




视频讲解1:Bilibili视频讲解
视频讲解2:https://www.douyin.com/video/7588784970366340398
论文下载:https://arxiv.org/abs/2202.04200
代码下载:https://github.com/dome272/MaskGIT-pytorch
论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)
论文Generative Adversarial Text to Image Synthesis详解
论文DF-GAN: ASimple and Effective Baseline for Text-to-Image Synthesis详解
论文StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks详解
论文HDGAN(Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network)详解
论文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks详解
论文MirrorGAN: Learning Text-to-image Generation by Redescription详解
基于GAN的文生图(DM-GAN:Dynamic MemoryGenerative Adversarial Networks for Text-to-Image Synthesis)
基于监督对比学习的统一图像生成框架(A Framework For Image Synthesis Using Supervised Contrastive Learning)
基于GAN的文生图算法详解(Text to Image Generation with Semantic-Spatial Aware GAN)
基于GAN的文生图算法详解ControlGAN(Controllable Text-to-Image Generation)
StyleGAN-T文生图算法详解(Unlocking the Power of GANs forFast Large-Scale Text-to-Image Synthe)
论文VQ-GAN(Taming Transformers for High-Resolution Image Synthesis)高分辨图像生成讲解(PyTorch)
论文Neural Discrete Representation Learning(VQ-VAE)详解(PyTorch)
论文VQ-VAE-2(Generating Diverse High-Fidelity Images with VQ-VAE-2)详解(PyTorch)
本文提出了一种基于双向Transformer和掩码预测的高效图像生成方法。通过掩码视觉token建模(MVTM)训练双向注意力模型,并采用迭代并行解码策略,解决了传统自回归Transformer生成效率低的问题。创新性地设计了余弦掩码调度函数和置信度筛选机制,仅需8-12步即可生成高质量图像,比自回归方法加速64倍。实验表明,该方法在ImageNet 256×256上FID降至6.18,IS提升至182.1。同时展示了该方法在图像编辑任务中的扩展性,无需修改架构即可实现类条件编辑、图像修复等任务。
目录

注:图像外推(Image Extrapolation)是一种图像生成技术,旨在从已知的图像区域推断和生成未知的外部区域,扩展图像的边界和内容。与图像补全(inpainting)通常处理内部缺失不同,外推主要关注向外扩展。
现有方法局限性
1.自回归Transformer的序列生成效率低
问题:传统生成式Transformer(如VQGAN、ImageGPT)将图像视为一维序列,按光栅扫描顺序(从左到右、逐行)逐token生成。
局限性:
2.GAN模型的固有缺陷
3. 两阶段生成框架的瓶颈
提出的方法

1.双向Transformer与掩码预测
训练阶段:采用掩码视觉token建模(MVTM),随机掩码部分token后通过双向注意力预测被掩码内容,学习全局上下文依赖。
推理阶段:提出迭代并行解码,从全掩码开始,每步并行预测所有token,仅保留高置信度结果,逐步细化生成。
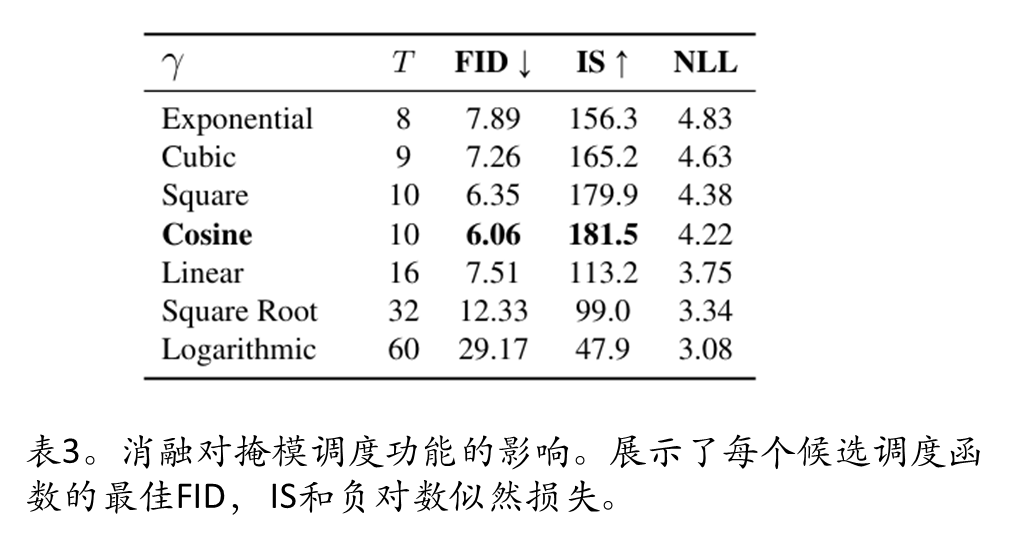
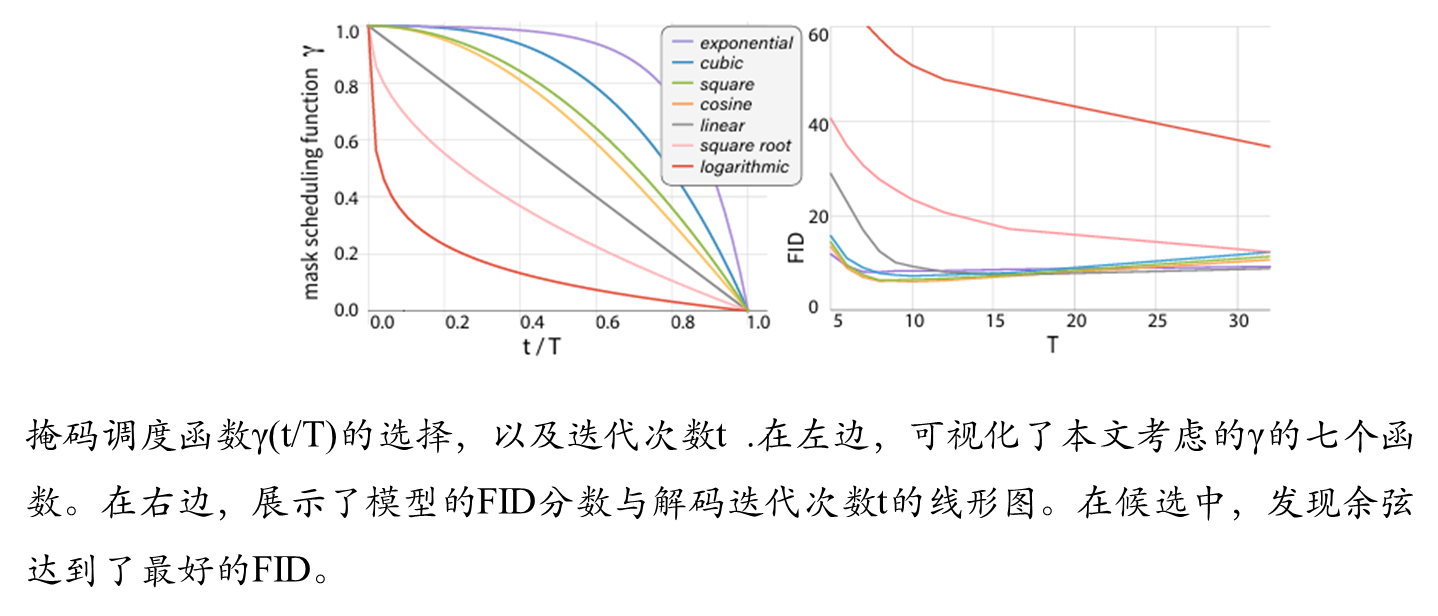
2.掩码调度函数(Mask Scheduling):
提出余弦调度函数(Concave类),在解码初期掩码率高(如95%),后期快速降低,符合“从粗到细”生成逻辑。
相比线性/凸函数,余弦调度在FID和IS指标上最优。
置信度筛选机制:每步根据预测置信度动态掩码低置信度token,避免错误累积。
3.高效性与质量提升
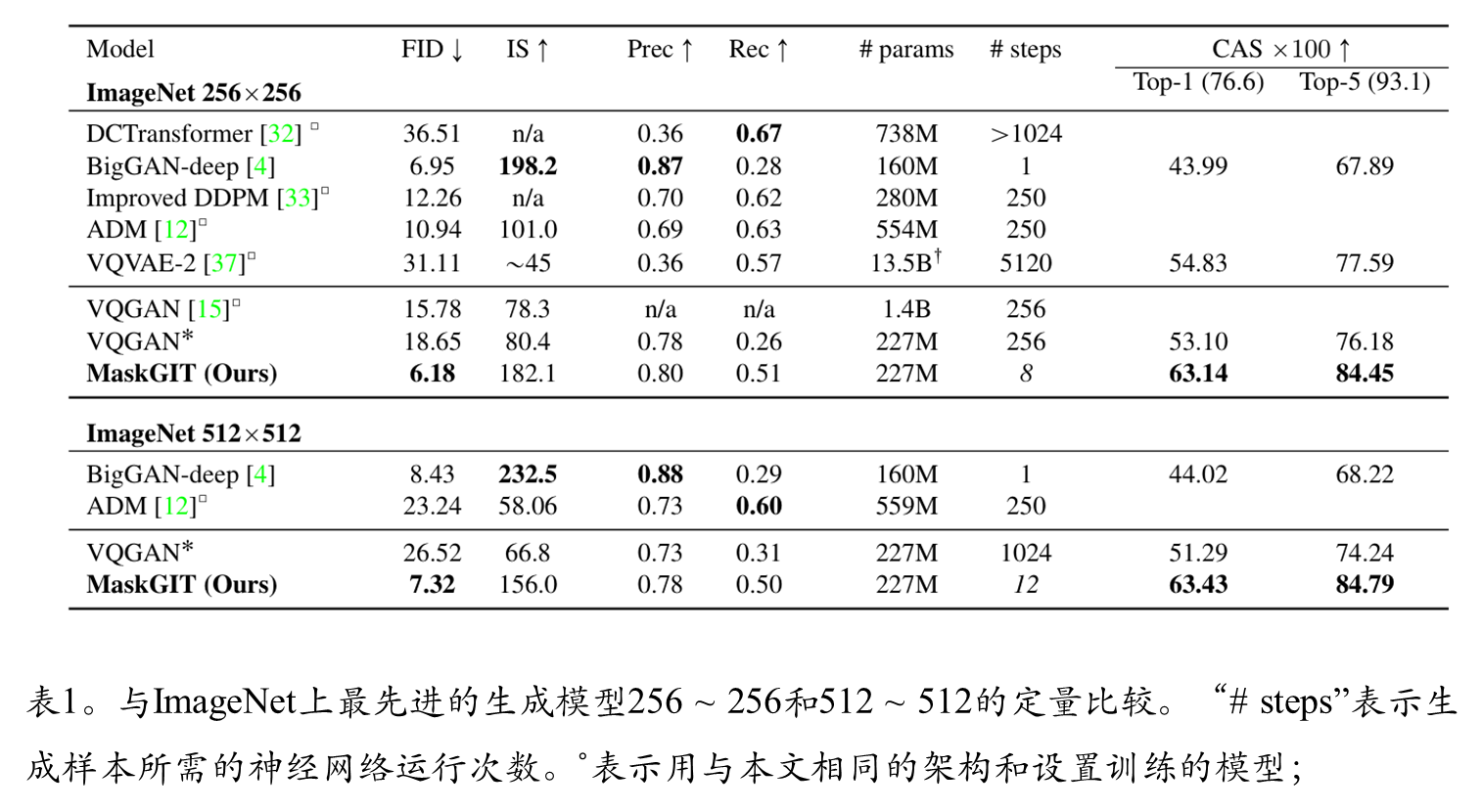
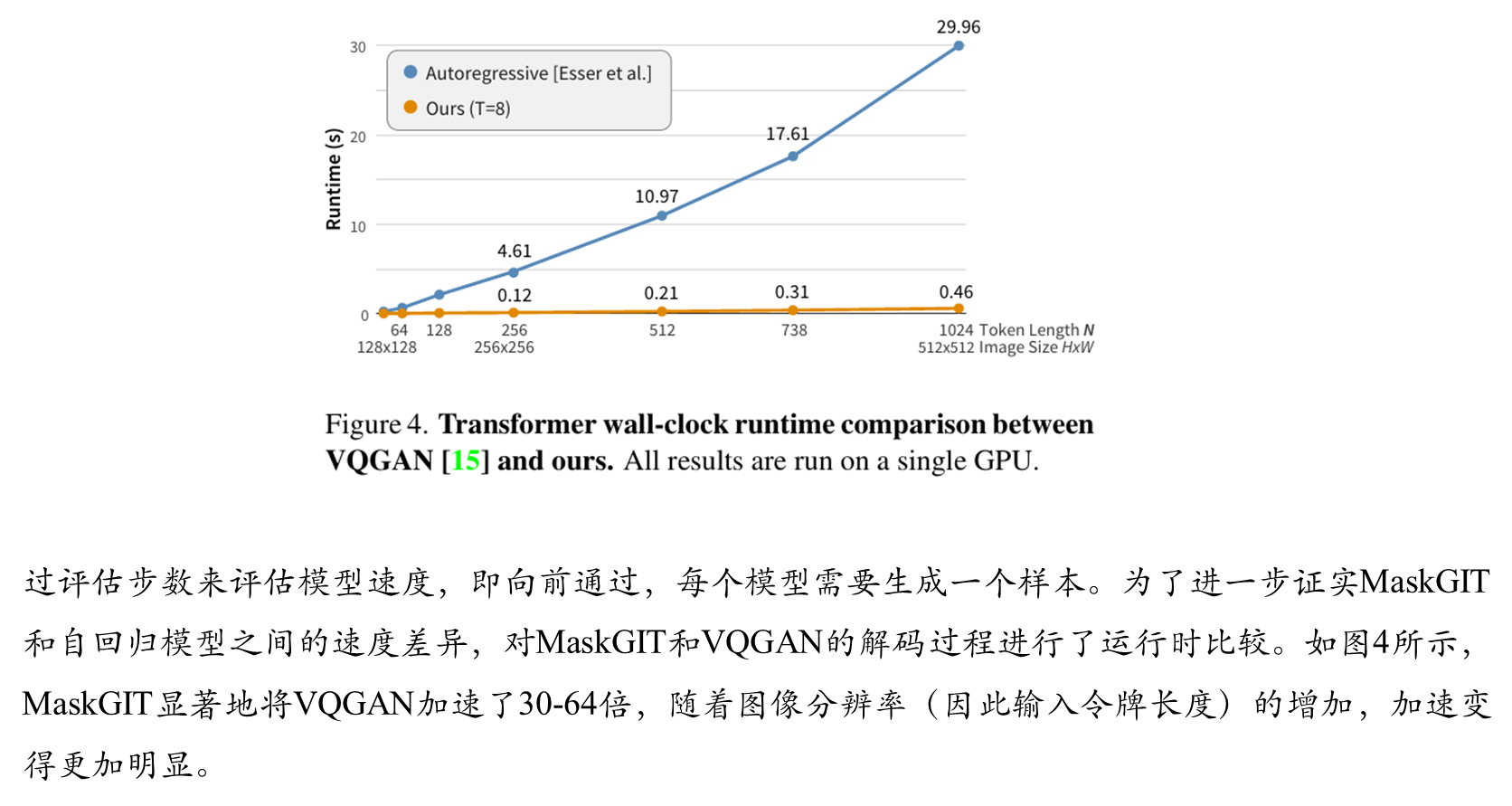
生成速度:仅需8–12步生成完整图像,比自回归方法加速最高64倍。
质量指标:在ImageNet 256×256上,FID降至6.18(VQGAN为15.78),IS提升至182.1。
4.多样性优势:通过CAS和Precision/Recall指标验证,生成样本覆盖更广的分布。1.
5.多任务扩展性
具体方法
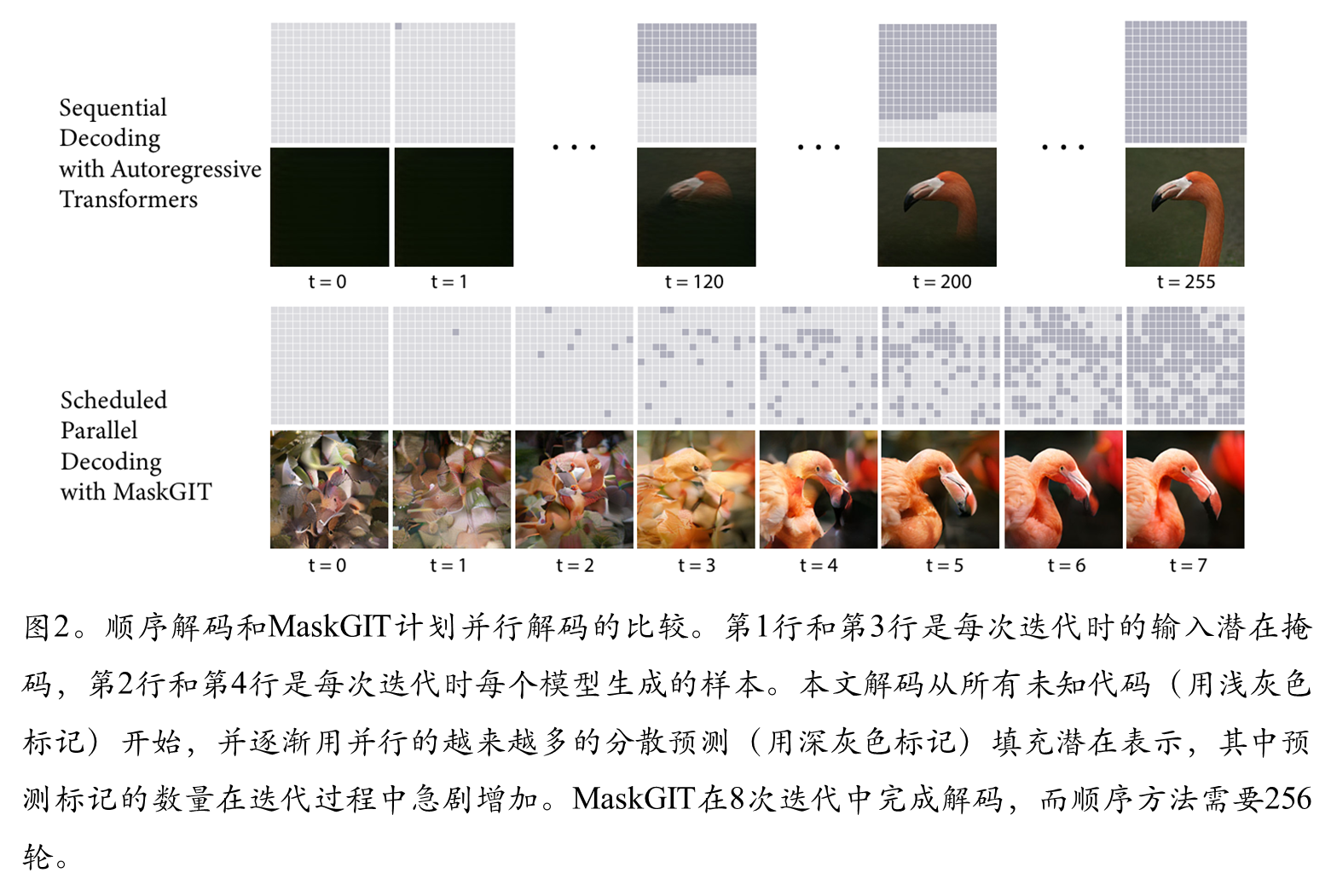
自回归和本文方法的生成比较
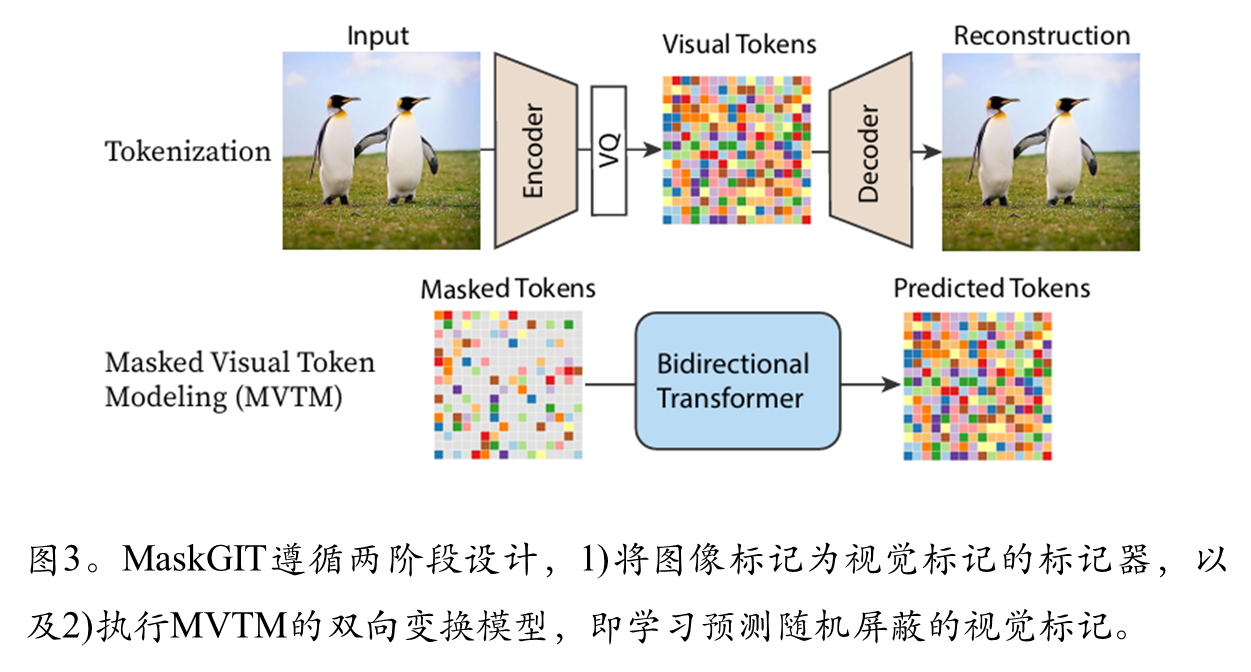
VQVAE生成图像的过程

MVTM训练流程

迭代式解码
在自回归解码中,标记是基于先前生成的输出依次生成的。由于图像标记长度(例如 256 或 1024)通常远大于语言标记长度,此过程无法并行,因而速度很慢。我们引入了一种新的解码方法,其中图像中的所有标记均可并行生成。这一点之所以可行,是因为模型具有双向自注意力机制。 本文模型能够单次推断并生成整个图像。发现,由于这与训练任务存在不一致,实现起来有挑战。提出的迭代解码方法。在推理时生成图像,从一张空白画布开始,即所有标记均被遮蔽(masked out),表示为 YM(0)。对于第 t次迭代,算法运行如下:

掩码的设计
图像生成的质量显著依赖于掩码调度函数γ(·)的设计。该函数决定了解码过程中每一步应遮蔽(mask)多少比例的标记,并需满足特定数学性质以适配迭代解码流程。
函数必须满足的性质:
实验结果
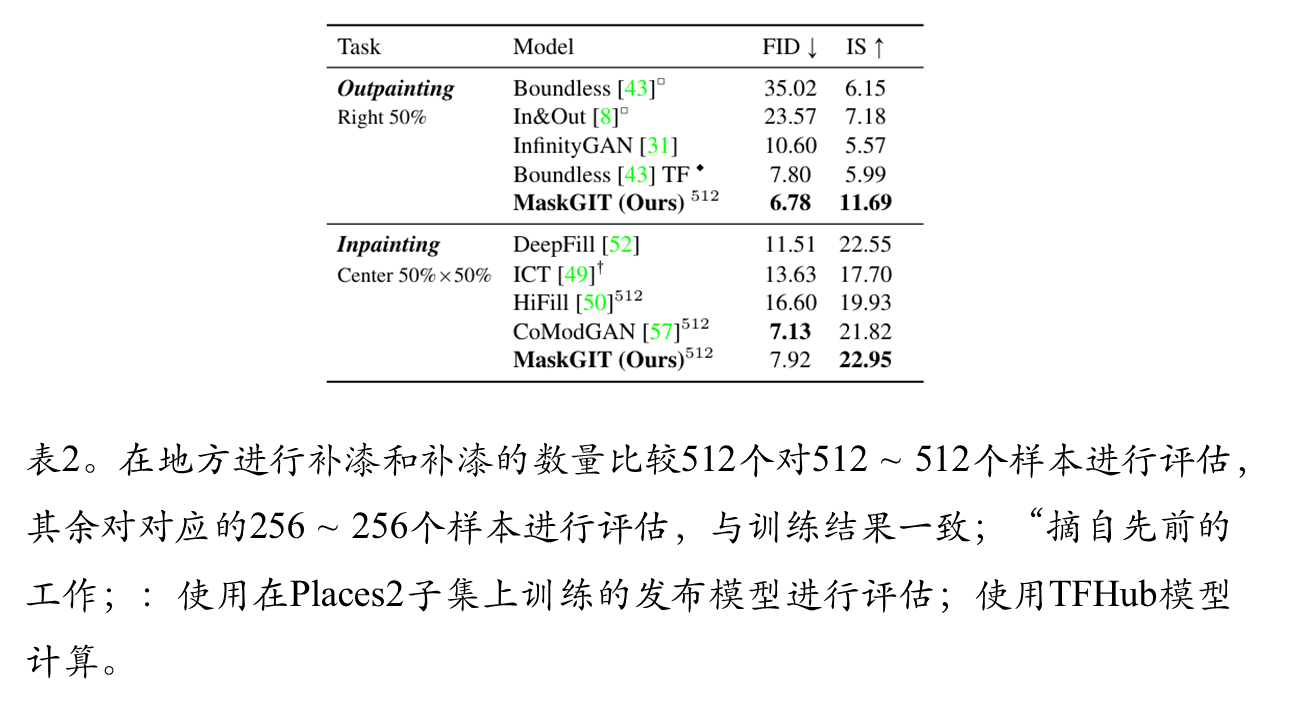
综合比较

消融实验
可视化结果




















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









