双向LSTM中每个单词对应两种隐藏状态,每个方向一个。
- 连接两个方向的隐藏状态来表示一个词的语义,所有词的特征矩阵用 e e e 表示。其中第i列的 e i e_i ei表示第i个单词的特征向量。 e e e的维度属于 D D D× T T T,其中 D D D是词向量的维度, T T T是个词的数量。
- 双向LSTM最后的隐藏状态被连接成全局句子向量,用 e ‾ \overline{e} e来表示,其维度属于 D D D。
图像编码器
- 该结构中CNN的中间层学习图像不同子区域的局部特征,后面层学习图像的全局特征。
- 具体来说,该论文中的图像编码器构建在ImageNet上预训练的Inception-v3模型上。首先将输入图像缩放为299×299像素。然后从从Inception-v3的“mixed_6e”层中提取局部特征矩阵 f f f, f f f维度为768×289(768×17×17)。 f f f的每一列是图像子区域的特征向量,768是局部特征的维度,289是图像中子区域的数目。
- 同时,从Inception-v3的最后一个平均池化层提取全局特征向量 f ‾ \overline{f} f,维度为2048。
- 最后,通过添加感知器层将图像特征转换为文本特征的公共语义空间。
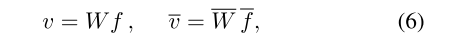
其中 v v v的维度为D×289,第i列的vi是图像第i个区域的视觉特征向量。
并且 v ‾ \overline{v} v是整个图像的全局向量,维度为D。D是多模态(即图像和文本模态)特征空间的维数。
注意力驱动的图文匹配评分(实现过程)
- 根据图像和文本之间的注意模型来衡量图像-句子对的匹配程度,首先计算相似矩阵:

其中s的维度为T×289, s j , i s_{j,i} sj,i是句子的第i个单词与图像的第j个子区域之间的点积相似度。
点积相似度:给定两个向量a和b,它们的点积相似度定义为它们的点积除以它们的模长的乘积。
a ⋅ b ∣ a ∣ ∣ b ∣ \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}||\mathbf{b}|} ∣a∣∣b∣a⋅b - 将其归一化
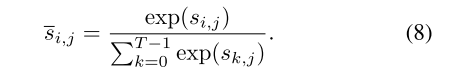
归一化(Normalization)是一种常见的数据预处理方法,用于将数据按比例缩放,使其落入特定的范围。归一化的目的是消除不同特征之间的量纲差异,以便更好地进行数据分析、建模和训练。 - 建立一个注意力模型来计算每个单词的区域上下文向量。
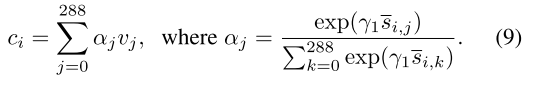
区域上下文向量ci是与句子的第i个词相关的图像的子区域的动态表示。它被计算为所有区域视觉矢量的加权和。其中γ1是一个因子,表示对图像相关子区域特征的关注度。 - 最后,使用使用ci和ei之间的余弦相似度来定义第i个词与图像之间的相关性
R ( c i , e i ) = c i T e i ∥ c i ∥ ⋅ ∥ e i ∥ R(c_i,e_i)=\frac{c^T_i e_i}{\left\|c_i\right\|\cdot\left\|e_i\right\|} R(ci,ei)=∥ci∥⋅∥ei∥ciTei - 整个图像(Q)和整个文本描述(D)之间的注意力驱动的图像-文本匹配得分为
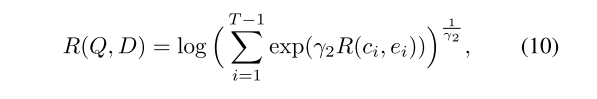
其中,γ2是确定放大最相关的词到区域上下文对的重要性的程度的因子。当γ2 →∞时, R ( Q , D ) R(Q,D) R(Q,D)近似等于 m a x i = 1 T − 1 R ( c i , e i ) max^{T-1}_{i=1}R(c_i,e_i) maxi=1T−1R(ci,ei)。
L D A M S M L_{DAMSM} LDAMSM
-
对于一批图像-句子对 { ( Q i , D i ) } i = 1 M \{(Q_i,D_i)\}^{M}_{i=1} {(Qi,Di)}i=1M,句子Di与图像Qi匹配的后验概率计算为
后验概率:指在已知某些先验概率和观察到的证据(数据)的情况下,计算某一事件或假设的概率
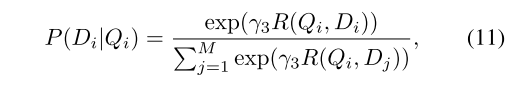
其中γ3是通过实验确定的平滑因子。 -
图像与其相应的文本描述匹配的负对数后验概率
-
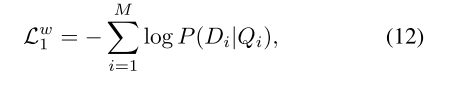
同样得
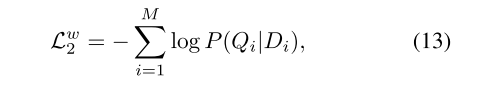
其中w代表单词(word)。 -
重新定义式子(10)
R ( Q , D ) = v ‾ T e ‾ ∥ v ‾ ∥ ⋅ ∥ e ‾ ∥ R(Q,D)=\frac{\overline{v}^T\overline{e}}{\left\|\overline{v}\right\|\cdot\left\|\overline{e}\right\|} R(Q,D)=∥v∥⋅∥e∥vTe -
使用句子向量e和全局图像向量v,以相同方法得到 L 1 s , L 2 s L^{s}_{1},L^{s}_{2} L1s,L2s,其中s代表句子(sentence)。
-
最后,得 L D A M S M L_{DAMSM} LDAMSM:
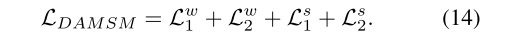
五、结论
- 注意生成对抗网络,命名为AttnGAN,提出了细粒度的文本到图像合成。我们为AttnGAN构建了一个新的注意力生成网络,通过多阶段过程生成高质量的图像。我们提出了一个深度注意多模态相似性模型来计算细粒度的图像-文本匹配损失,用于训练AttnGAN的生成器。我们的AttnGAN显著优于最先进的GAN模型,在CUB数据集上将最佳报告的初始得分提高了14.14%,在更具挑战性的COCO数据集上提高了170.25%。
- 大量的实验结果表明,所提出的注意力机制的AttnGAN,这是特别重要的复杂场景的文本到图像生成的有效性。
参考文章
Text to image论文精读 AttnGAN: Fine-Grained TexttoImage Generation with Attention

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









