




1. KKT优化视角:最小化损失函数 + 正则项 ≡ 受不等式约束的最优化(KKT)
设监督学习损失为 L(w)\mathcal{L}(w)L(w),加上正则项:
-
L2 正则化
minw L(w)+λ2∥w∥22 \min_{w}\ \mathcal L(w) + \frac{\lambda}{2} \|w\|_2^2 wmin L(w)+2λ∥w∥22 -
L1 正则化
minw L(w)+λ∥w∥1 \min_{w}\ \mathcal L(w) + \lambda \|w\|_1 wmin L(w)+λ∥w∥1
L2的例子
以平方误差为例,构造拉格朗日函数求梯度:
minw 12∥y−Xw∥22s.t.∥w∥22≤c
\min_{w}\ \frac{1}{2}\|y-Xw\|_2^2 \quad \text{s.t.} \quad \|w\|_2^2 \le c
wmin 21∥y−Xw∥22s.t.∥w∥22≤c
拉格朗日函数:
L(w,λ)=12∥y−Xw∥22+λ2(∥w∥22−c),λ≥0
\mathcal L(w,\lambda)=\frac{1}{2}\|y-Xw\|_2^2+\frac{\lambda}{2}(\|w\|_2^2-c) ,\quad \lambda \ge 0
L(w,λ)=21∥y−Xw∥22+2λ(∥w∥22−c),λ≥0
求梯度并令其为 0,整理得:
(X⊤X+λI)w=X⊤y
(X^\top X + \lambda I)w = X^\top y
(X⊤X+λI)w=X⊤y
⇒w∗=(X⊤X+λI)−1X⊤y ⇒ w^* = (X^{\top} X + \lambda I)^{-1} X^{\top} y ⇒w∗=(X⊤X+λI)−1X⊤y
可以发现,L2正则化下权重被均匀缩小,且不会变成 0。
L1的例子
推导过程省略,由于 ∣w∣∣w∣∣w∣ 在 0 点不可导,我们使用次梯度形式的KKT条件:
若 wi≠0w_i \neq 0wi=0:
(X⊤(y−Xw))i=λ sign(wi)
(X^\top (y - Xw))_i = \lambda\ \text{sign}(w_i)
(X⊤(y−Xw))i=λ sign(wi)
- 损失的梯度大小恰好抵消 L1 正则的惩罚力,该特征对优化有足够贡献故保留
若 wi=0w_i = 0wi=0:
∣(X⊤(y−Xw))i∣≤λ
|(X^\top (y - Xw))_i| \le \lambda
∣(X⊤(y−Xw))i∣≤λ
- 当某个权重为 0 时,只要损失函数对它的梯度没有超出λ\lambdaλ,就会被锁在 0
因此 L1 会选择特征,让模型更稀疏,贡献小的特征变为0。
2. 贝叶斯视角:最大后验估计(MAP)
最小化负MAP:
minw−logp(y∣X,w)−logp(w)
\min_w -\log p(y|X,w) - \log p(w)
wmin−logp(y∣X,w)−logp(w)
L2 ≡ 先验高斯分布的MAP
假设权重服从高斯分布,概率密度(取对数,取负数,去常数):
w∼N(0,σ2I)⇒−logp(w)∝12σ2∥w∥22
w \sim \mathcal N(0,\sigma^2I)
\Rightarrow
-\log p(w) \propto \frac{1}{2\sigma^2}\|w\|_2^2
w∼N(0,σ2I)⇒−logp(w)∝2σ21∥w∥22
回代MAP:
minw −logp(y∣X,w)+λ2∥w∥22
\min_{w}\ -\log p(y|X,w) + \frac{\lambda}{2} \|w\|_2^2
wmin −logp(y∣X,w)+2λ∥w∥22
其中:
λ=1σ2
\lambda=\frac{1}{\sigma^2}
λ=σ21
发现这就是L2正则化。
同时可以由高斯分布先验的特点推出:
L2正则化,平滑收缩,不稀疏。
L1 ≡ 先验拉普拉斯分布的MAP
假设权重服从拉普拉斯分布,概率密度:
w∼Laplace(0,b)⇒−logp(w)∝1b∥w∥1
w \sim Laplace(0,b)
\Rightarrow- \log p(w) \propto \frac{1}{b}\|w\|_1
w∼Laplace(0,b)⇒−logp(w)∝b1∥w∥1
回代MAP:
minw −logp(y∣X,w)+λ∥w∥1
\min_{w}\ -\log p(y|X,w) + \lambda \|w\|_1
wmin −logp(y∣X,w)+λ∥w∥1
其中:
λ=1b
\lambda=\frac{1}{b}
λ=b1
发现这就是L1正则化。
同时可以由拉普拉斯分布先验的特点观察出:
峰尖,尾厚,很多权重=0。
可以看图(来自BV1aE411L7sj):
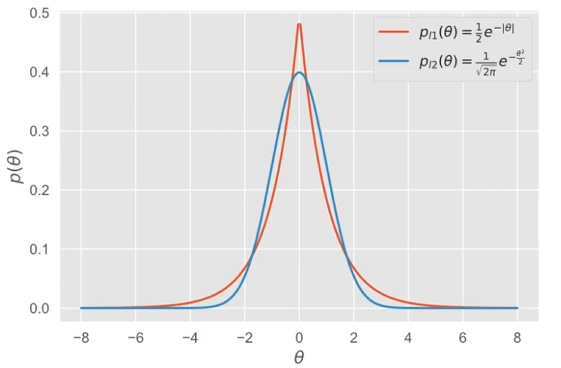
总的来说:
L1和L2正则化就是不同分布先验下的最大后验估计
3. 解空间几何视角:可行域形状决定稀疏性
假设最小化 L(w)\mathcal{L}(w)L(w) 时,等损失线是椭圆。
 (图片来自BV1Z44y147xA)
(图片来自BV1Z44y147xA)
| 方法 | 约束形状 | 结果 |
|---|---|---|
| L2 | 球形 ∥w∥2≤r\|w\|_2\le r∥w∥2≤r | 切点平滑 → 非零系数更常见 |
| L1 | 菱形 ∥w∥1≤r\|w\|_1\le r∥w∥1≤r | 尖角落在坐标轴上 → 易出现 wi=0w_i=0wi=0 |
4. 梯度下降视角:权重衰减(Weight Decay)
SGD+L2 正则化:
SGD更新:
w=w−η(∇L+λw)=(1−λη) w−η∇L
w = w-\eta(\nabla \mathcal L + \lambda w) =(1 - \lambda\eta)\,w - \eta\nabla \mathcal L
w=w−η(∇L+λw)=(1−λη)w−η∇L
每步按比例缩,一直都在将权重试图缩小到 0 ,这也是为什么L2正则化(SGD)被叫为权重衰减
注意:非SGD不等价,因为Adam这种自适应优化器会把梯度也缩放,把正则项的梯度破坏了,而SGD是每次按比例衰减,所以必须要解耦,用AdamW
L1 正则梯度(次梯度):
λ⋅sign(w) \lambda\cdot \text{sign}(w) λ⋅sign(w)
不管权重大小,常数地将权重推向 0,很小时也这样,所以作用是稀疏化而不是衰减
5. 模型复杂度视角:降低复杂度,防止过拟合
| 方法 | 对模型复杂度的影响 | 特点 |
|---|---|---|
| L2 | 连续降低复杂度,对大权重大,小权重小,不挑特征 | 稳定,平滑,抑制过拟合 |
| L1 | 直接减少维度(把权重直接变成0) | 可解释性高,特征选择,稀疏化 |
6. 实践
| 场景 | 推荐 |
|---|---|
| 高维 & 要解释性 | L1(特征选择) |
| 特征高度相关 | L2 |
| 深度学习 | L2(AdamW)+ 早停 |
(由chatgpt5辅助整理)

















 3060
3060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









