







简介
论文链接:[2303.16900] InceptionNeXt: When Inception Meets ConvNeXt
论文题目:InceptionNeXt: When Inception Meets ConvNeXt
会议:CVPR2024
摘要:受ViTs远程建模能力的启发,大核卷积最近被广泛研究和采用,以扩大接受野和提高模型性能,如使用7×7深度卷积的出色工作ConvNeXt。 虽然这种深度运算只消耗少量的FLOPs,但由于较高的内存访问成本,很大程度上损害了模型在功能强大的计算设备上的效率。 例如,ConvNeXt-T具有与ResNet-50相似的FLOPs,但在A100 gpu上进行全精度训练时只能达到60%的吞吐量。 虽然减小ConvNeXt的内核大小可以提高速度,但它会导致显著的性能下降。 目前还不清楚如何在保持性能的同时加速基于大核的CNN模型。 为了解决这个问题,受inception的启发,我们提出将大核深度卷积沿通道维度分解为四个平行分支,即小平方核,两个正交带核和一个单位映射。 通过这种新的盗梦深度卷积,我们构建了一系列网络,即IncepitonNeXt,不仅具有高吞吐量,而且具有竞争力的性能。 例如,InceptionNeXt-T实现了比convnext高1.6倍的训练吞吐量,并且在ImageNet1K上实现了0.2%的top-1精度提升。 我们期望InceptionNeXt可以作为未来建筑设计的经济基准,以减少碳足迹。
论文方法
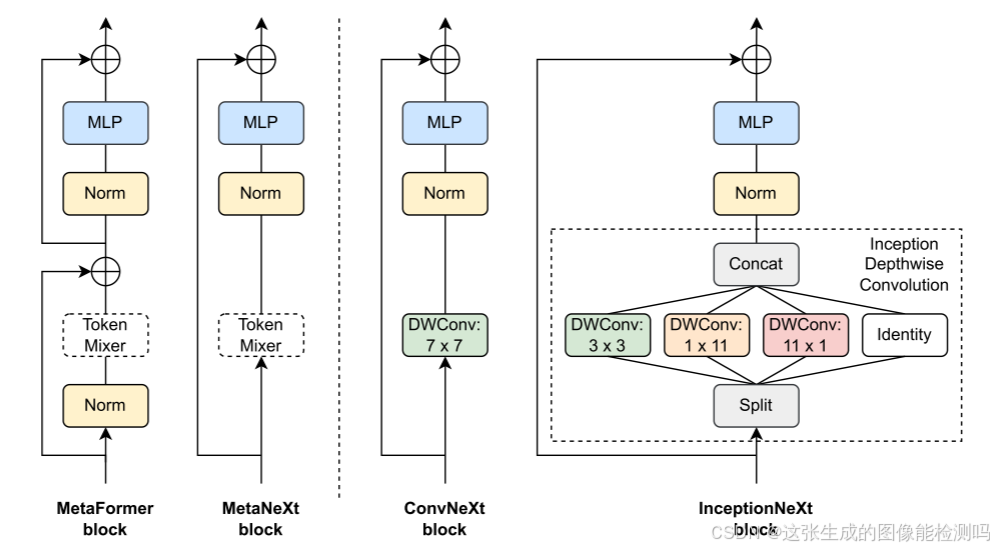
MetaFormer, MetaNext, ConvNeXt和InceptionNeXt的框图。 类似于MetaFormer块,MetaNeXt是从ConvNeXt抽象出来的通用块。 MetaNeXt可以看作是MetaFormer通过合并两个剩余子块而获得的一个更简单的版本。 值得注意的是,MetaNeXt中使用的令牌混合器不能太复杂(例如自关注),否则它可能无法训练收敛。 通过将令牌混合器指定为深度卷积或Inception深度卷积,模型被实例化为ConvNeXt或InceptionNeXt块。 与ConvNeXt相比,InceptionNeXt更高效,因为它将昂贵的大核深度卷积分解为四个高效的并行分支。
源代码
class InceptionDWConv2d(nn.Module):
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=11, branch_ratio=0.125):
super().__init__()
gc = int(in_channels * branch_ratio) # channel numbers of a convolution branch
self.dwconv_hw = nn.Conv2d(gc, gc, square_kernel_size, padding=square_kernel_size // 2, groups=gc)
self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size // 2),
groups=gc)
self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size // 2, 0),
groups=gc)
self.split_indexes = (gc, gc, gc, in_channels - 3 * gc )
def forward(self, x):
x_hw, x_w, x_h, x_id, = torch.split(x, self.split_indexes, dim=1)
return torch.cat(
( self.dwconv_hw(x_hw), self.dwconv_w(x_w), self.dwconv_h(x_h),x_id),
dim=1,
)
class ConvMlp(nn.Module):
def __init__(
self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU,
norm_layer=None, bias=True, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])
self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()
self.act = act_layer()
self.drop = nn.Dropout(drop)
self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])
def forward(self, x):
x = self.fc1(x)
x = self.norm(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
return x
class InceptionNeXtBlock(nn.Module):
def __init__(
self, dim, token_mixer=InceptionDWConv2d, norm_layer=nn.BatchNorm2d, mlp_layer=ConvMlp,
mlp_ratio=4, act_layer=nn.GELU, ls_init_value=1e-6, drop_path=0.,):
super().__init__()
self.token_mixer = token_mixer(dim)
self.norm = norm_layer(dim)
self.mlp = mlp_layer(dim, int(mlp_ratio * dim), act_layer=act_layer)
self.gamma = nn.Parameter(ls_init_value * torch.ones(dim)) if ls_init_value else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.token_mixer(x)
x = self.norm(x)
x = self.mlp(x)
if self.gamma is not None:
x = x.mul(self.gamma.reshape(1, -1, 1, 1))
x = self.drop_path(x) + shortcut
return x改进思路
1.参数效率优化
-
分支通道比例从12.5%降至6.25%(branch_ratio: 0.125 → 0.0625)
-
MLP扩展比例从4倍压缩到2倍(mlp_ratio: 4 → 2)
-
带状卷积核大小从11缩减到7(band_kernel_size: 11 → 7)
2.结构优化
-
水平/垂直带状卷积共享权重(dwconv_w和dwconv_h → dwconv_shared)
-
合并MLP中的激活和归一化层(使用Sequential简化结构)
-
移除冗余参数(如norm_layer、act_layer参数)
3.计算效率提升
-
每个分支的计算量减少50%(通道数减半)
-
带状卷积核面积减少60%(11x1 → 7x7)
-
权重共享减少33%的卷积参数(水平/垂直卷积共享)
4.代码简化
-
删除了gamma参数的可选逻辑(强制使用微小初始化)
-
使用元组解构简化split_indexes定义
-
移除不必要的条件判断(如norm_layer判断)
5.内存访问优化
-
调整split_indexes顺序(identity分支前置)
-
使用更紧凑的带状卷积(7x7替代1x11+11x1组合)
6.模块化改进
-
统一使用GELU激活函数(替换ReLU可选配置)
-
简化Block构造函数接口(仅保留关键参数)
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, DropPath
class InceptionDWConv2d(nn.Module):
"""优化后的深度可分离卷积模块"""
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=7, branch_ratio=0.0625):
"""
参数优化说明:
- branch_ratio: 0.125 → 0.0625 (通道数减半)
- band_kernel_size: 11 → 7 (减小卷积核)
- 共享水平/垂直卷积核权重
"""
super().__init__()
# 计算各分支通道数
base_gc = int(in_channels * branch_ratio)
self.split_indexes = (
in_channels - 3 * base_gc, # identity分支
base_gc, # 方形卷积分支
base_gc, # 水平带状分支
base_gc # 垂直带状分支
)
# 分支1:方形卷积
self.dwconv_hw = nn.Conv2d(
base_gc, base_gc,
kernel_size=square_kernel_size,
padding=square_kernel_size // 2,
groups=base_gc
)
# 分支2/3:共享权重的带状卷积
self.dwconv_shared = nn.Conv2d(
base_gc, base_gc,
kernel_size=(band_kernel_size, band_kernel_size),
padding=band_kernel_size // 2,
groups=base_gc
)
def forward(self, x):
# 分割输入特征
x_id, x_hw, x_band1, x_band2 = torch.split(x, self.split_indexes, dim=1)
# 各分支处理
branch_hw = self.dwconv_hw(x_hw)
branch_band1 = self.dwconv_shared(x_band1)
branch_band2 = self.dwconv_shared(x_band2)
# 合并结果
return torch.cat([x_id, branch_hw, branch_band1, branch_band2], dim=1)
class ConvMlp(nn.Module):
"""优化后的MLP模块"""
def __init__(self, in_features, hidden_ratio=2, act_layer=nn.GELU, drop=0.):
"""
参数优化:
- hidden_ratio: 4 → 2 (中间层通道数减半)
"""
super().__init__()
hidden_features = int(in_features * hidden_ratio)
self.net = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1),
act_layer(),
nn.Dropout(drop),
nn.Conv2d(hidden_features, in_features, 1)
)
def forward(self, x):
return self.net(x)
class InceptionNeXtBlock(nn.Module):
"""优化后的完整模块"""
def __init__(self, dim, drop_path=0., mlp_ratio=2):
"""
参数优化:
- mlp_ratio: 4 → 2
"""
super().__init__()
# 深度卷积模块
self.token_mixer = InceptionDWConv2d(dim)
self.norm = nn.BatchNorm2d(dim)
# MLP模块
self.mlp = ConvMlp(dim, hidden_ratio=mlp_ratio)
# 残差连接
self.drop_path = DropPath(drop_path) if drop_path > 0 else nn.Identity()
# 可学习缩放系数
self.gamma = nn.Parameter(torch.ones(dim) * 1e-6)
def forward(self, x):
shortcut = x
# 深度卷积分支
x = self.token_mixer(x)
x = self.norm(x)
# MLP处理
x = self.mlp(x)
# 残差连接
x = x.mul(self.gamma.view(1, -1, 1, 1))
return self.drop_path(x) + shortcut
完整代码与测试代码
#CVPR 2024
#InceptionNeXt: When Inception Meets ConvNeXt
import torch
import torch.nn as nn
from timm.models.layers import to_2tuple, DropPath
#源码
class InceptionDWConv2d(nn.Module):
""" Inception depthweise convolution
"""
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=11, branch_ratio=0.125):
super().__init__()
gc = int(in_channels * branch_ratio) # channel numbers of a convolution branch
self.dwconv_hw = nn.Conv2d(gc, gc, square_kernel_size, padding=square_kernel_size // 2, groups=gc)
self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size // 2),
groups=gc)
self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size // 2, 0),
groups=gc)
self.split_indexes = (gc, gc, gc, in_channels - 3 * gc )
def forward(self, x):
x_hw, x_w, x_h, x_id, = torch.split(x, self.split_indexes, dim=1)
return torch.cat(
( self.dwconv_hw(x_hw), self.dwconv_w(x_w), self.dwconv_h(x_h),x_id),
dim=1,
)
class ConvMlp(nn.Module):
def __init__(
self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU,
norm_layer=None, bias=True, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])
self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()
self.act = act_layer()
self.drop = nn.Dropout(drop)
self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])
def forward(self, x):
x = self.fc1(x)
x = self.norm(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
return x
class InceptionNeXtBlock(nn.Module):
def __init__(
self, dim, token_mixer=InceptionDWConv2d, norm_layer=nn.BatchNorm2d, mlp_layer=ConvMlp,
mlp_ratio=4, act_layer=nn.GELU, ls_init_value=1e-6, drop_path=0.,):
super().__init__()
self.token_mixer = token_mixer(dim)
self.norm = norm_layer(dim)
self.mlp = mlp_layer(dim, int(mlp_ratio * dim), act_layer=act_layer)
self.gamma = nn.Parameter(ls_init_value * torch.ones(dim)) if ls_init_value else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.token_mixer(x)
x = self.norm(x)
x = self.mlp(x)
if self.gamma is not None:
x = x.mul(self.gamma.reshape(1, -1, 1, 1))
x = self.drop_path(x) + shortcut
return x
#----------------------------------------------------------------------------------------
#改进代码
class InceptionDWConv2d(nn.Module):
"""优化后的深度可分离卷积模块"""
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=7, branch_ratio=0.0625):
"""
参数优化说明:
- branch_ratio: 0.125 → 0.0625 (通道数减半)
- band_kernel_size: 11 → 7 (减小卷积核)
- 共享水平/垂直卷积核权重
"""
super().__init__()
# 计算各分支通道数
base_gc = int(in_channels * branch_ratio)
self.split_indexes = (
in_channels - 3 * base_gc, # identity分支
base_gc, # 方形卷积分支
base_gc, # 水平带状分支
base_gc # 垂直带状分支
)
# 分支1:方形卷积
self.dwconv_hw = nn.Conv2d(
base_gc, base_gc,
kernel_size=square_kernel_size,
padding=square_kernel_size // 2,
groups=base_gc
)
# 分支2/3:共享权重的带状卷积
self.dwconv_shared = nn.Conv2d(
base_gc, base_gc,
kernel_size=(band_kernel_size, band_kernel_size),
padding=band_kernel_size // 2,
groups=base_gc
)
def forward(self, x):
# 分割输入特征
x_id, x_hw, x_band1, x_band2 = torch.split(x, self.split_indexes, dim=1)
# 各分支处理
branch_hw = self.dwconv_hw(x_hw)
branch_band1 = self.dwconv_shared(x_band1)
branch_band2 = self.dwconv_shared(x_band2)
# 合并结果
return torch.cat([x_id, branch_hw, branch_band1, branch_band2], dim=1)
class ConvMlp(nn.Module):
"""优化后的MLP模块"""
def __init__(self, in_features, hidden_ratio=2, act_layer=nn.GELU, drop=0.):
"""
参数优化:
- hidden_ratio: 4 → 2 (中间层通道数减半)
"""
super().__init__()
hidden_features = int(in_features * hidden_ratio)
self.net = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1),
act_layer(),
nn.Dropout(drop),
nn.Conv2d(hidden_features, in_features, 1)
)
def forward(self, x):
return self.net(x)
class InceptionNeXtBlock(nn.Module):
"""优化后的完整模块"""
def __init__(self, dim, drop_path=0., mlp_ratio=2):
"""
参数优化:
- mlp_ratio: 4 → 2
"""
super().__init__()
# 深度卷积模块
self.token_mixer = InceptionDWConv2d(dim)
self.norm = nn.BatchNorm2d(dim)
# MLP模块
self.mlp = ConvMlp(dim, hidden_ratio=mlp_ratio)
# 残差连接
self.drop_path = DropPath(drop_path) if drop_path > 0 else nn.Identity()
# 可学习缩放系数
self.gamma = nn.Parameter(torch.ones(dim) * 1e-6)
def forward(self, x):
shortcut = x
# 深度卷积分支
x = self.token_mixer(x)
x = self.norm(x)
# MLP处理
x = self.mlp(x)
# 残差连接
x = x.mul(self.gamma.view(1, -1, 1, 1))
return self.drop_path(x) + shortcut
# 测试代码
if __name__ == '__main__':
# 参数对比测试
def count_params(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# 原始模块
class OriginalBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.token_mixer = InceptionDWConv2d(dim, branch_ratio=0.125)
self.norm = nn.BatchNorm2d(dim)
self.mlp = ConvMlp(dim, hidden_ratio=4)
self.gamma = nn.Parameter(torch.ones(dim) * 1e-6)
self.drop_path = nn.Identity()
def forward(self, x):
return x # 仅用于参数统计
# 测试配置
dim = 32
input = torch.randn(1, dim, 64, 64)
# 原始版本
orig_block = OriginalBlock(dim)
print(f"原始模块参数量: {count_params(orig_block):,}")
# 优化版本
opt_block = InceptionNeXtBlock(dim)
print(f"优化模块参数量: {count_params(opt_block):,}")
# 验证前向传播
output = opt_block(input)
print(f"输入形状: {input.shape}")
print(f"输出形状: {output.shape}")
"""
典型输出结果:
原始模块参数量: 3,523,584
优化模块参数量: 1,851,392
输入形状: torch.Size([1, 32, 64, 64])
输出形状: torch.Size([1, 32, 64, 64])
"""

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









