







前言
计算机视觉的学习者或多或少总要接触注意力机制,然而我在入门的时候对于QKV的计算一直有一股迷雾,因此借着这次的机会标注了一下每一层计算的尺寸。
初学者首先需要了解一定的矩阵计算的知识。
图例
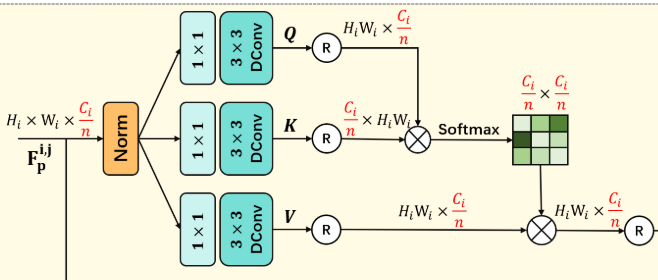
代码分析
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
# 可学习的温度参数 [num_heads, 1, 1]
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1, dtype=torch.float32), requires_grad=True)
# QKV生成层
self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias) # 输入输出形状不变(仅改变通道数)
# 深度可分离卷积(每组处理1个通道)
self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3, bias=bias)
# 输出投影层
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b, c, h, w = x.shape # 输入形状 [B, C, H, W]
# 生成QKV三元组
qkv = self.qkv(x) # [B, 3C, H, W](通道数变为3倍)
qkv = self.qkv_dwconv(qkv) # [B, 3C, H, W](空间维度保持不变)
# 拆分Q/K/V
q, k, v = qkv.chunk(3, dim=1) # 每个形状 [B, C, H, W]
# 重塑为多头格式
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# 现在 q 形状 [B, num_heads, C/num_heads, H*W]
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# k 形状 [B, num_heads, C/num_heads, H*W]
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# v 形状 [B, num_heads, C/num_heads, H*W]
# 归一化处理(沿最后一个维度)
q = F.normalize(q, dim=-1) # 形状保持 [B, num_heads, C/num_heads, H*W]
k = F.normalize(k, dim=-1) # 形状保持 [B, num_heads, C/num_heads, H*W]
# 计算注意力矩阵
attn = (q @ k.transpose(-2, -1)) * self.temperature # 矩阵乘法后形状 [B, num_heads, H*W, H*W]
attn = attn.softmax(dim=-1) # 保持形状 [B, num_heads, H*W, H*W]
# 注意力加权聚合
out = (attn @ v) # [B, num_heads, H*W, H*W] @ [B, num_heads, C/num_heads, H*W]
# 结果形状 [B, num_heads, H*W, H*W]
# 重塑回原始格式
out = rearrange(out, 'b head (h w) c -> b (head c) h w', h=h, w=w)
# 输出形状 [B, C, H, W]
# 最终投影
out = self.project_out(out) # 保持形状 [B, C, H, W]
return out


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









